 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugmented Reality based Simulated Data (ARSim) with multi-view consistency for AV perception networks
Mar 22, 2024



Detecting a diverse range of objects under various driving scenarios is essential for the effectiveness of autonomous driving systems. However, the real-world data collected often lacks the necessary diversity presenting a long-tail distribution. Although synthetic data has been utilized to overcome this issue by generating virtual scenes, it faces hurdles such as a significant domain gap and the substantial efforts required from 3D artists to create realistic environments. To overcome these challenges, we present ARSim, a fully automated, comprehensive, modular framework designed to enhance real multi-view image data with 3D synthetic objects of interest. The proposed method integrates domain adaptation and randomization strategies to address covariate shift between real and simulated data by inferring essential domain attributes from real data and employing simulation-based randomization for other attributes. We construct a simplified virtual scene using real data and strategically place 3D synthetic assets within it. Illumination is achieved by estimating light distribution from multiple images capturing the surroundings of the vehicle. Camera parameters from real data are employed to render synthetic assets in each frame. The resulting augmented multi-view consistent dataset is used to train a multi-camera perception network for autonomous vehicles. Experimental results on various AV perception tasks demonstrate the superior performance of networks trained on the augmented dataset.
FRL-FI: Transient Fault Analysis for Federated Reinforcement Learning-Based Navigation Systems
Mar 14, 2022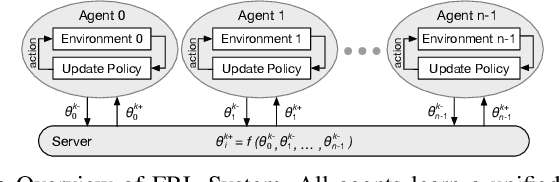
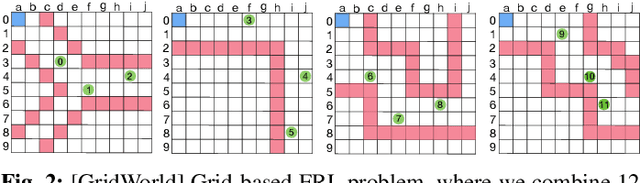

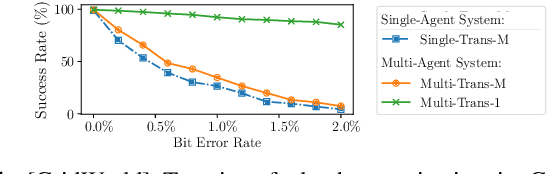
Swarm intelligence is being increasingly deployed in autonomous systems, such as drones and unmanned vehicles. Federated reinforcement learning (FRL), a key swarm intelligence paradigm where agents interact with their own environments and cooperatively learn a consensus policy while preserving privacy, has recently shown potential advantages and gained popularity. However, transient faults are increasing in the hardware system with continuous technology node scaling and can pose threats to FRL systems. Meanwhile, conventional redundancy-based protection methods are challenging to deploy on resource-constrained edge applications. In this paper, we experimentally evaluate the fault tolerance of FRL navigation systems at various scales with respect to fault models, fault locations, learning algorithms, layer types, communication intervals, and data types at both training and inference stages. We further propose two cost-effective fault detection and recovery techniques that can achieve up to 3.3x improvement in resilience with <2.7% overhead in FRL systems.
Analyzing and Improving Fault Tolerance of Learning-Based Navigation Systems
Nov 09, 2021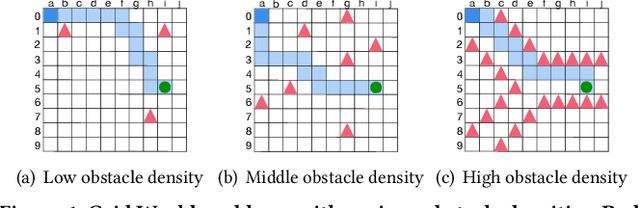
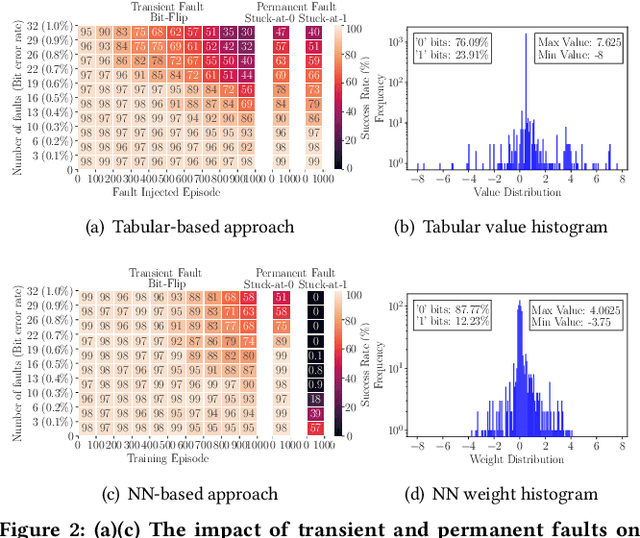
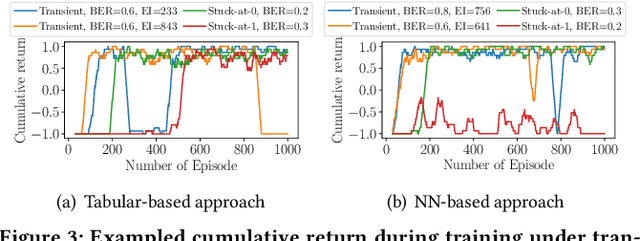
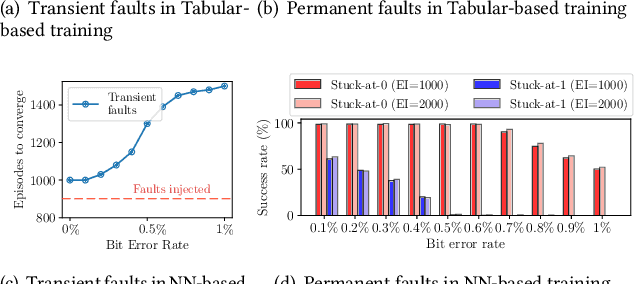
Learning-based navigation systems are widely used in autonomous applications, such as robotics, unmanned vehicles and drones. Specialized hardware accelerators have been proposed for high-performance and energy-efficiency for such navigational tasks. However, transient and permanent faults are increasing in hardware systems and can catastrophically violate tasks safety. Meanwhile, traditional redundancy-based protection methods are challenging to deploy on resource-constrained edge applications. In this paper, we experimentally evaluate the resilience of navigation systems with respect to algorithms, fault models and data types from both RL training and inference. We further propose two efficient fault mitigation techniques that achieve 2x success rate and 39% quality-of-flight improvement in learning-based navigation systems.
Multi-Task Federated Reinforcement Learning with Adversaries
Mar 11, 2021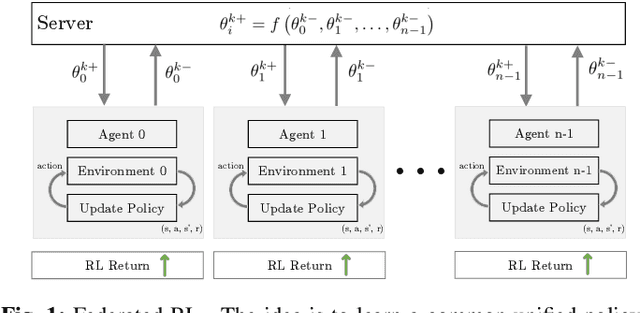
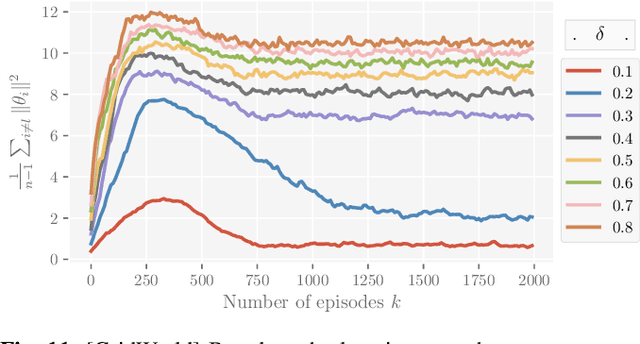
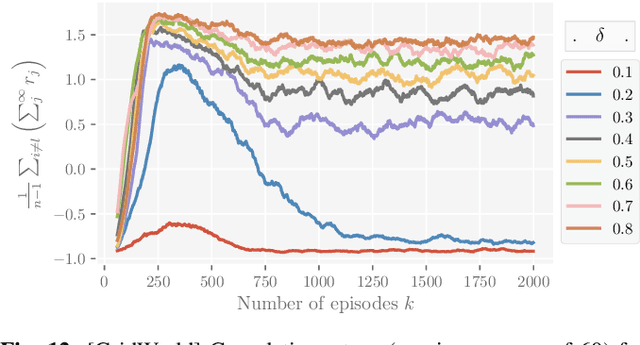
Reinforcement learning algorithms, just like any other Machine learning algorithm pose a serious threat from adversaries. The adversaries can manipulate the learning algorithm resulting in non-optimal policies. In this paper, we analyze the Multi-task Federated Reinforcement Learning algorithms, where multiple collaborative agents in various environments are trying to maximize the sum of discounted return, in the presence of adversarial agents. We argue that the common attack methods are not guaranteed to carry out a successful attack on Multi-task Federated Reinforcement Learning and propose an adaptive attack method with better attack performance. Furthermore, we modify the conventional federated reinforcement learning algorithm to address the issue of adversaries that works equally well with and without the adversaries. Experimentation on different small to mid-size reinforcement learning problems show that the proposed attack method outperforms other general attack methods and the proposed modification to federated reinforcement learning algorithm was able to achieve near-optimal policies in the presence of adversarial agents.
Masked Face Recognition for Secure Authentication
Aug 25, 2020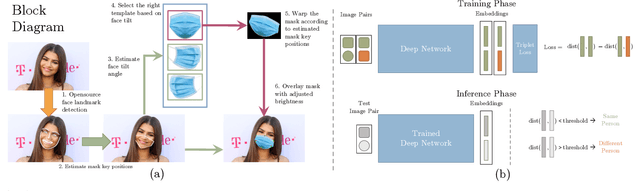
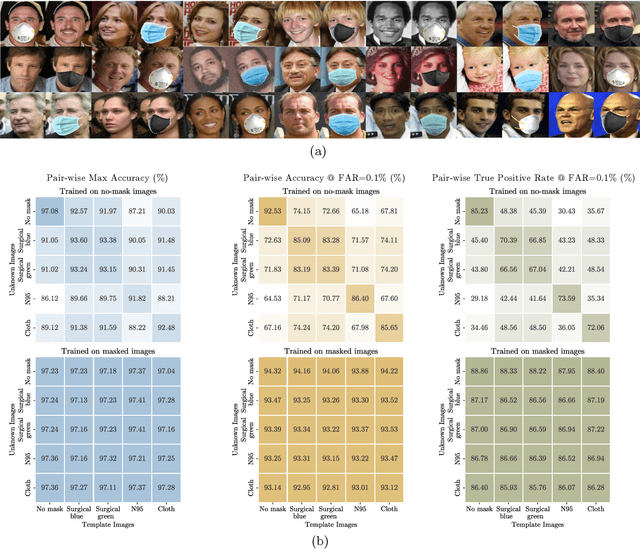
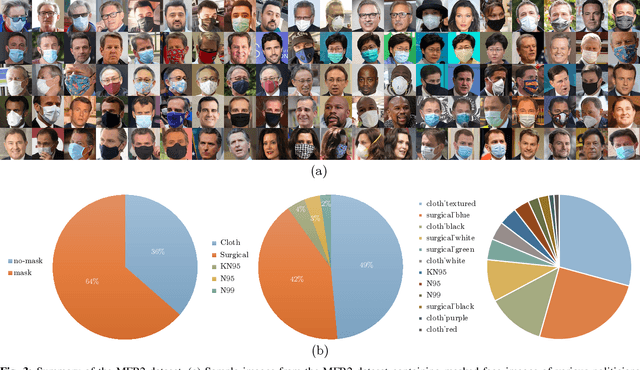
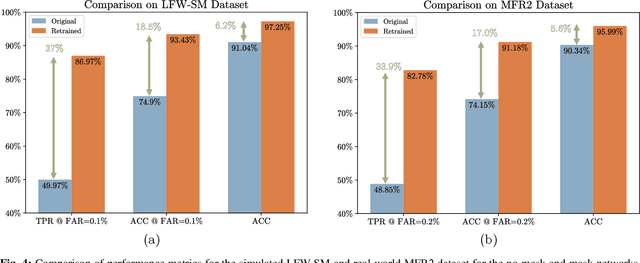
With the recent world-wide COVID-19 pandemic, using face masks have become an important part of our lives. People are encouraged to cover their faces when in public area to avoid the spread of infection. The use of these face masks has raised a serious question on the accuracy of the facial recognition system used for tracking school/office attendance and to unlock phones. Many organizations use facial recognition as a means of authentication and have already developed the necessary datasets in-house to be able to deploy such a system. Unfortunately, masked faces make it difficult to be detected and recognized, thereby threatening to make the in-house datasets invalid and making such facial recognition systems inoperable. This paper addresses a methodology to use the current facial datasets by augmenting it with tools that enable masked faces to be recognized with low false-positive rates and high overall accuracy, without requiring the user dataset to be recreated by taking new pictures for authentication. We present an open-source tool, MaskTheFace to mask faces effectively creating a large dataset of masked faces. The dataset generated with this tool is then used towards training an effective facial recognition system with target accuracy for masked faces. We report an increase of 38% in the true positive rate for the Facenet system. We also test the accuracy of re-trained system on a custom real-world dataset MFR2 and report similar accuracy.
A Decentralized Policy Gradient Approach to Multi-task Reinforcement Learning
Jun 08, 2020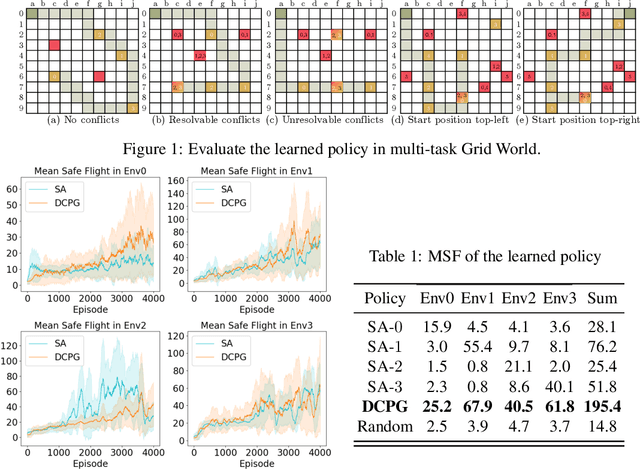
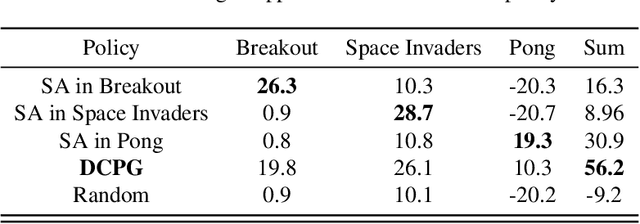

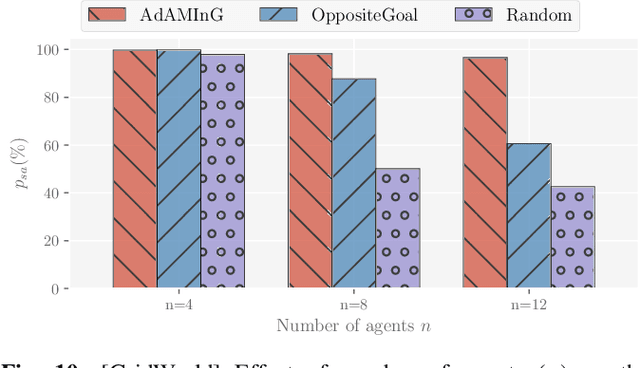
We develop a mathematical framework for solving multi-task reinforcement learning problems based on a type of decentralized policy gradient method. The goal in multi-task reinforcement learning is to learn a common policy that operates effectively in different environments; these environments have similar (or overlapping) state and action spaces, but have different rewards and dynamics. Agents immersed in each of these environments communicate with other agents by sharing their models (i.e. their policy parameterizations) but not their state/reward paths. Our analysis provides a convergence rate for a consensus-based distributed, entropy-regularized policy gradient method for finding such a policy. We demonstrate the effectiveness of the proposed method using a series of numerical experiments. These experiments range from small-scale "Grid World" problems that readily demonstrate the trade-offs involved in multi-task learning to large-scale problems, where common policies are learned to play multiple Atari games or to navigate an airborne drone in multiple (simulated) environments.
Autonomous Navigation via Deep Reinforcement Learning for Resource Constraint Edge Nodes using Transfer Learning
Oct 12, 2019
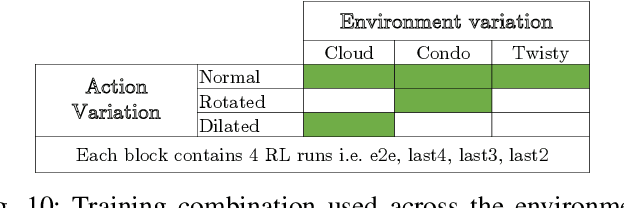
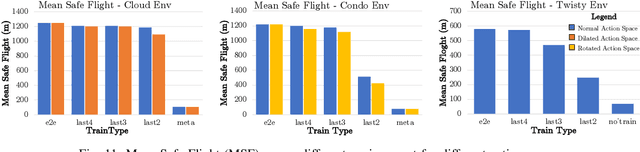
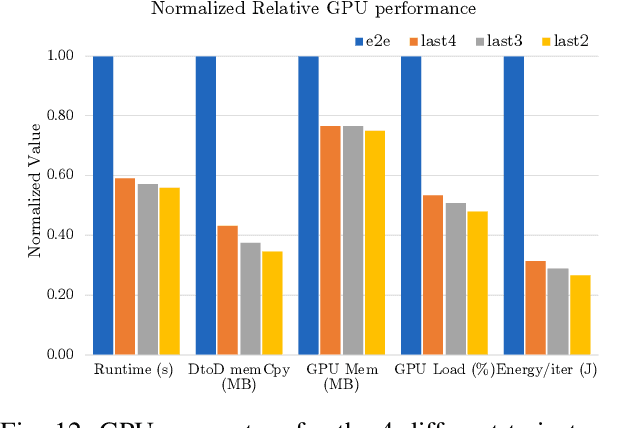
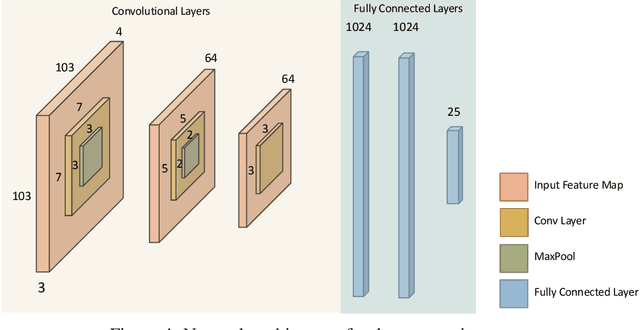
Smart and agile drones are fast becoming ubiquitous at the edge of the cloud. The usage of these drones are constrained by their limited power and compute capability. In this paper, we present a Transfer Learning (TL) based approach to reduce on-board computation required to train a deep neural network for autonomous navigation via Deep Reinforcement Learning for a target algorithmic performance. A library of 3D realistic meta-environments is manually designed using Unreal Gaming Engine and the network is trained end-to-end. These trained meta-weights are then used as initializers to the network in a test environment and fine-tuned for the last few fully connected layers. Variation in drone dynamics and environmental characteristics is carried out to show robustness of the approach. Using NVIDIA GPU profiler it was shown that the energy consumption and training latency is reduced by 3.7x and 1.8x respectively without significant degradation in the performance in terms of average distance traveled before crash i.e. Mean Safe Flight (MSF). The approach is also tested on a real environment using DJI Tello drone and similar results were reported.