 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Task Federated Reinforcement Learning with Adversaries
Paper and Code
Mar 11, 2021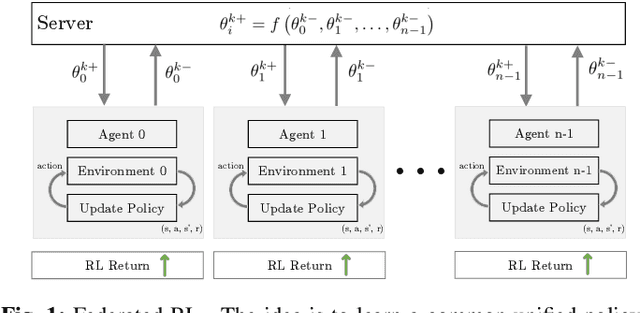
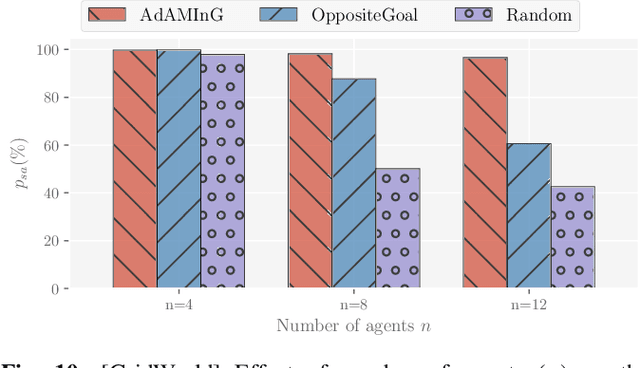
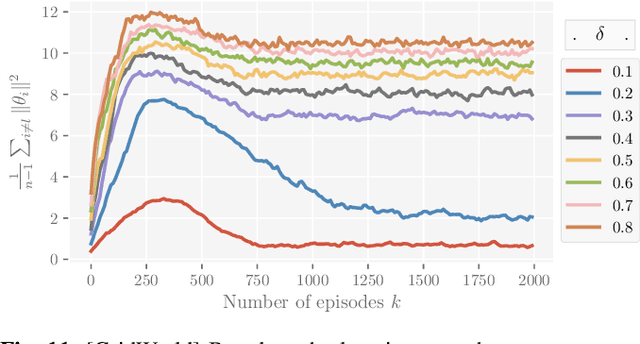
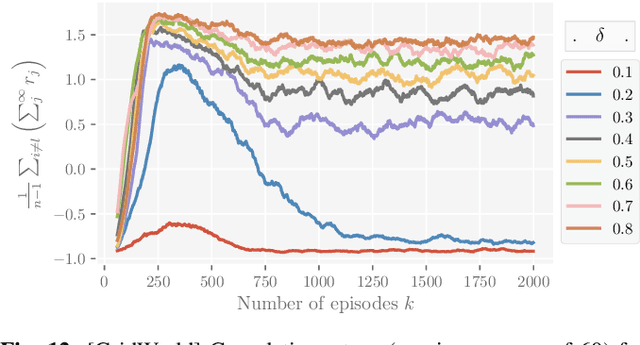
Reinforcement learning algorithms, just like any other Machine learning algorithm pose a serious threat from adversaries. The adversaries can manipulate the learning algorithm resulting in non-optimal policies. In this paper, we analyze the Multi-task Federated Reinforcement Learning algorithms, where multiple collaborative agents in various environments are trying to maximize the sum of discounted return, in the presence of adversarial agents. We argue that the common attack methods are not guaranteed to carry out a successful attack on Multi-task Federated Reinforcement Learning and propose an adaptive attack method with better attack performance. Furthermore, we modify the conventional federated reinforcement learning algorithm to address the issue of adversaries that works equally well with and without the adversaries. Experimentation on different small to mid-size reinforcement learning problems show that the proposed attack method outperforms other general attack methods and the proposed modification to federated reinforcement learning algorithm was able to achieve near-optimal policies in the presence of adversarial agents.