 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesFlow 2.0: Multi-Backend Amortized Bayesian Inference in Python
Feb 06, 2026Modern Bayesian inference involves a mixture of computational methods for estimating, validating, and drawing conclusions from probabilistic models as part of principled workflows. An overarching motif of many Bayesian methods is that they are relatively slow, which often becomes prohibitive when fitting complex models to large data sets. Amortized Bayesian inference (ABI) offers a path to solving the computational challenges of Bayes. ABI trains neural networks on model simulations, rewarding users with rapid inference of any model-implied quantity, such as point estimates, likelihoods, or full posterior distributions. In this work, we present the Python library BayesFlow, Version 2.0, for general-purpose ABI. Along with direct posterior, likelihood, and ratio estimation, the software includes support for multiple popular deep learning backends, a rich collection of generative networks for sampling and density estimation, complete customization and high-level interfaces, as well as new capabilities for hyperparameter optimization, design optimization, and hierarchical modeling. Using a case study on dynamical system parameter estimation, combined with comparisons to similar software, we show that our streamlined, user-friendly workflow has strong potential to support broad adoption.
Does Unsupervised Domain Adaptation Improve the Robustness of Amortized Bayesian Inference? A Systematic Evaluation
Feb 07, 2025



Neural networks are fragile when confronted with data that significantly deviates from their training distribution. This is true in particular for simulation-based inference methods, such as neural amortized Bayesian inference (ABI), where models trained on simulated data are deployed on noisy real-world observations. Recent robust approaches employ unsupervised domain adaptation (UDA) to match the embedding spaces of simulated and observed data. However, the lack of comprehensive evaluations across different domain mismatches raises concerns about the reliability in high-stakes applications. We address this gap by systematically testing UDA approaches across a wide range of misspecification scenarios in both a controlled and a high-dimensional benchmark. We demonstrate that aligning summary spaces between domains effectively mitigates the impact of unmodeled phenomena or noise. However, the same alignment mechanism can lead to failures under prior misspecifications - a critical finding with practical consequences. Our results underscore the need for careful consideration of misspecification types when using UDA techniques to increase the robustness of ABI in practice.
Sensitivity-Aware Amortized Bayesian Inference
Oct 23, 2023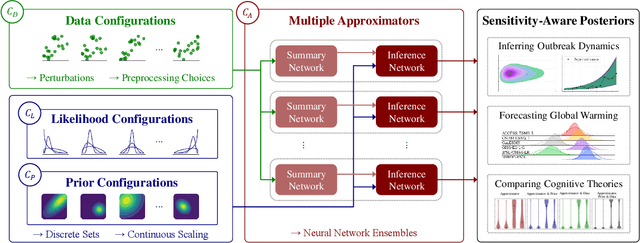
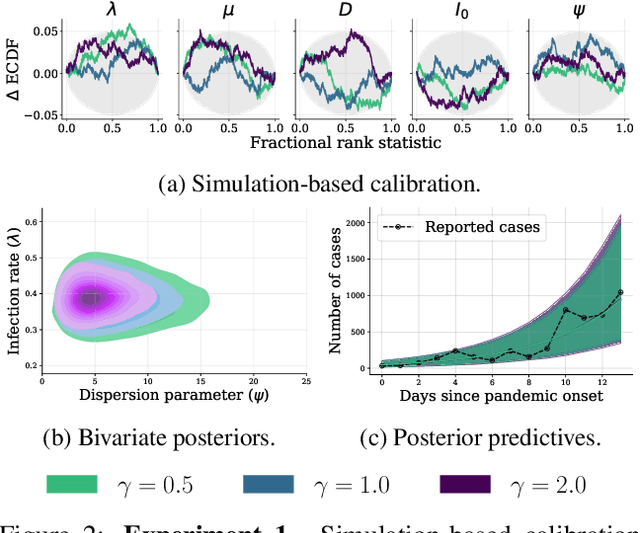

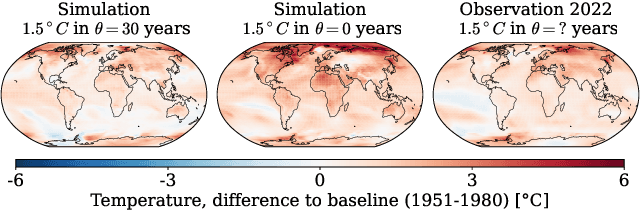
Bayesian inference is a powerful framework for making probabilistic inferences and decisions under uncertainty. Fundamental choices in modern Bayesian workflows concern the specification of the likelihood function and prior distributions, the posterior approximator, and the data. Each choice can significantly influence model-based inference and subsequent decisions, thereby necessitating sensitivity analysis. In this work, we propose a multifaceted approach to integrate sensitivity analyses into amortized Bayesian inference (ABI, i.e., simulation-based inference with neural networks). First, we utilize weight sharing to encode the structural similarities between alternative likelihood and prior specifications in the training process with minimal computational overhead. Second, we leverage the rapid inference of neural networks to assess sensitivity to various data perturbations or pre-processing procedures. In contrast to most other Bayesian approaches, both steps circumvent the costly bottleneck of refitting the model(s) for each choice of likelihood, prior, or dataset. Finally, we propose to use neural network ensembles to evaluate variation in results induced by unreliable approximation on unseen data. We demonstrate the effectiveness of our method in applied modeling problems, ranging from the estimation of disease outbreak dynamics and global warming thresholds to the comparison of human decision-making models. Our experiments showcase how our approach enables practitioners to effectively unveil hidden relationships between modeling choices and inferential conclusions.
BayesFlow: Amortized Bayesian Workflows With Neural Networks
Jul 10, 2023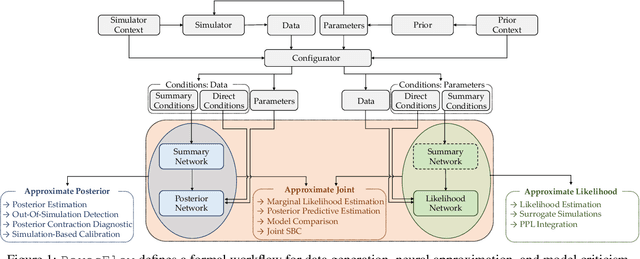
Modern Bayesian inference involves a mixture of computational techniques for estimating, validating, and drawing conclusions from probabilistic models as part of principled workflows for data analysis. Typical problems in Bayesian workflows are the approximation of intractable posterior distributions for diverse model types and the comparison of competing models of the same process in terms of their complexity and predictive performance. This manuscript introduces the Python library BayesFlow for simulation-based training of established neural network architectures for amortized data compression and inference. Amortized Bayesian inference, as implemented in BayesFlow, enables users to train custom neural networks on model simulations and re-use these networks for any subsequent application of the models. Since the trained networks can perform inference almost instantaneously, the upfront neural network training is quickly amortized.
A Deep Learning Method for Comparing Bayesian Hierarchical Models
Jan 27, 2023

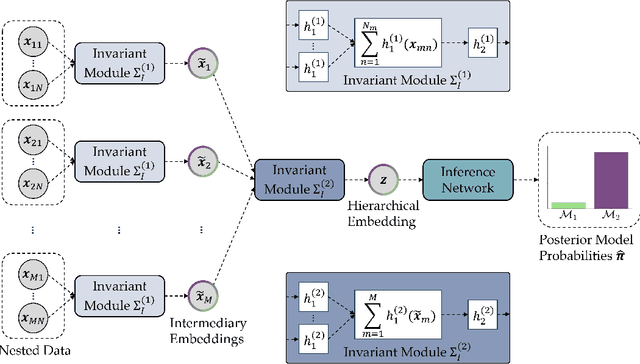

Bayesian model comparison (BMC) offers a principled approach for assessing the relative merits of competing computational models and propagating uncertainty into model selection decisions. However, BMC is often intractable for the popular class of hierarchical models due to their high-dimensional nested parameter structure. To address this intractability, we propose a deep learning method for performing BMC on any set of hierarchical models which can be instantiated as probabilistic programs. Since our method enables amortized inference, it allows efficient re-estimation of posterior model probabilities and fast performance validation prior to any real-data application. In a series of extensive validation studies, we benchmark the performance of our method against the state-of-the-art bridge sampling method and demonstrate excellent amortized inference across all BMC settings. We then use our method to compare four hierarchical evidence accumulation models that have previously been deemed intractable for BMC due to partly implicit likelihoods. In this application, we corroborate evidence for the recently proposed L\'evy flight model of decision-making and show how transfer learning can be leveraged to enhance training efficiency. Reproducible code for all analyses is provided.