 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShow Me What You Don't Know: Efficient Sampling from Invariant Sets for Model Validation
Mar 23, 2026The performance of machine learning models is determined by the quality of their learned features. They should be invariant under irrelevant data variation but sensitive to task-relevant details. To visualize whether this is the case, we propose a method to analyze feature extractors by sampling from their fibers -- equivalence classes defined by their invariances -- given an arbitrary representative. Unlike existing work where a dedicated generative model is trained for each feature detector, our algorithm is training-free and exploits a pretrained diffusion or flow-matching model as a prior. The fiber loss -- which penalizes mismatch in features -- guides the denoising process toward the desired equivalence class, via non-linear diffusion trajectory matching. This replaces days of training for invariance learning with a single guided generation procedure at comparable fidelity. Experiments on popular datasets (ImageNet, CheXpert) and model types (ResNet, DINO, BiomedClip) demonstrate that our framework can reveal invariances ranging from very desirable to concerning behaviour. For instance, we show how Qwen-2B places patients with situs inversus (heart on the right side) in the same fiber as typical anatomy.
Breaking the Simplification Bottleneck in Amortized Neural Symbolic Regression
Feb 09, 2026Symbolic regression (SR) aims to discover interpretable analytical expressions that accurately describe observed data. Amortized SR promises to be much more efficient than the predominant genetic programming SR methods, but currently struggles to scale to realistic scientific complexity. We find that a key obstacle is the lack of a fast reduction of equivalent expressions to a concise normalized form. Amortized SR has addressed this by general-purpose Computer Algebra Systems (CAS) like SymPy, but the high computational cost severely limits training and inference speed. We propose SimpliPy, a rule-based simplification engine achieving a 100-fold speed-up over SymPy at comparable quality. This enables substantial improvements in amortized SR, including scalability to much larger training sets, more efficient use of the per-expression token budget, and systematic training set decontamination with respect to equivalent test expressions. We demonstrate these advantages in our Flash-ANSR framework, which achieves much better accuracy than amortized baselines (NeSymReS, E2E) on the FastSRB benchmark. Moreover, it performs on par with state-of-the-art direct optimization (PySR) while recovering more concise instead of more complex expressions with increasing inference budget.
From Core to Detail: Unsupervised Disentanglement with Entropy-Ordered Flows
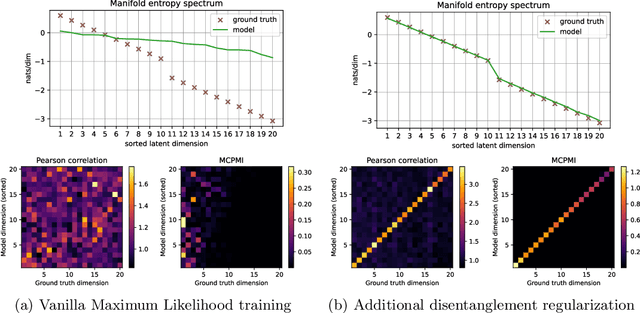
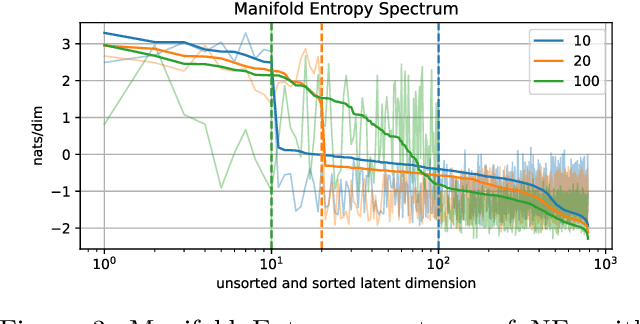
Feb 06, 2026Learning unsupervised representations that are both semantically meaningful and stable across runs remains a central challenge in modern representation learning. We introduce entropy-ordered flows (EOFlows), a normalizing-flow framework that orders latent dimensions by their explained entropy, analogously to PCA's explained variance. This ordering enables adaptive injective flows: after training, one may retain only the top C latent variables to form a compact core representation while the remaining variables capture fine-grained detail and noise, with C chosen flexibly at inference time rather than fixed during training. EOFlows build on insights from Independent Mechanism Analysis, Principal Component Flows and Manifold Entropic Metrics. We combine likelihood-based training with local Jacobian regularization and noise augmentation into a method that scales well to high-dimensional data such as images. Experiments on the CelebA dataset show that our method uncovers a rich set of semantically interpretable features, allowing for high compression and strong denoising.
Diffusion Models in Simulation-Based Inference: A Tutorial Review
Dec 22, 2025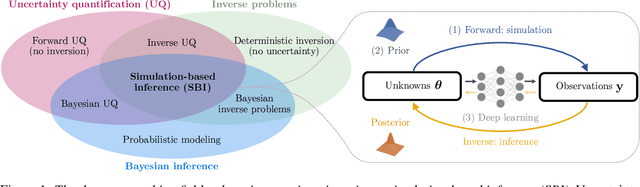

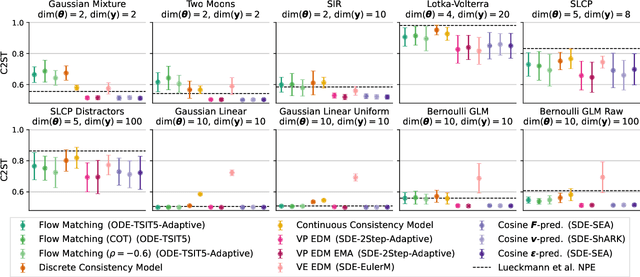
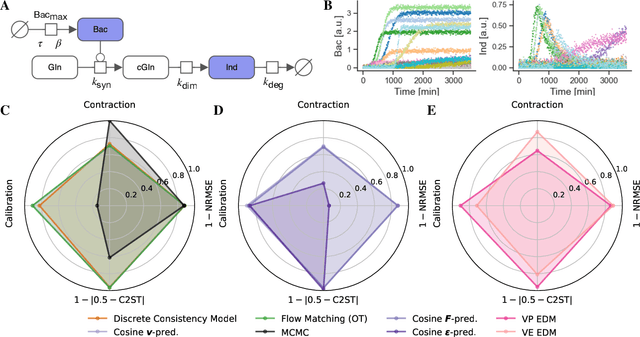
Diffusion models have recently emerged as powerful learners for simulation-based inference (SBI), enabling fast and accurate estimation of latent parameters from simulated and real data. Their score-based formulation offers a flexible way to learn conditional or joint distributions over parameters and observations, thereby providing a versatile solution to various modeling problems. In this tutorial review, we synthesize recent developments on diffusion models for SBI, covering design choices for training, inference, and evaluation. We highlight opportunities created by various concepts such as guidance, score composition, flow matching, consistency models, and joint modeling. Furthermore, we discuss how efficiency and statistical accuracy are affected by noise schedules, parameterizations, and samplers. Finally, we illustrate these concepts with case studies across parameter dimensionalities, simulation budgets, and model types, and outline open questions for future research.
OOD Detection with immature Models
Feb 02, 2025



Likelihood-based deep generative models (DGMs) have gained significant attention for their ability to approximate the distributions of high-dimensional data. However, these models lack a performance guarantee in assigning higher likelihood values to in-distribution (ID) inputs, data the models are trained on, compared to out-of-distribution (OOD) inputs. This counter-intuitive behaviour is particularly pronounced when ID inputs are more complex than OOD data points. One potential approach to address this challenge involves leveraging the gradient of a data point with respect to the parameters of the DGMs. A recent OOD detection framework proposed estimating the joint density of layer-wise gradient norms for a given data point as a model-agnostic method, demonstrating superior performance compared to the Typicality Test across likelihood-based DGMs and image dataset pairs. In particular, most existing methods presuppose access to fully converged models, the training of which is both time-intensive and computationally demanding. In this work, we demonstrate that using immature models,stopped at early stages of training, can mostly achieve equivalent or even superior results on this downstream task compared to mature models capable of generating high-quality samples that closely resemble ID data. This novel finding enhances our understanding of how DGMs learn the distribution of ID data and highlights the potential of leveraging partially trained models for downstream tasks. Furthermore, we offer a possible explanation for this unexpected behaviour through the concept of support overlap.
TRADE: Transfer of Distributions between External Conditions with Normalizing Flows
Oct 25, 2024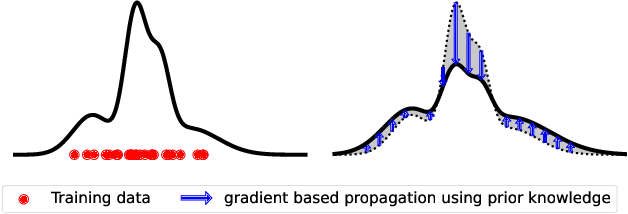



Modeling distributions that depend on external control parameters is a common scenario in diverse applications like molecular simulations, where system properties like temperature affect molecular configurations. Despite the relevance of these applications, existing solutions are unsatisfactory as they require severely restricted model architectures or rely on backward training, which is prone to unstable training. We introduce TRADE, which overcomes these limitations by formulating the learning process as a boundary value problem. By initially training the model for a specific condition using either i.i.d. samples or backward KL training, we establish a boundary distribution. We then propagate this information across other conditions using the gradient of the unnormalized density with respect to the external parameter. This formulation, akin to the principles of physics-informed neural networks, allows us to efficiently learn parameter-dependent distributions without restrictive assumptions. Experimentally, we demonstrate that TRADE achieves excellent results in a wide range of applications, ranging from Bayesian inference and molecular simulations to physical lattice models.
Analyzing Generative Models by Manifold Entropic Metrics
Oct 25, 2024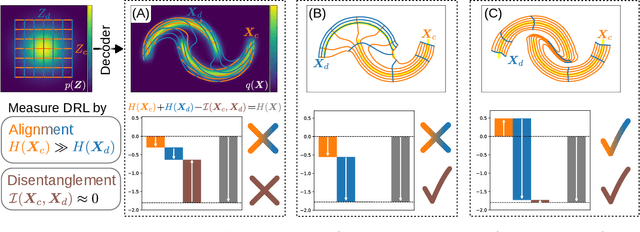
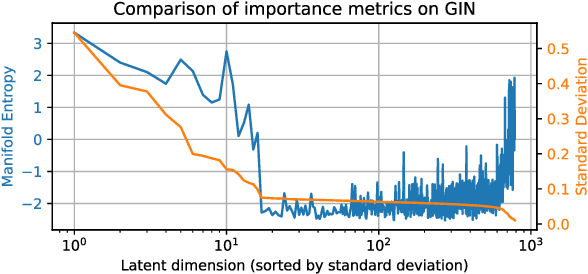
Good generative models should not only synthesize high quality data, but also utilize interpretable representations that aid human understanding of their behavior. However, it is difficult to measure objectively if and to what degree desirable properties of disentangled representations have been achieved. Inspired by the principle of independent mechanisms, we address this difficulty by introducing a novel set of tractable information-theoretic evaluation metrics. We demonstrate the usefulness of our metrics on illustrative toy examples and conduct an in-depth comparison of various normalizing flow architectures and $\beta$-VAEs on the EMNIST dataset. Our method allows to sort latent features by importance and assess the amount of residual correlations of the resulting concepts. The most interesting finding of our experiments is a ranking of model architectures and training procedures in terms of their inductive bias to converge to aligned and disentangled representations during training.
Learning Distances from Data with Normalizing Flows and Score Matching
Jul 12, 2024



Density-based distances (DBDs) offer an elegant solution to the problem of metric learning. By defining a Riemannian metric which increases with decreasing probability density, shortest paths naturally follow the data manifold and points are clustered according to the modes of the data. We show that existing methods to estimate Fermat distances, a particular choice of DBD, suffer from poor convergence in both low and high dimensions due to i) inaccurate density estimates and ii) reliance on graph-based paths which are increasingly rough in high dimensions. To address these issues, we propose learning the densities using a normalizing flow, a generative model with tractable density estimation, and employing a smooth relaxation method using a score model initialized from a graph-based proposal. Additionally, we introduce a dimension-adapted Fermat distance that exhibits more intuitive behavior when scaled to high dimensions and offers better numerical properties. Our work paves the way for practical use of density-based distances, especially in high-dimensional spaces.
Deciphering the Definition of Adversarial Robustness for post-hoc OOD Detectors
Jun 25, 2024



Detecting out-of-distribution (OOD) inputs is critical for safely deploying deep learning models in real-world scenarios. In recent years, many OOD detectors have been developed, and even the benchmarking has been standardized, i.e. OpenOOD. The number of post-hoc detectors is growing fast and showing an option to protect a pre-trained classifier against natural distribution shifts, claiming to be ready for real-world scenarios. However, its efficacy in handling adversarial examples has been neglected in the majority of studies. This paper investigates the adversarial robustness of the 16 post-hoc detectors on several evasion attacks and discuss a roadmap towards adversarial defense in OOD detectors.
Detecting Model Misspecification in Amortized Bayesian Inference with Neural Networks: An Extended Investigation
Jun 06, 2024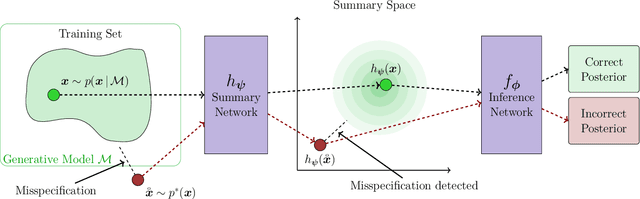

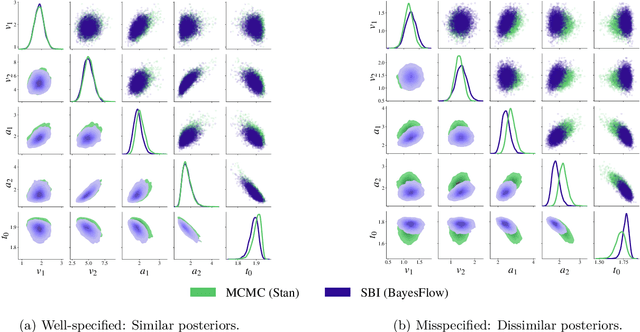

Recent advances in probabilistic deep learning enable efficient amortized Bayesian inference in settings where the likelihood function is only implicitly defined by a simulation program (simulation-based inference; SBI). But how faithful is such inference if the simulation represents reality somewhat inaccurately, that is, if the true system behavior at test time deviates from the one seen during training? We conceptualize the types of such model misspecification arising in SBI and systematically investigate how the performance of neural posterior approximators gradually deteriorates as a consequence, making inference results less and less trustworthy. To notify users about this problem, we propose a new misspecification measure that can be trained in an unsupervised fashion (i.e., without training data from the true distribution) and reliably detects model misspecification at test time. Our experiments clearly demonstrate the utility of our new measure both on toy examples with an analytical ground-truth and on representative scientific tasks in cell biology, cognitive decision making, disease outbreak dynamics, and computer vision. We show how the proposed misspecification test warns users about suspicious outputs, raises an alarm when predictions are not trustworthy, and guides model designers in their search for better simulators.