 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREASON: Accelerating Probabilistic Logical Reasoning for Scalable Neuro-Symbolic Intelligence
Jan 28, 2026Neuro-symbolic AI systems integrate neural perception with symbolic reasoning to enable data-efficient, interpretable, and robust intelligence beyond purely neural models. Although this compositional paradigm has shown superior performance in domains such as reasoning, planning, and verification, its deployment remains challenging due to severe inefficiencies in symbolic and probabilistic inference. Through systematic analysis of representative neuro-symbolic workloads, we identify probabilistic logical reasoning as the inefficiency bottleneck, characterized by irregular control flow, low arithmetic intensity, uncoalesced memory accesses, and poor hardware utilization on CPUs and GPUs. This paper presents REASON, an integrated acceleration framework for probabilistic logical reasoning in neuro-symbolic AI. REASON introduces a unified directed acyclic graph representation that captures common structure across symbolic and probabilistic models, coupled with adaptive pruning and regularization. At the architecture level, REASON features a reconfigurable, tree-based processing fabric optimized for irregular traversal, symbolic deduction, and probabilistic aggregation. At the system level, REASON is tightly integrated with GPU streaming multiprocessors through a programmable interface and multi-level pipeline that efficiently orchestrates compositional execution. Evaluated across six neuro-symbolic workloads, REASON achieves 12-50x speedup and 310-681x energy efficiency over desktop and edge GPUs under TSMC 28 nm node. REASON enables real-time probabilistic logical reasoning, completing end-to-end tasks in 0.8 s with 6 mm2 area and 2.12 W power, demonstrating that targeted acceleration of probabilistic logical reasoning is critical for practical and scalable neuro-symbolic AI and positioning REASON as a foundational system architecture for next-generation cognitive intelligence.
NSFlow: An End-to-End FPGA Framework with Scalable Dataflow Architecture for Neuro-Symbolic AI
Apr 29, 2025Neuro-Symbolic AI (NSAI) is an emerging paradigm that integrates neural networks with symbolic reasoning to enhance the transparency, reasoning capabilities, and data efficiency of AI systems. Recent NSAI systems have gained traction due to their exceptional performance in reasoning tasks and human-AI collaborative scenarios. Despite these algorithmic advancements, executing NSAI tasks on existing hardware (e.g., CPUs, GPUs, TPUs) remains challenging, due to their heterogeneous computing kernels, high memory intensity, and unique memory access patterns. Moreover, current NSAI algorithms exhibit significant variation in operation types and scales, making them incompatible with existing ML accelerators. These challenges highlight the need for a versatile and flexible acceleration framework tailored to NSAI workloads. In this paper, we propose NSFlow, an FPGA-based acceleration framework designed to achieve high efficiency, scalability, and versatility across NSAI systems. NSFlow features a design architecture generator that identifies workload data dependencies and creates optimized dataflow architectures, as well as a reconfigurable array with flexible compute units, re-organizable memory, and mixed-precision capabilities. Evaluating across NSAI workloads, NSFlow achieves 31x speedup over Jetson TX2, more than 2x over GPU, 8x speedup over TPU-like systolic array, and more than 3x over Xilinx DPU. NSFlow also demonstrates enhanced scalability, with only 4x runtime increase when symbolic workloads scale by 150x. To the best of our knowledge, NSFlow is the first framework to enable real-time generalizable NSAI algorithms acceleration, demonstrating a promising solution for next-generation cognitive systems.
Generative AI in Embodied Systems: System-Level Analysis of Performance, Efficiency and Scalability
Apr 26, 2025Embodied systems, where generative autonomous agents engage with the physical world through integrated perception, cognition, action, and advanced reasoning powered by large language models (LLMs), hold immense potential for addressing complex, long-horizon, multi-objective tasks in real-world environments. However, deploying these systems remains challenging due to prolonged runtime latency, limited scalability, and heightened sensitivity, leading to significant system inefficiencies. In this paper, we aim to understand the workload characteristics of embodied agent systems and explore optimization solutions. We systematically categorize these systems into four paradigms and conduct benchmarking studies to evaluate their task performance and system efficiency across various modules, agent scales, and embodied tasks. Our benchmarking studies uncover critical challenges, such as prolonged planning and communication latency, redundant agent interactions, complex low-level control mechanisms, memory inconsistencies, exploding prompt lengths, sensitivity to self-correction and execution, sharp declines in success rates, and reduced collaboration efficiency as agent numbers increase. Leveraging these profiling insights, we suggest system optimization strategies to improve the performance, efficiency, and scalability of embodied agents across different paradigms. This paper presents the first system-level analysis of embodied AI agents, and explores opportunities for advancing future embodied system design.
FAVbot: An Autonomous Target Tracking Micro-Robot with Frequency Actuation Control
Jan 26, 2025



Robotic autonomy at centimeter scale requires compact and miniaturization-friendly actuation integrated with sensing and neural network processing assembly within a tiny form factor. Applications of such systems have witnessed significant advancements in recent years in fields such as healthcare, manufacturing, and post-disaster rescue. The system design at this scale puts stringent constraints on power consumption for both the sensory front-end and actuation back-end and the weight of the electronic assembly for robust operation. In this paper, we introduce FAVbot, the first autonomous mobile micro-robotic system integrated with a novel actuation mechanism and convolutional neural network (CNN) based computer vision - all integrated within a compact 3-cm form factor. The novel actuation mechanism utilizes mechanical resonance phenomenon to achieve frequency-controlled steering with a single piezoelectric actuator. Experimental results demonstrate the effectiveness of FAVbot's frequency-controlled actuation, which offers a diverse selection of resonance modes with different motion characteristics. The actuation system is complemented with the vision front-end where a camera along with a microcontroller supports object detection for closed-loop control and autonomous target tracking. This enables adaptive navigation in dynamic environments. This work contributes to the evolving landscape of neural network-enabled micro-robotic systems showing the smallest autonomous robot built using controllable multi-directional single-actuator mechanism.
VAP: The Vulnerability-Adaptive Protection Paradigm Toward Reliable Autonomous Machines
Sep 30, 2024



The next ubiquitous computing platform, following personal computers and smartphones, is poised to be inherently autonomous, encompassing technologies like drones, robots, and self-driving cars. Ensuring reliability for these autonomous machines is critical. However, current resiliency solutions make fundamental trade-offs between reliability and cost, resulting in significant overhead in performance, energy consumption, and chip area. This is due to the "one-size-fits-all" approach commonly used, where the same protection scheme is applied throughout the entire software computing stack. This paper presents the key insight that to achieve high protection coverage with minimal cost, we must leverage the inherent variations in robustness across different layers of the autonomous machine software stack. Specifically, we demonstrate that various nodes in this complex stack exhibit different levels of robustness against hardware faults. Our findings reveal that the front-end of an autonomous machine's software stack tends to be more robust, whereas the back-end is generally more vulnerable. Building on these inherent robustness differences, we propose a Vulnerability-Adaptive Protection (VAP) design paradigm. In this paradigm, the allocation of protection resources - whether spatially (e.g., through modular redundancy) or temporally (e.g., via re-execution) - is made inversely proportional to the inherent robustness of tasks or algorithms within the autonomous machine system. Experimental results show that VAP provides high protection coverage while maintaining low overhead in both autonomous vehicle and drone systems.
H3DFact: Heterogeneous 3D Integrated CIM for Factorization with Holographic Perceptual Representations
Apr 05, 2024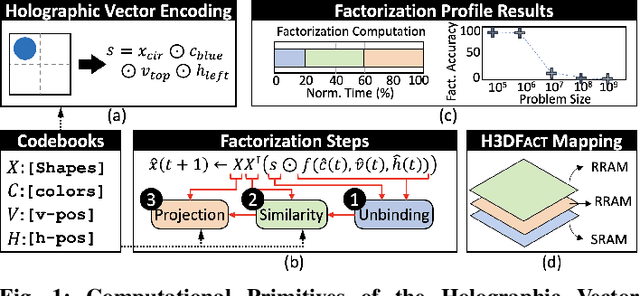
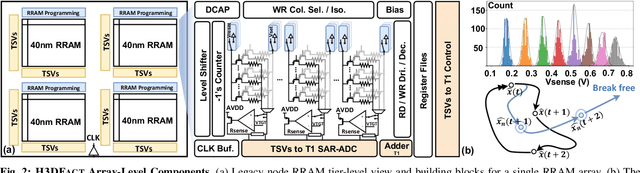
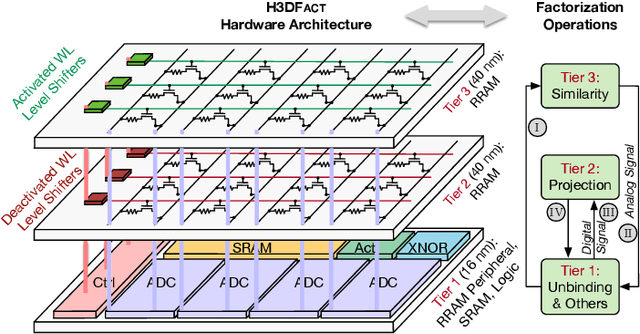
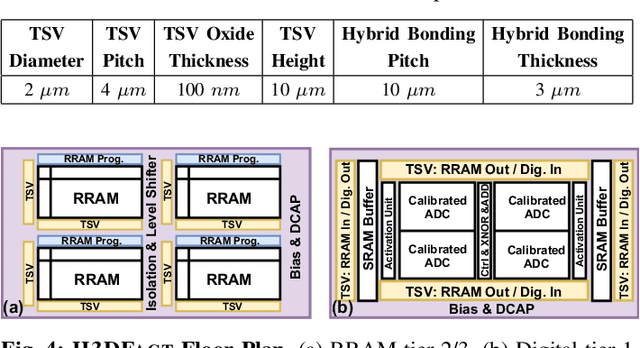
Disentangling attributes of various sensory signals is central to human-like perception and reasoning and a critical task for higher-order cognitive and neuro-symbolic AI systems. An elegant approach to represent this intricate factorization is via high-dimensional holographic vectors drawing on brain-inspired vector symbolic architectures. However, holographic factorization involves iterative computation with high-dimensional matrix-vector multiplications and suffers from non-convergence problems. In this paper, we present H3DFact, a heterogeneous 3D integrated in-memory compute engine capable of efficiently factorizing high-dimensional holographic representations. H3DFact exploits the computation-in-superposition capability of holographic vectors and the intrinsic stochasticity associated with memristive-based 3D compute-in-memory. Evaluated on large-scale factorization and perceptual problems, H3DFact demonstrates superior capability in factorization accuracy and operational capacity by up to five orders of magnitude, with 5.5x compute density, 1.2x energy efficiency improvements, and 5.9x less silicon footprint compared to iso-capacity 2D designs.
Towards Cognitive AI Systems: a Survey and Prospective on Neuro-Symbolic AI
Jan 02, 2024The remarkable advancements in artificial intelligence (AI), primarily driven by deep neural networks, have significantly impacted various aspects of our lives. However, the current challenges surrounding unsustainable computational trajectories, limited robustness, and a lack of explainability call for the development of next-generation AI systems. Neuro-symbolic AI (NSAI) emerges as a promising paradigm, fusing neural, symbolic, and probabilistic approaches to enhance interpretability, robustness, and trustworthiness while facilitating learning from much less data. Recent NSAI systems have demonstrated great potential in collaborative human-AI scenarios with reasoning and cognitive capabilities. In this paper, we provide a systematic review of recent progress in NSAI and analyze the performance characteristics and computational operators of NSAI models. Furthermore, we discuss the challenges and potential future directions of NSAI from both system and architectural perspectives.
BERRY: Bit Error Robustness for Energy-Efficient Reinforcement Learning-Based Autonomous Systems
Jul 19, 2023



Autonomous systems, such as Unmanned Aerial Vehicles (UAVs), are expected to run complex reinforcement learning (RL) models to execute fully autonomous position-navigation-time tasks within stringent onboard weight and power constraints. We observe that reducing onboard operating voltage can benefit the energy efficiency of both the computation and flight mission, however, it can also result in on-chip bit failures that are detrimental to mission safety and performance. To this end, we propose BERRY, a robust learning framework to improve bit error robustness and energy efficiency for RL-enabled autonomous systems. BERRY supports robust learning, both offline and on-board the UAV, and for the first time, demonstrates the practicality of robust low-voltage operation on UAVs that leads to high energy savings in both compute-level operation and system-level quality-of-flight. We perform extensive experiments on 72 autonomous navigation scenarios and demonstrate that BERRY generalizes well across environments, UAVs, autonomy policies, operating voltages and fault patterns, and consistently improves robustness, efficiency and mission performance, achieving up to 15.62% reduction in flight energy, 18.51% increase in the number of successful missions, and 3.43x processing energy reduction.
Real-Time Fully Unsupervised Domain Adaptation for Lane Detection in Autonomous Driving
Jun 29, 2023

While deep neural networks are being utilized heavily for autonomous driving, they need to be adapted to new unseen environmental conditions for which they were not trained. We focus on a safety critical application of lane detection, and propose a lightweight, fully unsupervised, real-time adaptation approach that only adapts the batch-normalization parameters of the model. We demonstrate that our technique can perform inference, followed by on-device adaptation, under a tight constraint of 30 FPS on Nvidia Jetson Orin. It shows similar accuracy (avg. of 92.19%) as a state-of-the-art semi-supervised adaptation algorithm but which does not support real-time adaptation.
Non-Uniform Interpolation in Integrated Gradients for Low-Latency Explainable-AI
Feb 22, 2023There has been a surge in Explainable-AI (XAI) methods that provide insights into the workings of Deep Neural Network (DNN) models. Integrated Gradients (IG) is a popular XAI algorithm that attributes relevance scores to input features commensurate with their contribution to the model's output. However, it requires multiple forward \& backward passes through the model. Thus, compared to a single forward-pass inference, there is a significant computational overhead to generate the explanation which hinders real-time XAI. This work addresses the aforementioned issue by accelerating IG with a hardware-aware algorithm optimization. We propose a novel non-uniform interpolation scheme to compute the IG attribution scores which replaces the baseline uniform interpolation. Our algorithm significantly reduces the total interpolation steps required without adversely impacting convergence. Experiments on the ImageNet dataset using a pre-trained InceptionV3 model demonstrate \textit{2.6-3.6}$\times$ performance speedup on GPU systems for iso-convergence. This includes the minimal \textit{0.2-3.2}\% latency overhead introduced by the pre-processing stage of computing the non-uniform interpolation step-sizes.