 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDALSA: Domain Adaptation for Supervised Learning From Sparsely Annotated MR Images
Mar 12, 2024
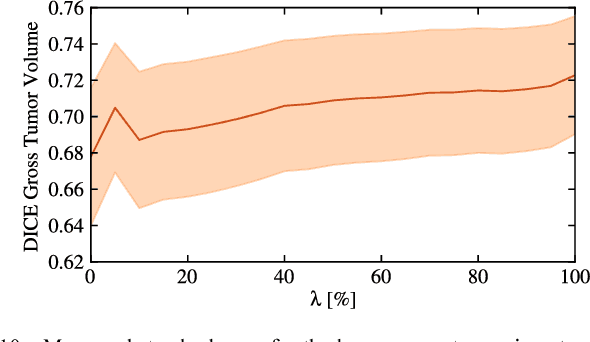

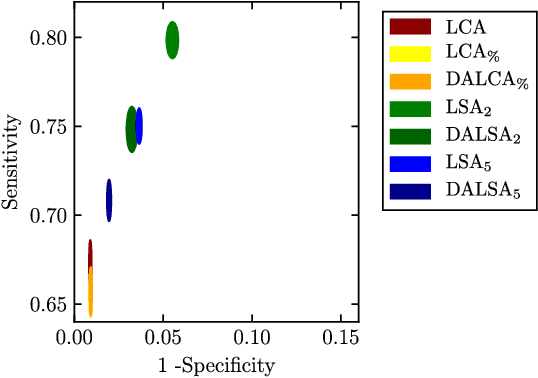
We propose a new method that employs transfer learning techniques to effectively correct sampling selection errors introduced by sparse annotations during supervised learning for automated tumor segmentation. The practicality of current learning-based automated tissue classification approaches is severely impeded by their dependency on manually segmented training databases that need to be recreated for each scenario of application, site, or acquisition setup. The comprehensive annotation of reference datasets can be highly labor-intensive, complex, and error-prone. The proposed method derives high-quality classifiers for the different tissue classes from sparse and unambiguous annotations and employs domain adaptation techniques for effectively correcting sampling selection errors introduced by the sparse sampling. The new approach is validated on labeled, multi-modal MR images of 19 patients with malignant gliomas and by comparative analysis on the BraTS 2013 challenge data sets. Compared to training on fully labeled data, we reduced the time for labeling and training by a factor greater than 70 and 180 respectively without sacrificing accuracy. This dramatically eases the establishment and constant extension of large annotated databases in various scenarios and imaging setups and thus represents an important step towards practical applicability of learning-based approaches in tissue classification.