 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompressing Recurrent Neural Networks for FPGA-accelerated Implementation in Fluorescence Lifetime Imaging
Paper and Code
Oct 01, 2024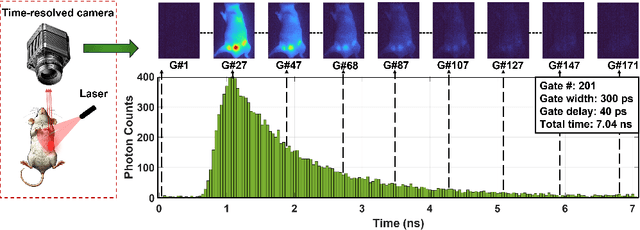

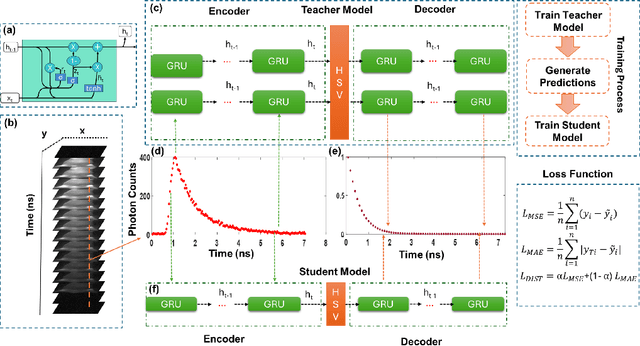
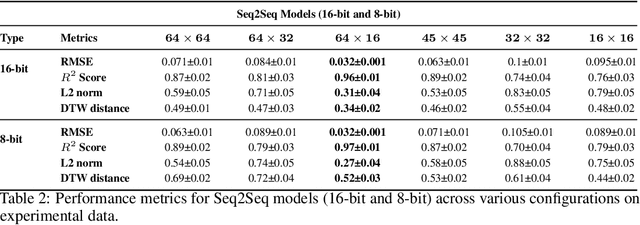
Fluorescence lifetime imaging (FLI) is an important technique for studying cellular environments and molecular interactions, but its real-time application is limited by slow data acquisition, which requires capturing large time-resolved images and complex post-processing using iterative fitting algorithms. Deep learning (DL) models enable real-time inference, but can be computationally demanding due to complex architectures and large matrix operations. This makes DL models ill-suited for direct implementation on field-programmable gate array (FPGA)-based camera hardware. Model compression is thus crucial for practical deployment for real-time inference generation. In this work, we focus on compressing recurrent neural networks (RNNs), which are well-suited for FLI time-series data processing, to enable deployment on resource-constrained FPGA boards. We perform an empirical evaluation of various compression techniques, including weight reduction, knowledge distillation (KD), post-training quantization (PTQ), and quantization-aware training (QAT), to reduce model size and computational load while preserving inference accuracy. Our compressed RNN model, Seq2SeqLite, achieves a balance between computational efficiency and prediction accuracy, particularly at 8-bit precision. By applying KD, the model parameter size was reduced by 98\% while retaining performance, making it suitable for concurrent real-time FLI analysis on FPGA during data capture. This work represents a big step towards integrating hardware-accelerated real-time FLI analysis for fast biological processes.