 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugmenting Clinical Decision-Making with an Interactive and Interpretable AI Copilot: A Real-World User Study with Clinicians in Nephrology and Obstetrics
Jan 31, 2026Clinician skepticism toward opaque AI hinders adoption in high-stakes healthcare. We present AICare, an interactive and interpretable AI copilot for collaborative clinical decision-making. By analyzing longitudinal electronic health records, AICare grounds dynamic risk predictions in scrutable visualizations and LLM-driven diagnostic recommendations. Through a within-subjects counterbalanced study with 16 clinicians across nephrology and obstetrics, we comprehensively evaluated AICare using objective measures (task completion time and error rate), subjective assessments (NASA-TLX, SUS, and confidence ratings), and semi-structured interviews. Our findings indicate AICare's reduced cognitive workload. Beyond performance metrics, qualitative analysis reveals that trust is actively constructed through verification, with interaction strategies diverging by expertise: junior clinicians used the system as cognitive scaffolding to structure their analysis, while experts engaged in adversarial verification to challenge the AI's logic. This work offers design implications for creating AI systems that function as transparent partners, accommodating diverse reasoning styles to augment rather than replace clinical judgment.
StackPlanner: A Centralized Hierarchical Multi-Agent System with Task-Experience Memory Management
Jan 09, 2026Multi-agent systems based on large language models, particularly centralized architectures, have recently shown strong potential for complex and knowledge-intensive tasks. However, central agents often suffer from unstable long-horizon collaboration due to the lack of memory management, leading to context bloat, error accumulation, and poor cross-task generalization. To address both task-level memory inefficiency and the inability to reuse coordination experience, we propose StackPlanner, a hierarchical multi-agent framework with explicit memory control. StackPlanner addresses these challenges by decoupling high-level coordination from subtask execution with active task-level memory control, and by learning to retrieve and exploit reusable coordination experience via structured experience memory and reinforcement learning. Experiments on multiple deep-search and agent system benchmarks demonstrate the effectiveness of our approach in enabling reliable long-horizon multi-agent collaboration.
FOREVER: Forgetting Curve-Inspired Memory Replay for Language Model Continual Learning
Jan 07, 2026Continual learning (CL) for large language models (LLMs) aims to enable sequential knowledge acquisition without catastrophic forgetting. Memory replay methods are widely used for their practicality and effectiveness, but most rely on fixed, step-based heuristics that often misalign with the model's actual learning progress, since identical training steps can result in varying degrees of parameter change. Motivated by recent findings that LLM forgetting mirrors the Ebbinghaus human forgetting curve, we propose FOREVER (FORgEtting curVe-inspired mEmory Replay), a novel CL framework that aligns replay schedules with a model-centric notion of time. FOREVER defines model time using the magnitude of optimizer updates, allowing forgetting curve-inspired replay intervals to align with the model's internal evolution rather than raw training steps. Building on this approach, FOREVER incorporates a forgetting curve-based replay scheduler to determine when to replay and an intensity-aware regularization mechanism to adaptively control how to replay. Extensive experiments on three CL benchmarks and models ranging from 0.6B to 13B parameters demonstrate that FOREVER consistently mitigates catastrophic forgetting.
Bridging Global Intent with Local Details: A Hierarchical Representation Approach for Semantic Validation in Text-to-SQL
Dec 28, 2025Text-to-SQL translates natural language questions into SQL statements grounded in a target database schema. Ensuring the reliability and executability of such systems requires validating generated SQL, but most existing approaches focus only on syntactic correctness, with few addressing semantic validation (detecting misalignments between questions and SQL). As a consequence, effective semantic validation still faces two key challenges: capturing both global user intent and SQL structural details, and constructing high-quality fine-grained sub-SQL annotations. To tackle these, we introduce HEROSQL, a hierarchical SQL representation approach that integrates global intent (via Logical Plans, LPs) and local details (via Abstract Syntax Trees, ASTs). To enable better information propagation, we employ a Nested Message Passing Neural Network (NMPNN) to capture inherent relational information in SQL and aggregate schema-guided semantics across LPs and ASTs. Additionally, to generate high-quality negative samples, we propose an AST-driven sub-SQL augmentation strategy, supporting robust optimization of fine-grained semantic inconsistencies. Extensive experiments conducted on Text-to-SQL validation benchmarks (both in-domain and out-of-domain settings) demonstrate that our approach outperforms existing state-of-the-art methods, achieving an average 9.40% improvement of AUPRC and 12.35% of AUROC in identifying semantic inconsistencies. It excels at detecting fine-grained semantic errors, provides large language models with more granular feedback, and ultimately enhances the reliability and interpretability of data querying platforms.
Magical: Medical Lay Language Generation via Semantic Invariance and Layperson-tailored Adaptation
Aug 12, 2025
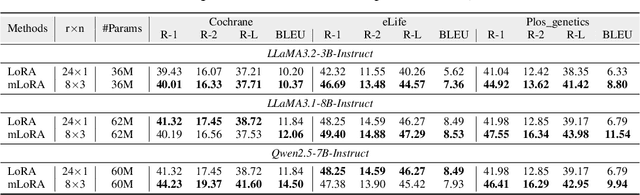
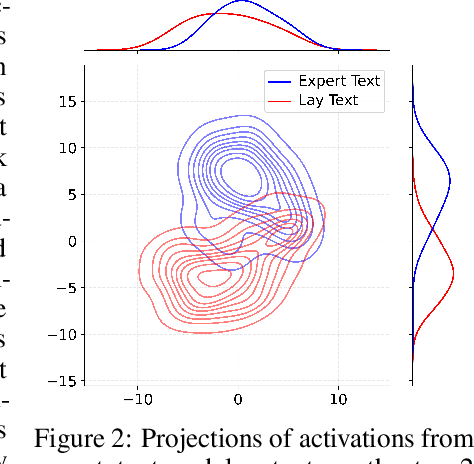
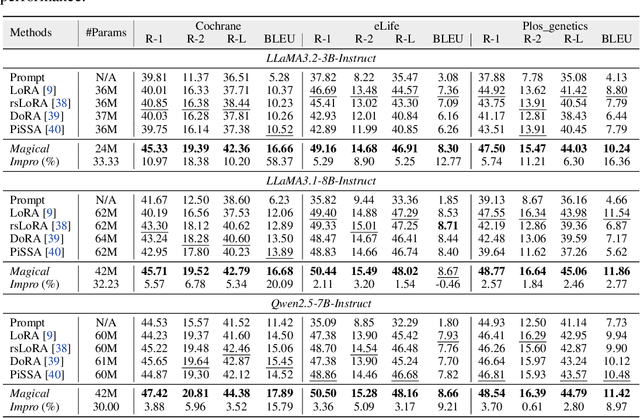
Medical Lay Language Generation (MLLG) plays a vital role in improving the accessibility of complex scientific content for broader audiences. Recent literature to MLLG commonly employ parameter-efficient fine-tuning methods such as Low-Rank Adaptation (LoRA) to fine-tuning large language models (LLMs) using paired expert-lay language datasets. However, LoRA struggles with the challenges posed by multi-source heterogeneous MLLG datasets. Specifically, through a series of exploratory experiments, we reveal that standard LoRA fail to meet the requirement for semantic fidelity and diverse lay-style generation in MLLG task. To address these limitations, we propose Magical, an asymmetric LoRA architecture tailored for MLLG under heterogeneous data scenarios. Magical employs a shared matrix $A$ for abstractive summarization, along with multiple isolated matrices $B$ for diverse lay-style generation. To preserve semantic fidelity during the lay language generation process, Magical introduces a Semantic Invariance Constraint to mitigate semantic subspace shifts on matrix $A$. Furthermore, to better adapt to diverse lay-style generation, Magical incorporates the Recommendation-guided Switch, an externally interface to prompt the LLM to switch between different matrices $B$. Experimental results on three real-world lay language generation datasets demonstrate that Magical consistently outperforms prompt-based methods, vanilla LoRA, and its recent variants, while also reducing trainable parameters by 31.66%.
ConfAgents: A Conformal-Guided Multi-Agent Framework for Cost-Efficient Medical Diagnosis
Aug 06, 2025



The efficacy of AI agents in healthcare research is hindered by their reliance on static, predefined strategies. This creates a critical limitation: agents can become better tool-users but cannot learn to become better strategic planners, a crucial skill for complex domains like healthcare. We introduce HealthFlow, a self-evolving AI agent that overcomes this limitation through a novel meta-level evolution mechanism. HealthFlow autonomously refines its own high-level problem-solving policies by distilling procedural successes and failures into a durable, strategic knowledge base. To anchor our research and facilitate reproducible evaluation, we introduce EHRFlowBench, a new benchmark featuring complex, realistic health data analysis tasks derived from peer-reviewed clinical research. Our comprehensive experiments demonstrate that HealthFlow's self-evolving approach significantly outperforms state-of-the-art agent frameworks. This work marks a necessary shift from building better tool-users to designing smarter, self-evolving task-managers, paving the way for more autonomous and effective AI for scientific discovery.
LearNAT: Learning NL2SQL with AST-guided Task Decomposition for Large Language Models
Apr 03, 2025Natural Language to SQL (NL2SQL) has emerged as a critical task for enabling seamless interaction with databases. Recent advancements in Large Language Models (LLMs) have demonstrated remarkable performance in this domain. However, existing NL2SQL methods predominantly rely on closed-source LLMs leveraging prompt engineering, while open-source models typically require fine-tuning to acquire domain-specific knowledge. Despite these efforts, open-source LLMs struggle with complex NL2SQL tasks due to the indirect expression of user query objectives and the semantic gap between user queries and database schemas. Inspired by the application of reinforcement learning in mathematical problem-solving to encourage step-by-step reasoning in LLMs, we propose LearNAT (Learning NL2SQL with AST-guided Task Decomposition), a novel framework that improves the performance of open-source LLMs on complex NL2SQL tasks through task decomposition and reinforcement learning. LearNAT introduces three key components: (1) a Decomposition Synthesis Procedure that leverages Abstract Syntax Trees (ASTs) to guide efficient search and pruning strategies for task decomposition, (2) Margin-aware Reinforcement Learning, which employs fine-grained step-level optimization via DPO with AST margins, and (3) Adaptive Demonstration Reasoning, a mechanism for dynamically selecting relevant examples to enhance decomposition capabilities. Extensive experiments on two benchmark datasets, Spider and BIRD, demonstrate that LearNAT enables a 7B-parameter open-source LLM to achieve performance comparable to GPT-4, while offering improved efficiency and accessibility.
GeoEdit: Geometric Knowledge Editing for Large Language Models
Feb 27, 2025Regular updates are essential for maintaining up-to-date knowledge in large language models (LLMs). Consequently, various model editing methods have been developed to update specific knowledge within LLMs. However, training-based approaches often struggle to effectively incorporate new knowledge while preserving unrelated general knowledge. To address this challenge, we propose a novel framework called Geometric Knowledge Editing (GeoEdit). GeoEdit utilizes the geometric relationships of parameter updates from fine-tuning to differentiate between neurons associated with new knowledge updates and those related to general knowledge perturbations. By employing a direction-aware knowledge identification method, we avoid updating neurons with directions approximately orthogonal to existing knowledge, thus preserving the model's generalization ability. For the remaining neurons, we integrate both old and new knowledge for aligned directions and apply a "forget-then-learn" editing strategy for opposite directions. Additionally, we introduce an importance-guided task vector fusion technique that filters out redundant information and provides adaptive neuron-level weighting, further enhancing model editing performance. Extensive experiments on two publicly available datasets demonstrate the superiority of GeoEdit over existing state-of-the-art methods.
Recurrent Knowledge Identification and Fusion for Language Model Continual Learning
Feb 22, 2025Continual learning (CL) is crucial for deploying large language models (LLMs) in dynamic real-world environments without costly retraining. While recent model ensemble and model merging methods guided by parameter importance have gained popularity, they often struggle to balance knowledge transfer and forgetting, mainly due to the reliance on static importance estimates during sequential training. In this paper, we present Recurrent-KIF, a novel CL framework for Recurrent Knowledge Identification and Fusion, which enables dynamic estimation of parameter importance distributions to enhance knowledge transfer. Inspired by human continual learning, Recurrent-KIF employs an inner loop that rapidly adapts to new tasks while identifying important parameters, coupled with an outer loop that globally manages the fusion of new and historical knowledge through redundant knowledge pruning and key knowledge merging. These inner-outer loops iteratively perform multiple rounds of fusion, allowing Recurrent-KIF to leverage intermediate training information and adaptively adjust fusion strategies based on evolving importance distributions. Extensive experiments on two CL benchmarks with various model sizes (from 770M to 13B) demonstrate that Recurrent-KIF effectively mitigates catastrophic forgetting and enhances knowledge transfer.
DRESSing Up LLM: Efficient Stylized Question-Answering via Style Subspace Editing
Jan 24, 2025We introduce DRESS, a novel approach for generating stylized large language model (LLM) responses through representation editing. Existing methods like prompting and fine-tuning are either insufficient for complex style adaptation or computationally expensive, particularly in tasks like NPC creation or character role-playing. Our approach leverages the over-parameterized nature of LLMs to disentangle a style-relevant subspace within the model's representation space to conduct representation editing, ensuring a minimal impact on the original semantics. By applying adaptive editing strengths, we dynamically adjust the steering vectors in the style subspace to maintain both stylistic fidelity and semantic integrity. We develop two stylized QA benchmark datasets to validate the effectiveness of DRESS, and the results demonstrate significant improvements compared to baseline methods such as prompting and ITI. In short, DRESS is a lightweight, train-free solution for enhancing LLMs with flexible and effective style control, making it particularly useful for developing stylized conversational agents. Codes and benchmark datasets are available at https://github.com/ArthurLeoM/DRESS-LLM.