 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInverting Foundation Models of Brain Function with Simulation-Based Inference
Apr 26, 2026Foundation models of brain activity promise a new frontier for in silico neuroscience by emulating neural responses to complex stimuli across tasks and modalities. A natural next step is to ask whether these models can also be used in reverse. Can we recover a stimulus or its properties from synthetic brain activity? We study this question in a proof-of-concept setting using TRIBEv2. We pair the brain emulator with large language models (LLMs) that generate news headlines from linguistic parameters such as valence, arousal, and dominance. We then use simulation-based inference to learn a probabilistic mapping from brain maps to latent stimulus parameters. Our results show that these parameters can be recovered from predicted brain maps, validating the quality of neural encodings. They also show that LLMs can serve as controllable stimulus generators for simulated experiments. Together, these findings provide a step toward decoding and inverse design with foundation brain models.
CogFormer: Learn All Your Models Once
Mar 20, 2026Simulation-based inference (SBI) with neural networks has accelerated and transformed cognitive modeling workflows. SBI enables modelers to fit complex models that were previously difficult or impossible to estimate, while also allowing rapid estimation across large numbers of datasets. However, the utility of SBI for iterating over varying modeling assumptions remains limited: changing parameterizations, generative functions, priors, and design variables all necessitate model retraining and hence diminish the benefits of amortization. To address these issues, we pilot a meta-amortized framework for cognitive modeling which we nickname the CogFormer. Our framework trains a transformer-based architecture that remains valid across a combinatorial number of structurally similar models, allowing for changing data types, parameters, design matrices, and sample sizes. We present promising quantitative results across families of decision-making models for binary, multi-alternative, and continuous responses. Our evaluation suggests that CogFormer can accurately estimate parameters across model families with a minimal amortization offset, making it a potentially powerful engine that catalyzes cognitive modeling workflows.
BayesFlow 2.0: Multi-Backend Amortized Bayesian Inference in Python
Feb 06, 2026Modern Bayesian inference involves a mixture of computational methods for estimating, validating, and drawing conclusions from probabilistic models as part of principled workflows. An overarching motif of many Bayesian methods is that they are relatively slow, which often becomes prohibitive when fitting complex models to large data sets. Amortized Bayesian inference (ABI) offers a path to solving the computational challenges of Bayes. ABI trains neural networks on model simulations, rewarding users with rapid inference of any model-implied quantity, such as point estimates, likelihoods, or full posterior distributions. In this work, we present the Python library BayesFlow, Version 2.0, for general-purpose ABI. Along with direct posterior, likelihood, and ratio estimation, the software includes support for multiple popular deep learning backends, a rich collection of generative networks for sampling and density estimation, complete customization and high-level interfaces, as well as new capabilities for hyperparameter optimization, design optimization, and hierarchical modeling. Using a case study on dynamical system parameter estimation, combined with comparisons to similar software, we show that our streamlined, user-friendly workflow has strong potential to support broad adoption.
JADAI: Jointly Amortizing Adaptive Design and Bayesian Inference
Dec 28, 2025We consider problems of parameter estimation where design variables can be actively optimized to maximize information gain. To this end, we introduce JADAI, a framework that jointly amortizes Bayesian adaptive design and inference by training a policy, a history network, and an inference network end-to-end. The networks minimize a generic loss that aggregates incremental reductions in posterior error along experimental sequences. Inference networks are instantiated with diffusion-based posterior estimators that can approximate high-dimensional and multimodal posteriors at every experimental step. Across standard adaptive design benchmarks, JADAI achieves superior or competitive performance.
Diffusion Models in Simulation-Based Inference: A Tutorial Review
Dec 22, 2025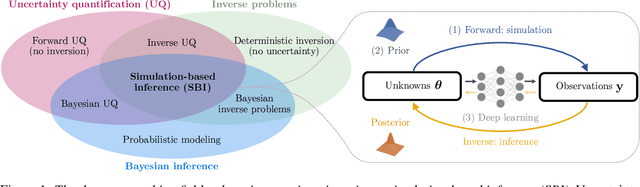

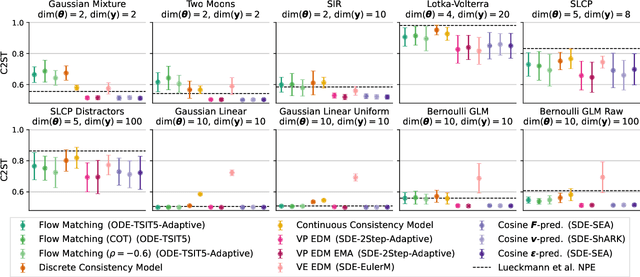
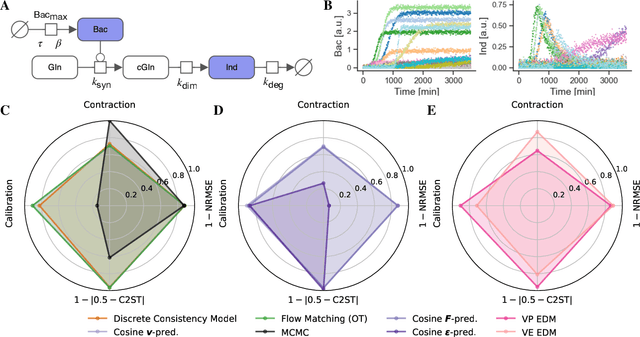
Diffusion models have recently emerged as powerful learners for simulation-based inference (SBI), enabling fast and accurate estimation of latent parameters from simulated and real data. Their score-based formulation offers a flexible way to learn conditional or joint distributions over parameters and observations, thereby providing a versatile solution to various modeling problems. In this tutorial review, we synthesize recent developments on diffusion models for SBI, covering design choices for training, inference, and evaluation. We highlight opportunities created by various concepts such as guidance, score composition, flow matching, consistency models, and joint modeling. Furthermore, we discuss how efficiency and statistical accuracy are affected by noise schedules, parameterizations, and samplers. Finally, we illustrate these concepts with case studies across parameter dimensionalities, simulation budgets, and model types, and outline open questions for future research.
Improving the Accuracy of Amortized Model Comparison with Self-Consistency
Dec 16, 2025



Amortized Bayesian inference (ABI) offers fast, scalable approximations to posterior densities by training neural surrogates on data simulated from the statistical model. However, ABI methods are highly sensitive to model misspecification: when observed data fall outside the training distribution (generative scope of the statistical models), neural surrogates can behave unpredictably. This makes it a challenge in a model comparison setting, where multiple statistical models are considered, of which at least some are misspecified. Recent work on self-consistency (SC) provides a promising remedy to this issue, accessible even for empirical data (without ground-truth labels). In this work, we investigate how SC can improve amortized model comparison conceptualized in four different ways. Across two synthetic and two real-world case studies, we find that approaches for model comparison that estimate marginal likelihoods through approximate parameter posteriors consistently outperform methods that directly approximate model evidence or posterior model probabilities. SC training improves robustness when the likelihood is available, even under severe model misspecification. The benefits of SC for methods without access of analytic likelihoods are more limited and inconsistent. Our results suggest practical guidance for reliable amortized Bayesian model comparison: prefer parameter posterior-based methods and augment them with SC training on empirical datasets to mitigate extrapolation bias under model misspecification.
Does Unsupervised Domain Adaptation Improve the Robustness of Amortized Bayesian Inference? A Systematic Evaluation
Feb 07, 2025



Neural networks are fragile when confronted with data that significantly deviates from their training distribution. This is true in particular for simulation-based inference methods, such as neural amortized Bayesian inference (ABI), where models trained on simulated data are deployed on noisy real-world observations. Recent robust approaches employ unsupervised domain adaptation (UDA) to match the embedding spaces of simulated and observed data. However, the lack of comprehensive evaluations across different domain mismatches raises concerns about the reliability in high-stakes applications. We address this gap by systematically testing UDA approaches across a wide range of misspecification scenarios in both a controlled and a high-dimensional benchmark. We demonstrate that aligning summary spaces between domains effectively mitigates the impact of unmodeled phenomena or noise. However, the same alignment mechanism can lead to failures under prior misspecifications - a critical finding with practical consequences. Our results underscore the need for careful consideration of misspecification types when using UDA techniques to increase the robustness of ABI in practice.
Expert-elicitation method for non-parametric joint priors using normalizing flows
Nov 24, 2024We propose an expert-elicitation method for learning non-parametric joint prior distributions using normalizing flows. Normalizing flows are a class of generative models that enable exact, single-step density evaluation and can capture complex density functions through specialized deep neural networks. Building on our previously introduced simulation-based framework, we adapt and extend the methodology to accommodate non-parametric joint priors. Our framework thus supports the development of elicitation methods for learning both parametric and non-parametric priors, as well as independent or joint priors for model parameters. To evaluate the performance of the proposed method, we perform four simulation studies and present an evaluation pipeline that incorporates diagnostics and additional evaluation tools to support decision-making at each stage of the elicitation process.
Aligning Motion-Blurred Images Using Contrastive Learning on Overcomplete Pixels
Oct 09, 2024


We propose a new contrastive objective for learning overcomplete pixel-level features that are invariant to motion blur. Other invariances (e.g., pose, illumination, or weather) can be learned by applying the corresponding transformations on unlabeled images during self-supervised training. We showcase that a simple U-Net trained with our objective can produce local features useful for aligning the frames of an unseen video captured with a moving camera under realistic and challenging conditions. Using a carefully designed toy example, we also show that the overcomplete pixels can encode the identity of objects in an image and the pixel coordinates relative to these objects.
Compressing Recurrent Neural Networks for FPGA-accelerated Implementation in Fluorescence Lifetime Imaging
Oct 01, 2024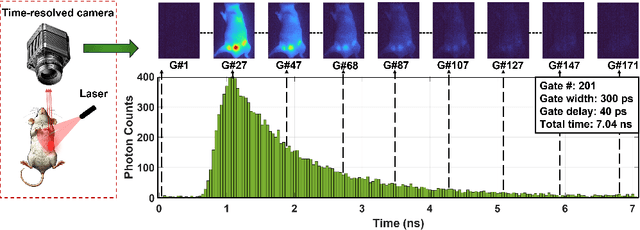

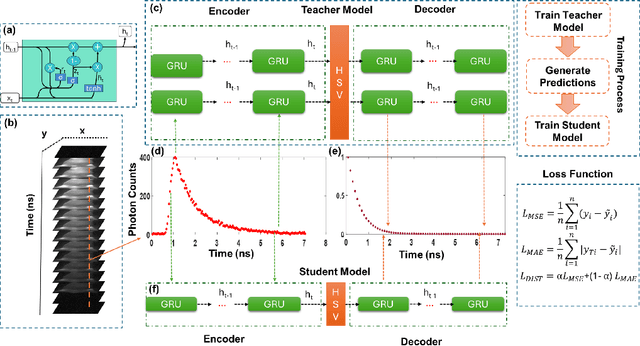
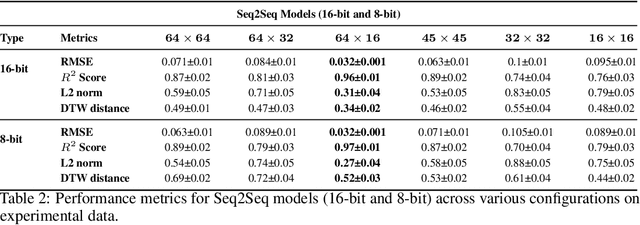
Fluorescence lifetime imaging (FLI) is an important technique for studying cellular environments and molecular interactions, but its real-time application is limited by slow data acquisition, which requires capturing large time-resolved images and complex post-processing using iterative fitting algorithms. Deep learning (DL) models enable real-time inference, but can be computationally demanding due to complex architectures and large matrix operations. This makes DL models ill-suited for direct implementation on field-programmable gate array (FPGA)-based camera hardware. Model compression is thus crucial for practical deployment for real-time inference generation. In this work, we focus on compressing recurrent neural networks (RNNs), which are well-suited for FLI time-series data processing, to enable deployment on resource-constrained FPGA boards. We perform an empirical evaluation of various compression techniques, including weight reduction, knowledge distillation (KD), post-training quantization (PTQ), and quantization-aware training (QAT), to reduce model size and computational load while preserving inference accuracy. Our compressed RNN model, Seq2SeqLite, achieves a balance between computational efficiency and prediction accuracy, particularly at 8-bit precision. By applying KD, the model parameter size was reduced by 98\% while retaining performance, making it suitable for concurrent real-time FLI analysis on FPGA during data capture. This work represents a big step towards integrating hardware-accelerated real-time FLI analysis for fast biological processes.