 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntuitive control of supernumerary robotic limbs through a tactile-encoded neural interface
Nov 11, 2025



Brain-computer interfaces (BCIs) promise to extend human movement capabilities by enabling direct neural control of supernumerary effectors, yet integrating augmented commands with multiple degrees of freedom without disrupting natural movement remains a key challenge. Here, we propose a tactile-encoded BCI that leverages sensory afferents through a novel tactile-evoked P300 paradigm, allowing intuitive and reliable decoding of supernumerary motor intentions even when superimposed with voluntary actions. The interface was evaluated in a multi-day experiment comprising of a single motor recognition task to validate baseline BCI performance and a dual task paradigm to assess the potential influence between the BCI and natural human movement. The brain interface achieved real-time and reliable decoding of four supernumerary degrees of freedom, with significant performance improvements after only three days of training. Importantly, after training, performance did not differ significantly between the single- and dual-BCI task conditions, and natural movement remained unimpaired during concurrent supernumerary control. Lastly, the interface was deployed in a movement augmentation task, demonstrating its ability to command two supernumerary robotic arms for functional assistance during bimanual tasks. These results establish a new neural interface paradigm for movement augmentation through stimulation of sensory afferents, expanding motor degrees of freedom without impairing natural movement.
LearNAT: Learning NL2SQL with AST-guided Task Decomposition for Large Language Models
Apr 03, 2025Natural Language to SQL (NL2SQL) has emerged as a critical task for enabling seamless interaction with databases. Recent advancements in Large Language Models (LLMs) have demonstrated remarkable performance in this domain. However, existing NL2SQL methods predominantly rely on closed-source LLMs leveraging prompt engineering, while open-source models typically require fine-tuning to acquire domain-specific knowledge. Despite these efforts, open-source LLMs struggle with complex NL2SQL tasks due to the indirect expression of user query objectives and the semantic gap between user queries and database schemas. Inspired by the application of reinforcement learning in mathematical problem-solving to encourage step-by-step reasoning in LLMs, we propose LearNAT (Learning NL2SQL with AST-guided Task Decomposition), a novel framework that improves the performance of open-source LLMs on complex NL2SQL tasks through task decomposition and reinforcement learning. LearNAT introduces three key components: (1) a Decomposition Synthesis Procedure that leverages Abstract Syntax Trees (ASTs) to guide efficient search and pruning strategies for task decomposition, (2) Margin-aware Reinforcement Learning, which employs fine-grained step-level optimization via DPO with AST margins, and (3) Adaptive Demonstration Reasoning, a mechanism for dynamically selecting relevant examples to enhance decomposition capabilities. Extensive experiments on two benchmark datasets, Spider and BIRD, demonstrate that LearNAT enables a 7B-parameter open-source LLM to achieve performance comparable to GPT-4, while offering improved efficiency and accessibility.
Lightweight Channel-wise Dynamic Fusion Model: Non-stationary Time Series Forecasting via Entropy Analysis
Mar 04, 2025Non-stationarity is an intrinsic property of real-world time series and plays a crucial role in time series forecasting. Previous studies primarily adopt instance normalization to attenuate the non-stationarity of original series for better predictability. However, instance normalization that directly removes the inherent non-stationarity can lead to three issues: (1) disrupting global temporal dependencies, (2) ignoring channel-specific differences, and (3) producing over-smoothed predictions. To address these issues, we theoretically demonstrate that variance can be a valid and interpretable proxy for quantifying non-stationarity of time series. Based on the analysis, we propose a novel lightweight \textit{C}hannel-wise \textit{D}ynamic \textit{F}usion \textit{M}odel (\textit{CDFM}), which selectively and dynamically recovers intrinsic non-stationarity of the original series, while keeping the predictability of normalized series. First, we design a Dual-Predictor Module, which involves two branches: a Time Stationary Predictor for capturing stable patterns and a Time Non-stationary Predictor for modeling global dynamics patterns. Second, we propose a Fusion Weight Learner to dynamically characterize the intrinsic non-stationary information across different samples based on variance. Finally, we introduce a Channel Selector to selectively recover non-stationary information from specific channels by evaluating their non-stationarity, similarity, and distribution consistency, enabling the model to capture relevant dynamic features and avoid overfitting. Comprehensive experiments on seven time series datasets demonstrate the superiority and generalization capabilities of CDFM.
Stackelberg Game Preference Optimization for Data-Efficient Alignment of Language Models
Feb 25, 2025Aligning language models with human preferences is critical for real-world deployment, but existing methods often require large amounts of high-quality human annotations. Aiming at a data-efficient alignment method, we propose Stackelberg Game Preference Optimization (SGPO), a framework that models alignment as a two-player Stackelberg game, where a policy (leader) optimizes against a worst-case preference distribution (follower) within an $\epsilon$-Wasserstein ball, ensuring robustness to (self-)annotation noise and distribution shifts. SGPO guarantees $O(\epsilon)$-bounded regret, unlike Direct Preference Optimization (DPO), which suffers from linear regret growth in the distribution mismatch. We instantiate SGPO with the Stackelberg Self-Annotated Preference Optimization (SSAPO) algorithm, which iteratively self-annotates preferences and adversarially reweights synthetic annotated preferences. Using only 2K seed preferences, from the UltraFeedback dataset, i.e., 1/30 of human labels in the dataset, our method achieves 35.82% GPT-4 win-rate with Mistral-7B and 40.12% with Llama3-8B-Instruct within three rounds of SSAPO.
OMU: A Probabilistic 3D Occupancy Mapping Accelerator for Real-time OctoMap at the Edge
May 06, 2022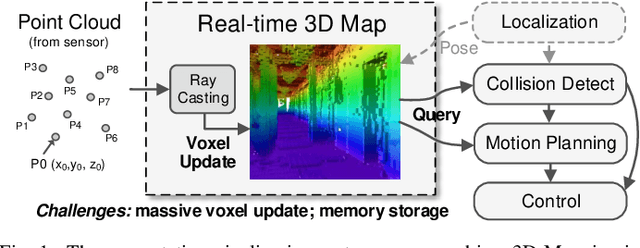
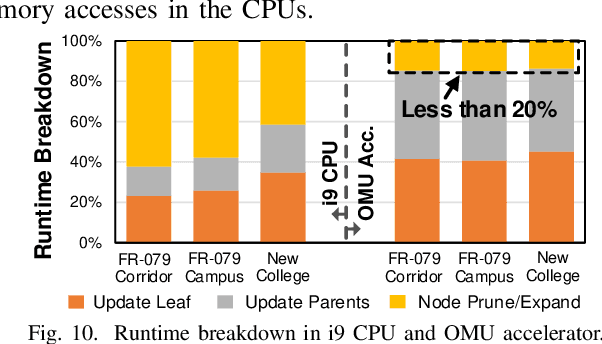
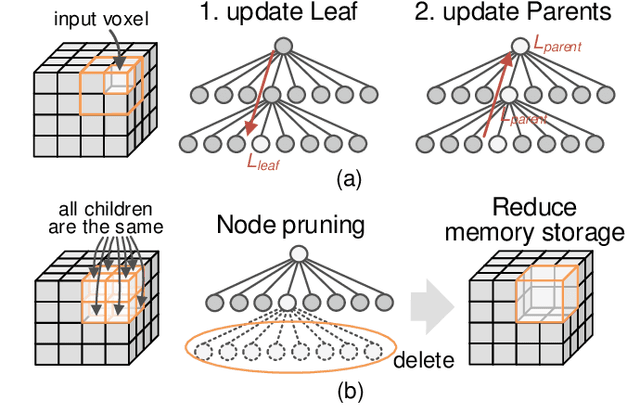
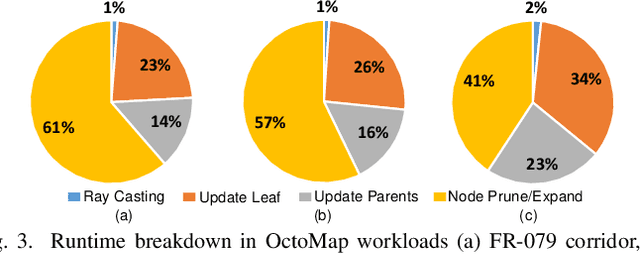
Autonomous machines (e.g., vehicles, mobile robots, drones) require sophisticated 3D mapping to perceive the dynamic environment. However, maintaining a real-time 3D map is expensive both in terms of compute and memory requirements, especially for resource-constrained edge machines. Probabilistic OctoMap is a reliable and memory-efficient 3D dense map model to represent the full environment, with dynamic voxel node pruning and expansion capacity. This paper presents the first efficient accelerator solution, i.e. OMU, to enable real-time probabilistic 3D mapping at the edge. To improve the performance, the input map voxels are updated via parallel PE units for data parallelism. Within each PE, the voxels are stored using a specially developed data structure in parallel memory banks. In addition, a pruning address manager is designed within each PE unit to reuse the pruned memory addresses. The proposed 3D mapping accelerator is implemented and evaluated using a commercial 12 nm technology. Compared to the ARM Cortex-A57 CPU in the Nvidia Jetson TX2 platform, the proposed accelerator achieves up to 62$\times$ performance and 708$\times$ energy efficiency improvement. Furthermore, the accelerator provides 63 FPS throughput, more than 2$\times$ higher than a real-time requirement, enabling real-time perception for 3D mapping.
FRL-FI: Transient Fault Analysis for Federated Reinforcement Learning-Based Navigation Systems
Mar 14, 2022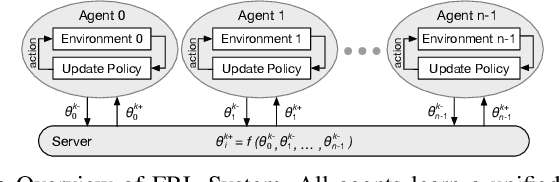
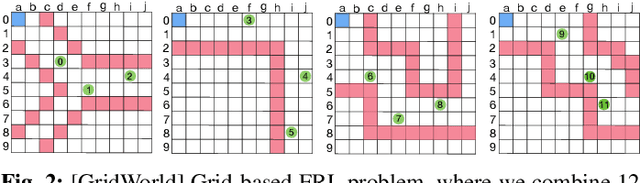

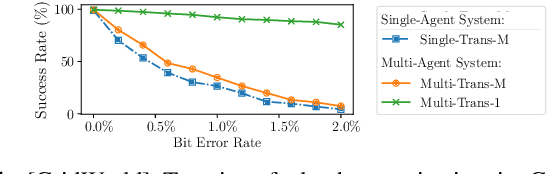
Swarm intelligence is being increasingly deployed in autonomous systems, such as drones and unmanned vehicles. Federated reinforcement learning (FRL), a key swarm intelligence paradigm where agents interact with their own environments and cooperatively learn a consensus policy while preserving privacy, has recently shown potential advantages and gained popularity. However, transient faults are increasing in the hardware system with continuous technology node scaling and can pose threats to FRL systems. Meanwhile, conventional redundancy-based protection methods are challenging to deploy on resource-constrained edge applications. In this paper, we experimentally evaluate the fault tolerance of FRL navigation systems at various scales with respect to fault models, fault locations, learning algorithms, layer types, communication intervals, and data types at both training and inference stages. We further propose two cost-effective fault detection and recovery techniques that can achieve up to 3.3x improvement in resilience with <2.7% overhead in FRL systems.
Analyzing and Improving Fault Tolerance of Learning-Based Navigation Systems
Nov 09, 2021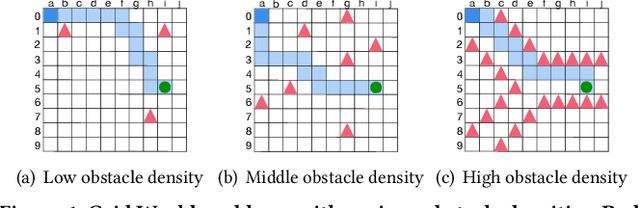
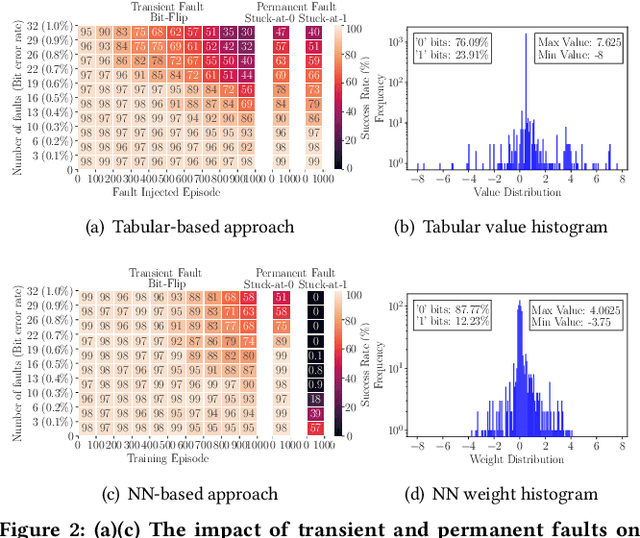
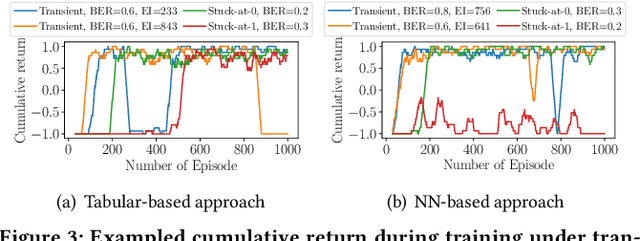
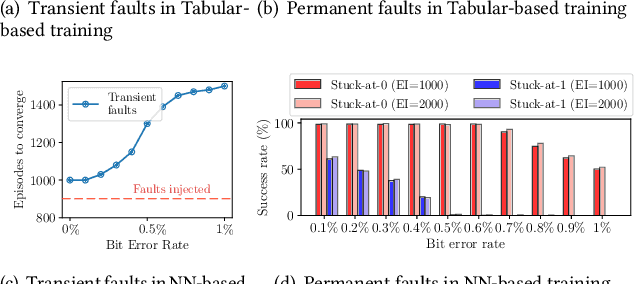
Learning-based navigation systems are widely used in autonomous applications, such as robotics, unmanned vehicles and drones. Specialized hardware accelerators have been proposed for high-performance and energy-efficiency for such navigational tasks. However, transient and permanent faults are increasing in hardware systems and can catastrophically violate tasks safety. Meanwhile, traditional redundancy-based protection methods are challenging to deploy on resource-constrained edge applications. In this paper, we experimentally evaluate the resilience of navigation systems with respect to algorithms, fault models and data types from both RL training and inference. We further propose two efficient fault mitigation techniques that achieve 2x success rate and 39% quality-of-flight improvement in learning-based navigation systems.
MAVFI: An End-to-End Fault Analysis Framework with Anomaly Detection and Recovery for Micro Aerial Vehicles
May 27, 2021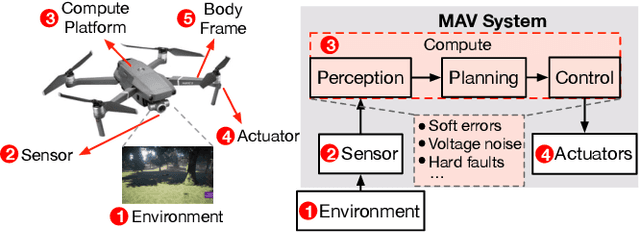

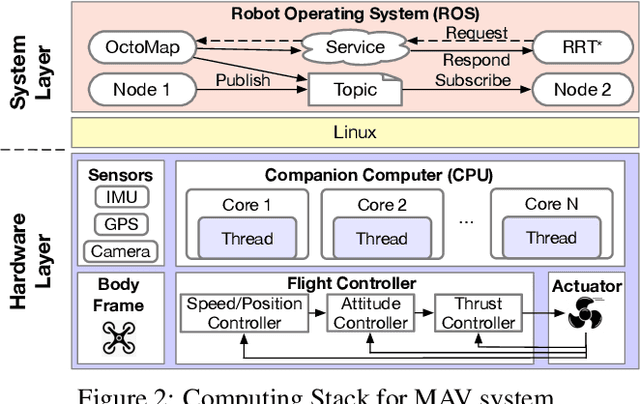
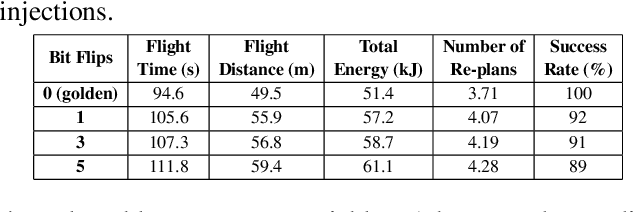
Reliability and safety are critical in autonomous machine services, such as autonomous vehicles and aerial drones. In this paper, we first present an open-source Micro Aerial Vehicles (MAVs) reliability analysis framework, MAVFI, to characterize transient fault's impacts on the end-to-end flight metrics, e.g., flight time, success rate. Based on our framework, it is observed that the end-to-end fault tolerance analysis is essential for characterizing system reliability. We demonstrate the planning and control stages are more vulnerable to transient faults than the visual perception stage in the common "Perception-Planning-Control (PPC)" compute pipeline. Furthermore, to improve the reliability of the MAV system, we propose two low overhead anomaly-based transient fault detection and recovery schemes based on Gaussian statistical models and autoencoder neural networks. We validate our anomaly fault protection schemes with a variety of simulated photo-realistic environments on both Intel i9 CPU and ARM Cortex-A57 on Nvidia TX2 platform. It is demonstrated that the autoencoder-based scheme can improve the system reliability by 100% recovering failure cases with less than 0.0062% computational overhead in best-case scenarios. In addition, MAVFI framework can be used for other ROS-based cyber-physical applications and is open-sourced at https://github.com/harvard-edge/MAVBench/tree/mavfi