 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptBot: Combining LLM with Knowledge Graphs and Human Input for Generic-to-Specific Task Decomposition and Knowledge Refinement
Feb 04, 2025Embodied agents assisting humans are often asked to complete a new task in a new scenario. An agent preparing a particular dish in the kitchen based on a known recipe may be asked to prepare a new dish or to perform cleaning tasks in the storeroom. There may not be sufficient resources, e.g., time or labeled examples, to train the agent for these new situations. Large Language Models (LLMs) trained on considerable knowledge across many domains are able to predict a sequence of abstract actions for such new tasks and scenarios, although it may not be possible for the agent to execute this action sequence due to task-, agent-, or domain-specific constraints. Our framework addresses these challenges by leveraging the generic predictions provided by LLM and the prior domain-specific knowledge encoded in a Knowledge Graph (KG), enabling an agent to quickly adapt to new tasks and scenarios. The robot also solicits and uses human input as needed to refine its existing knowledge. Based on experimental evaluation over cooking and cleaning tasks in simulation domains, we demonstrate that the interplay between LLM, KG, and human input leads to substantial performance gains compared with just using the LLM output.
Anticipate & Act : Integrating LLMs and Classical Planning for Efficient Task Execution in Household Environments
Feb 04, 2025



Assistive agents performing household tasks such as making the bed or cooking breakfast often compute and execute actions that accomplish one task at a time. However, efficiency can be improved by anticipating upcoming tasks and computing an action sequence that jointly achieves these tasks. State-of-the-art methods for task anticipation use data-driven deep networks and Large Language Models (LLMs), but they do so at the level of high-level tasks and/or require many training examples. Our framework leverages the generic knowledge of LLMs through a small number of prompts to perform high-level task anticipation, using the anticipated tasks as goals in a classical planning system to compute a sequence of finer-granularity actions that jointly achieve these goals. We ground and evaluate our framework's abilities in realistic scenarios in the VirtualHome environment and demonstrate a 31% reduction in execution time compared with a system that does not consider upcoming tasks.
Unlocking Real-Time Fluorescence Lifetime Imaging: Multi-Pixel Parallelism for FPGA-Accelerated Processing
Oct 09, 2024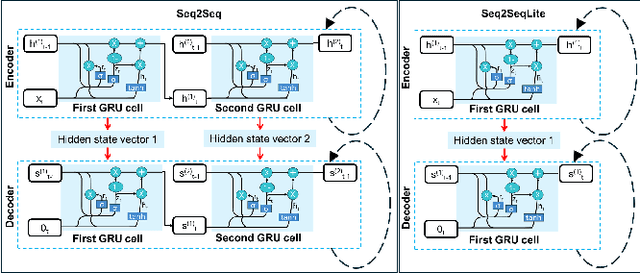
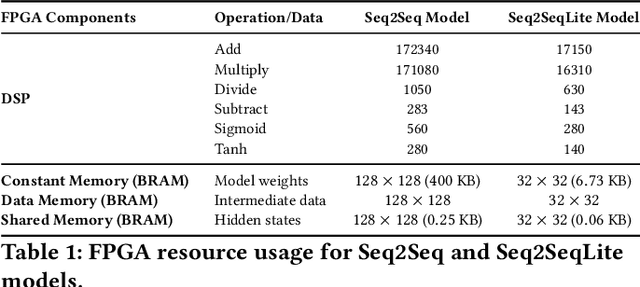


Fluorescence lifetime imaging (FLI) is a widely used technique in the biomedical field for measuring the decay times of fluorescent molecules, providing insights into metabolic states, protein interactions, and ligand-receptor bindings. However, its broader application in fast biological processes, such as dynamic activity monitoring, and clinical use, such as in guided surgery, is limited by long data acquisition times and computationally demanding data processing. While deep learning has reduced post-processing times, time-resolved data acquisition remains a bottleneck for real-time applications. To address this, we propose a method to achieve real-time FLI using an FPGA-based hardware accelerator. Specifically, we implemented a GRU-based sequence-to-sequence (Seq2Seq) model on an FPGA board compatible with time-resolved cameras. The GRU model balances accurate processing with the resource constraints of FPGAs, which have limited DSP units and BRAM. The limited memory and computational resources on the FPGA require efficient scheduling of operations and memory allocation to deploy deep learning models for low-latency applications. We address these challenges by using STOMP, a queue-based discrete-event simulator that automates and optimizes task scheduling and memory management on hardware. By integrating a GRU-based Seq2Seq model and its compressed version, called Seq2SeqLite, generated through knowledge distillation, we were able to process multiple pixels in parallel, reducing latency compared to sequential processing. We explore various levels of parallelism to achieve an optimal balance between performance and resource utilization. Our results indicate that the proposed techniques achieved a 17.7x and 52.0x speedup over manual scheduling for the Seq2Seq model and the Seq2SeqLite model, respectively.
Compressing Recurrent Neural Networks for FPGA-accelerated Implementation in Fluorescence Lifetime Imaging
Oct 01, 2024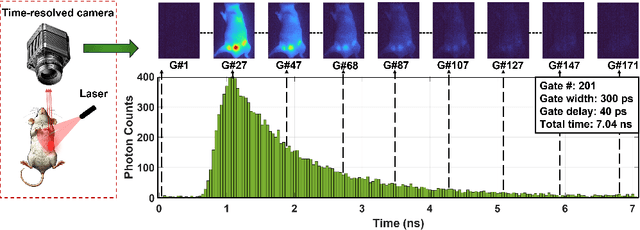

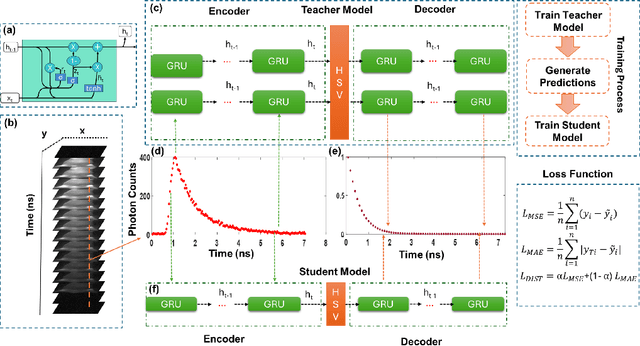
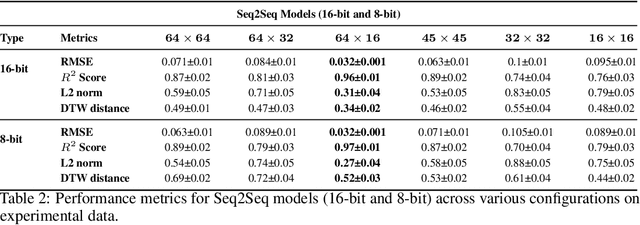
Fluorescence lifetime imaging (FLI) is an important technique for studying cellular environments and molecular interactions, but its real-time application is limited by slow data acquisition, which requires capturing large time-resolved images and complex post-processing using iterative fitting algorithms. Deep learning (DL) models enable real-time inference, but can be computationally demanding due to complex architectures and large matrix operations. This makes DL models ill-suited for direct implementation on field-programmable gate array (FPGA)-based camera hardware. Model compression is thus crucial for practical deployment for real-time inference generation. In this work, we focus on compressing recurrent neural networks (RNNs), which are well-suited for FLI time-series data processing, to enable deployment on resource-constrained FPGA boards. We perform an empirical evaluation of various compression techniques, including weight reduction, knowledge distillation (KD), post-training quantization (PTQ), and quantization-aware training (QAT), to reduce model size and computational load while preserving inference accuracy. Our compressed RNN model, Seq2SeqLite, achieves a balance between computational efficiency and prediction accuracy, particularly at 8-bit precision. By applying KD, the model parameter size was reduced by 98\% while retaining performance, making it suitable for concurrent real-time FLI analysis on FPGA during data capture. This work represents a big step towards integrating hardware-accelerated real-time FLI analysis for fast biological processes.
Anticipate & Collab: Data-driven Task Anticipation and Knowledge-driven Planning for Human-robot Collaboration
Apr 04, 2024



An agent assisting humans in daily living activities can collaborate more effectively by anticipating upcoming tasks. Data-driven methods represent the state of the art in task anticipation, planning, and related problems, but these methods are resource-hungry and opaque. Our prior work introduced a proof of concept framework that used an LLM to anticipate 3 high-level tasks that served as goals for a classical planning system that computed a sequence of low-level actions for the agent to achieve these goals. This paper describes DaTAPlan, our framework that significantly extends our prior work toward human-robot collaboration. Specifically, DaTAPlan planner computes actions for an agent and a human to collaboratively and jointly achieve the tasks anticipated by the LLM, and the agent automatically adapts to unexpected changes in human action outcomes and preferences. We evaluate DaTAPlan capabilities in a realistic simulation environment, demonstrating accurate task anticipation, effective human-robot collaboration, and the ability to adapt to unexpected changes. Project website: https://dataplan-hrc.github.io
BERRY: Bit Error Robustness for Energy-Efficient Reinforcement Learning-Based Autonomous Systems
Jul 19, 2023



Autonomous systems, such as Unmanned Aerial Vehicles (UAVs), are expected to run complex reinforcement learning (RL) models to execute fully autonomous position-navigation-time tasks within stringent onboard weight and power constraints. We observe that reducing onboard operating voltage can benefit the energy efficiency of both the computation and flight mission, however, it can also result in on-chip bit failures that are detrimental to mission safety and performance. To this end, we propose BERRY, a robust learning framework to improve bit error robustness and energy efficiency for RL-enabled autonomous systems. BERRY supports robust learning, both offline and on-board the UAV, and for the first time, demonstrates the practicality of robust low-voltage operation on UAVs that leads to high energy savings in both compute-level operation and system-level quality-of-flight. We perform extensive experiments on 72 autonomous navigation scenarios and demonstrate that BERRY generalizes well across environments, UAVs, autonomy policies, operating voltages and fault patterns, and consistently improves robustness, efficiency and mission performance, achieving up to 15.62% reduction in flight energy, 18.51% increase in the number of successful missions, and 3.43x processing energy reduction.