 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStackPlanner: A Centralized Hierarchical Multi-Agent System with Task-Experience Memory Management
Jan 09, 2026Multi-agent systems based on large language models, particularly centralized architectures, have recently shown strong potential for complex and knowledge-intensive tasks. However, central agents often suffer from unstable long-horizon collaboration due to the lack of memory management, leading to context bloat, error accumulation, and poor cross-task generalization. To address both task-level memory inefficiency and the inability to reuse coordination experience, we propose StackPlanner, a hierarchical multi-agent framework with explicit memory control. StackPlanner addresses these challenges by decoupling high-level coordination from subtask execution with active task-level memory control, and by learning to retrieve and exploit reusable coordination experience via structured experience memory and reinforcement learning. Experiments on multiple deep-search and agent system benchmarks demonstrate the effectiveness of our approach in enabling reliable long-horizon multi-agent collaboration.
Bridging Global Intent with Local Details: A Hierarchical Representation Approach for Semantic Validation in Text-to-SQL
Dec 28, 2025Text-to-SQL translates natural language questions into SQL statements grounded in a target database schema. Ensuring the reliability and executability of such systems requires validating generated SQL, but most existing approaches focus only on syntactic correctness, with few addressing semantic validation (detecting misalignments between questions and SQL). As a consequence, effective semantic validation still faces two key challenges: capturing both global user intent and SQL structural details, and constructing high-quality fine-grained sub-SQL annotations. To tackle these, we introduce HEROSQL, a hierarchical SQL representation approach that integrates global intent (via Logical Plans, LPs) and local details (via Abstract Syntax Trees, ASTs). To enable better information propagation, we employ a Nested Message Passing Neural Network (NMPNN) to capture inherent relational information in SQL and aggregate schema-guided semantics across LPs and ASTs. Additionally, to generate high-quality negative samples, we propose an AST-driven sub-SQL augmentation strategy, supporting robust optimization of fine-grained semantic inconsistencies. Extensive experiments conducted on Text-to-SQL validation benchmarks (both in-domain and out-of-domain settings) demonstrate that our approach outperforms existing state-of-the-art methods, achieving an average 9.40% improvement of AUPRC and 12.35% of AUROC in identifying semantic inconsistencies. It excels at detecting fine-grained semantic errors, provides large language models with more granular feedback, and ultimately enhances the reliability and interpretability of data querying platforms.
Task-Aware Retrieval Augmentation for Dynamic Recommendation
Nov 16, 2025Dynamic recommendation systems aim to provide personalized suggestions by modeling temporal user-item interactions across time-series behavioral data. Recent studies have leveraged pre-trained dynamic graph neural networks (GNNs) to learn user-item representations over temporal snapshot graphs. However, fine-tuning GNNs on these graphs often results in generalization issues due to temporal discrepancies between pre-training and fine-tuning stages, limiting the model's ability to capture evolving user preferences. To address this, we propose TarDGR, a task-aware retrieval-augmented framework designed to enhance generalization capability by incorporating task-aware model and retrieval-augmentation. Specifically, TarDGR introduces a Task-Aware Evaluation Mechanism to identify semantically relevant historical subgraphs, enabling the construction of task-specific datasets without manual labeling. It also presents a Graph Transformer-based Task-Aware Model that integrates semantic and structural encodings to assess subgraph relevance. During inference, TarDGR retrieves and fuses task-aware subgraphs with the query subgraph, enriching its representation and mitigating temporal generalization issues. Experiments on multiple large-scale dynamic graph datasets demonstrate that TarDGR consistently outperforms state-of-the-art methods, with extensive empirical evidence underscoring its superior accuracy and generalization capabilities.
STRAP: Spatio-Temporal Pattern Retrieval for Out-of-Distribution Generalization
May 26, 2025Spatio-Temporal Graph Neural Networks (STGNNs) have emerged as a powerful tool for modeling dynamic graph-structured data across diverse domains. However, they often fail to generalize in Spatio-Temporal Out-of-Distribution (STOOD) scenarios, where both temporal dynamics and spatial structures evolve beyond the training distribution. To address this problem, we propose an innovative Spatio-Temporal Retrieval-Augmented Pattern Learning framework,STRAP, which enhances model generalization by integrating retrieval-augmented learning into the STGNN continue learning pipeline. The core of STRAP is a compact and expressive pattern library that stores representative spatio-temporal patterns enriched with historical, structural, and semantic information, which is obtained and optimized during the training phase. During inference, STRAP retrieves relevant patterns from this library based on similarity to the current input and injects them into the model via a plug-and-play prompting mechanism. This not only strengthens spatio-temporal representations but also mitigates catastrophic forgetting. Moreover, STRAP introduces a knowledge-balancing objective to harmonize new information with retrieved knowledge. Extensive experiments across multiple real-world streaming graph datasets show that STRAP consistently outperforms state-of-the-art STGNN baselines on STOOD tasks, demonstrating its robustness, adaptability, and strong generalization capability without task-specific fine-tuning.
Efficient Large-Scale Traffic Forecasting with Transformers: A Spatial Data Management Perspective
Dec 13, 2024Road traffic forecasting is crucial in real-world intelligent transportation scenarios like traffic dispatching and path planning in city management and personal traveling. Spatio-temporal graph neural networks (STGNNs) stand out as the mainstream solution in this task. Nevertheless, the quadratic complexity of remarkable dynamic spatial modeling-based STGNNs has become the bottleneck over large-scale traffic data. From the spatial data management perspective, we present a novel Transformer framework called PatchSTG to efficiently and dynamically model spatial dependencies for large-scale traffic forecasting with interpretability and fidelity. Specifically, we design a novel irregular spatial patching to reduce the number of points involved in the dynamic calculation of Transformer. The irregular spatial patching first utilizes the leaf K-dimensional tree (KDTree) to recursively partition irregularly distributed traffic points into leaf nodes with a small capacity, and then merges leaf nodes belonging to the same subtree into occupancy-equaled and non-overlapped patches through padding and backtracking. Based on the patched data, depth and breadth attention are used interchangeably in the encoder to dynamically learn local and global spatial knowledge from points in a patch and points with the same index of patches. Experimental results on four real world large-scale traffic datasets show that our PatchSTG achieves train speed and memory utilization improvements up to $10\times$ and $4\times$ with the state-of-the-art performance.
RAGraph: A General Retrieval-Augmented Graph Learning Framework
Oct 31, 2024



Graph Neural Networks (GNNs) have become essential in interpreting relational data across various domains, yet, they often struggle to generalize to unseen graph data that differs markedly from training instances. In this paper, we introduce a novel framework called General Retrieval-Augmented Graph Learning (RAGraph), which brings external graph data into the general graph foundation model to improve model generalization on unseen scenarios. On the top of our framework is a toy graph vector library that we established, which captures key attributes, such as features and task-specific label information. During inference, the RAGraph adeptly retrieves similar toy graphs based on key similarities in downstream tasks, integrating the retrieved data to enrich the learning context via the message-passing prompting mechanism. Our extensive experimental evaluations demonstrate that RAGraph significantly outperforms state-of-the-art graph learning methods in multiple tasks such as node classification, link prediction, and graph classification across both dynamic and static datasets. Furthermore, extensive testing confirms that RAGraph consistently maintains high performance without the need for task-specific fine-tuning, highlighting its adaptability, robustness, and broad applicability.
Parenting: Optimizing Knowledge Selection of Retrieval-Augmented Language Models with Parameter Decoupling and Tailored Tuning
Oct 14, 2024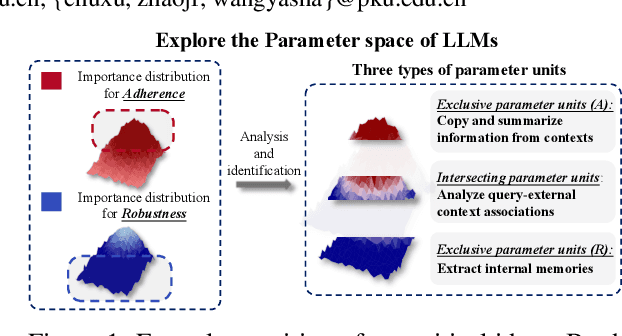
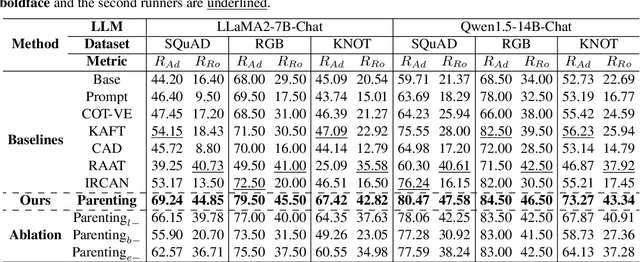
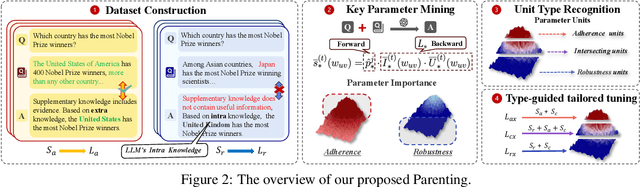
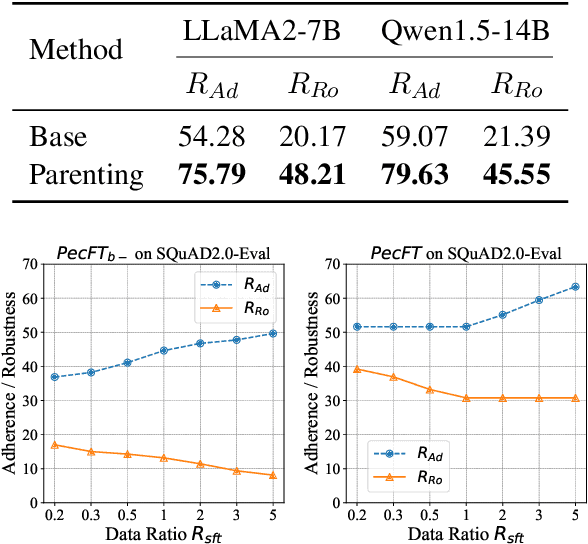
Retrieval-Augmented Generation (RAG) offers an effective solution to the issues faced by Large Language Models (LLMs) in hallucination generation and knowledge obsolescence by incorporating externally retrieved knowledge. However, due to potential conflicts between internal and external knowledge, as well as retrieval noise, LLMs often struggle to effectively integrate external evidence, leading to a decline in performance. Although existing methods attempt to tackle these challenges, they often struggle to strike a balance between model adherence and robustness, resulting in significant learning variance. Inspired by human cognitive processes, we propose Parenting, a novel framework that decouples adherence and robustness within the parameter space of LLMs. Specifically, Parenting utilizes a key parameter mining method based on forward activation gain to identify and isolate the crucial parameter units that are strongly linked to adherence and robustness. Then, Parenting employs a type-guided tailored tuning strategy, applying specific and appropriate fine-tuning methods to parameter units representing different capabilities, aiming to achieve a balanced enhancement of adherence and robustness. Extensive experiments on various datasets and models validate the effectiveness and generalizability of our methods.
3DS: Decomposed Difficulty Data Selection's Case Study on LLM Medical Domain Adaptation
Oct 13, 2024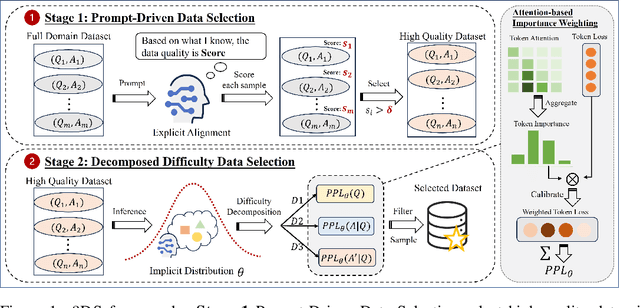
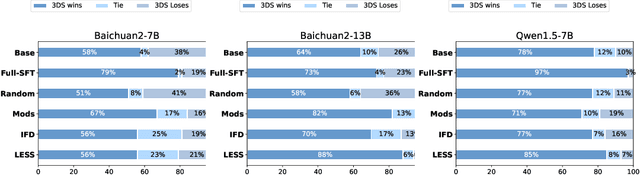
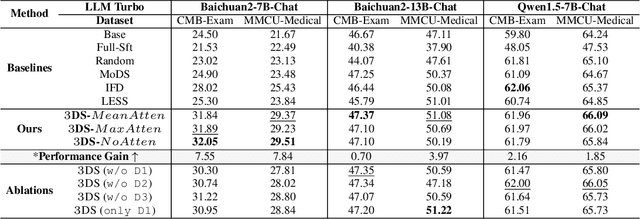
Large Language Models(LLMs) excel in general tasks but struggle in specialized domains like healthcare due to limited domain-specific knowledge.Supervised Fine-Tuning(SFT) data construction for domain adaptation often relies on heuristic methods, such as GPT-4 annotation or manual data selection, with a data-centric focus on presumed diverse, high-quality datasets. However, these methods overlook the model's inherent knowledge distribution, introducing noise, redundancy, and irrelevant data, leading to a mismatch between the selected data and the model's learning task, resulting in suboptimal performance. To address this, we propose a two-stage model-centric data selection framework, Decomposed Difficulty Data Selection (3DS), which aligns data with the model's knowledge distribution for optimized adaptation. In Stage1, we apply Prompt-Driven Data Selection via Explicit Alignment, where the the model filters irrelevant or redundant data based on its internal knowledge. In Stage2, we perform Decomposed Difficulty Data Selection, where data selection is guided by our defined difficulty decomposition, using three metrics: Instruction Understanding, Response Confidence, and Response Correctness. Additionally, an attention-based importance weighting mechanism captures token importance for more accurate difficulty calibration. This two-stage approach ensures the selected data is not only aligned with the model's knowledge and preferences but also appropriately challenging for the model to learn, leading to more effective and targeted domain adaptation. In the case study of the medical domain, our extensive experiments on real-world healthcare datasets demonstrate the superiority of 3DS over exisiting methods in accuracy by over 5.29%. Our dataset and code will be open-sourced at https://anonymous.4open.science/r/3DS-E67F.
KnowPO: Knowledge-aware Preference Optimization for Controllable Knowledge Selection in Retrieval-Augmented Language Models
Aug 19, 2024

By integrating external knowledge, Retrieval-Augmented Generation (RAG) has become an effective strategy for mitigating the hallucination problems that large language models (LLMs) encounter when dealing with knowledge-intensive tasks. However, in the process of integrating external non-parametric supporting evidence with internal parametric knowledge, inevitable knowledge conflicts may arise, leading to confusion in the model's responses. To enhance the knowledge selection of LLMs in various contexts, some research has focused on refining their behavior patterns through instruction-tuning. Nonetheless, due to the absence of explicit negative signals and comparative objectives, models fine-tuned in this manner may still exhibit undesirable behaviors such as contextual ignorance and contextual overinclusion. To this end, we propose a Knowledge-aware Preference Optimization strategy, dubbed KnowPO, aimed at achieving adaptive knowledge selection based on contextual relevance in real retrieval scenarios. Concretely, we proposed a general paradigm for constructing knowledge conflict datasets, which comprehensively cover various error types and learn how to avoid these negative signals through preference optimization methods. Simultaneously, we proposed a rewriting strategy and data ratio optimization strategy to address preference imbalances. Experimental results show that KnowPO outperforms previous methods for handling knowledge conflicts by over 37\%, while also exhibiting robust generalization across various out-of-distribution datasets.
TC-RAG:Turing-Complete RAG's Case study on Medical LLM Systems
Aug 17, 2024



In the pursuit of enhancing domain-specific Large Language Models (LLMs), Retrieval-Augmented Generation (RAG) emerges as a promising solution to mitigate issues such as hallucinations, outdated knowledge, and limited expertise in highly specialized queries. However, existing approaches to RAG fall short by neglecting system state variables, which are crucial for ensuring adaptive control, retrieval halting, and system convergence. In this paper, we introduce the TC-RAG through rigorous proof, a novel framework that addresses these challenges by incorporating a Turing Complete System to manage state variables, thereby enabling more efficient and accurate knowledge retrieval. By leveraging a memory stack system with adaptive retrieval, reasoning, and planning capabilities, TC-RAG not only ensures the controlled halting of retrieval processes but also mitigates the accumulation of erroneous knowledge via Push and Pop actions. In the case study of the medical domain, our extensive experiments on real-world healthcare datasets demonstrate the superiority of TC-RAG over existing methods in accuracy by over 7.20\%. Our dataset and code have been available at https://https://github.com/Artessay/SAMA.git.