 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFunnyNodules: A Customizable Medical Dataset Tailored for Evaluating Explainable AI
Nov 19, 2025Densely annotated medical image datasets that capture not only diagnostic labels but also the underlying reasoning behind these diagnoses are scarce. Such reasoning-related annotations are essential for developing and evaluating explainable AI (xAI) models that reason similarly to radiologists: making correct predictions for the right reasons. To address this gap, we introduce FunnyNodules, a fully parameterized synthetic dataset designed for systematic analysis of attribute-based reasoning in medical AI models. The dataset generates abstract, lung nodule-like shapes with controllable visual attributes such as roundness, margin sharpness, and spiculation. Target class is derived from a predefined attribute combination, allowing full control over the decision rule that links attributes to the diagnostic class. We demonstrate how FunnyNodules can be used in model-agnostic evaluations to assess whether models learn correct attribute-target relations, to interpret over- or underperformance in attribute prediction, and to analyze attention alignment with attribute-specific regions of interest. The framework is fully customizable, supporting variations in dataset complexity, target definitions, class balance, and beyond. With complete ground truth information, FunnyNodules provides a versatile foundation for developing, benchmarking, and conducting in-depth analyses of explainable AI methods in medical image analysis.
Minimum Data, Maximum Impact: 20 annotated samples for explainable lung nodule classification
Aug 01, 2025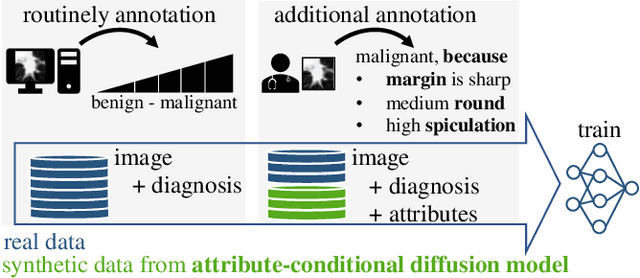
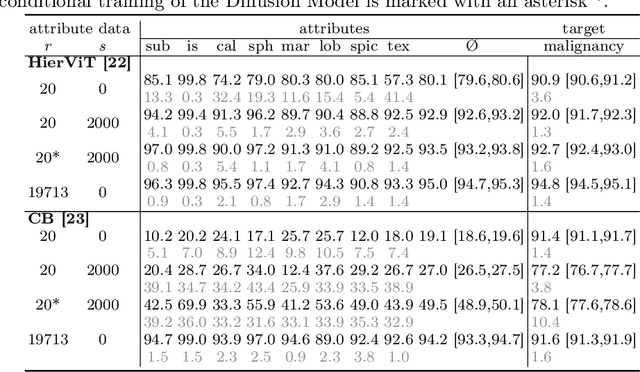
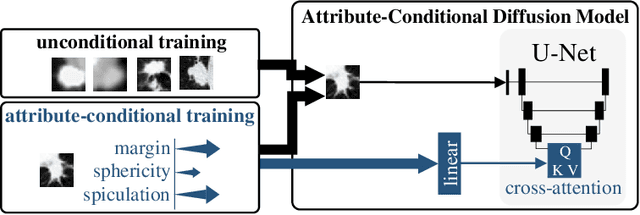
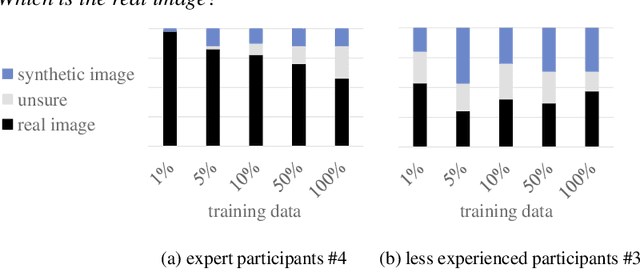
Classification models that provide human-interpretable explanations enhance clinicians' trust and usability in medical image diagnosis. One research focus is the integration and prediction of pathology-related visual attributes used by radiologists alongside the diagnosis, aligning AI decision-making with clinical reasoning. Radiologists use attributes like shape and texture as established diagnostic criteria and mirroring these in AI decision-making both enhances transparency and enables explicit validation of model outputs. However, the adoption of such models is limited by the scarcity of large-scale medical image datasets annotated with these attributes. To address this challenge, we propose synthesizing attribute-annotated data using a generative model. We enhance the Diffusion Model with attribute conditioning and train it using only 20 attribute-labeled lung nodule samples from the LIDC-IDRI dataset. Incorporating its generated images into the training of an explainable model boosts performance, increasing attribute prediction accuracy by 13.4% and target prediction accuracy by 1.8% compared to training with only the small real attribute-annotated dataset. This work highlights the potential of synthetic data to overcome dataset limitations, enhancing the applicability of explainable models in medical image analysis.
Enhanced Diagnostic Fidelity in Pathology Whole Slide Image Compression via Deep Learning
Mar 14, 2025Accurate diagnosis of disease often depends on the exhaustive examination of Whole Slide Images (WSI) at microscopic resolution. Efficient handling of these data-intensive images requires lossy compression techniques. This paper investigates the limitations of the widely-used JPEG algorithm, the current clinical standard, and reveals severe image artifacts impacting diagnostic fidelity. To overcome these challenges, we introduce a novel deep-learning (DL)-based compression method tailored for pathology images. By enforcing feature similarity of deep features between the original and compressed images, our approach achieves superior Peak Signal-to-Noise Ratio (PSNR), Multi-Scale Structural Similarity Index (MS-SSIM), and Learned Perceptual Image Patch Similarity (LPIPS) scores compared to JPEG-XL, Webp, and other DL compression methods.
Hierarchical Vision Transformer with Prototypes for Interpretable Medical Image Classification
Feb 13, 2025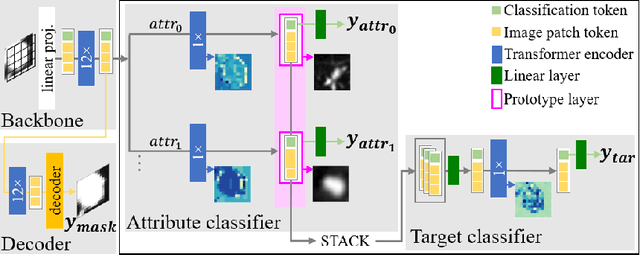
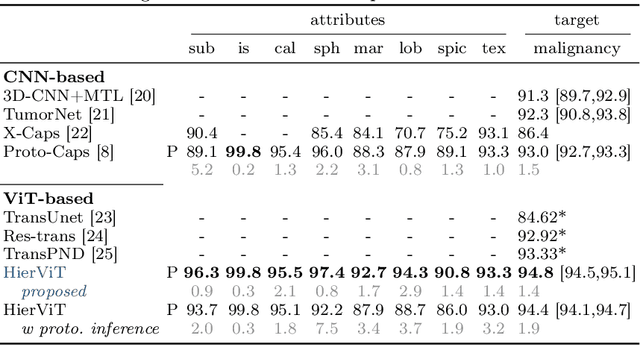

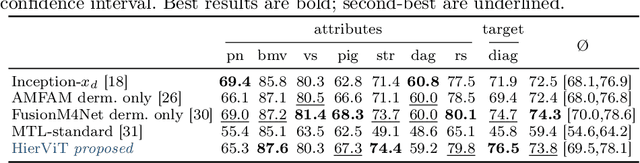
Explainability is a highly demanded requirement for applications in high-risk areas such as medicine. Vision Transformers have mainly been limited to attention extraction to provide insight into the model's reasoning. Our approach combines the high performance of Vision Transformers with the introduction of new explainability capabilities. We present HierViT, a Vision Transformer that is inherently interpretable and adapts its reasoning to that of humans. A hierarchical structure is used to process domain-specific features for prediction. It is interpretable by design, as it derives the target output with human-defined features that are visualized by exemplary images (prototypes). By incorporating domain knowledge about these decisive features, the reasoning is semantically similar to human reasoning and therefore intuitive. Moreover, attention heatmaps visualize the crucial regions for identifying each feature, thereby providing HierViT with a versatile tool for validating predictions. Evaluated on two medical benchmark datasets, LIDC-IDRI for lung nodule assessment and derm7pt for skin lesion classification, HierViT achieves superior and comparable prediction accuracy, respectively, while offering explanations that align with human reasoning.
Unlocking the Potential of Digital Pathology: Novel Baselines for Compression
Dec 17, 2024



Digital pathology offers a groundbreaking opportunity to transform clinical practice in histopathological image analysis, yet faces a significant hurdle: the substantial file sizes of pathological Whole Slide Images (WSI). While current digital pathology solutions rely on lossy JPEG compression to address this issue, lossy compression can introduce color and texture disparities, potentially impacting clinical decision-making. While prior research addresses perceptual image quality and downstream performance independently of each other, we jointly evaluate compression schemes for perceptual and downstream task quality on four different datasets. In addition, we collect an initially uncompressed dataset for an unbiased perceptual evaluation of compression schemes. Our results show that deep learning models fine-tuned for perceptual quality outperform conventional compression schemes like JPEG-XL or WebP for further compression of WSI. However, they exhibit a significant bias towards the compression artifacts present in the training data and struggle to generalize across various compression schemes. We introduce a novel evaluation metric based on feature similarity between original files and compressed files that aligns very well with the actual downstream performance on the compressed WSI. Our metric allows for a general and standardized evaluation of lossy compression schemes and mitigates the requirement to independently assess different downstream tasks. Our study provides novel insights for the assessment of lossy compression schemes for WSI and encourages a unified evaluation of lossy compression schemes to accelerate the clinical uptake of digital pathology.
Less is More: Selective Reduction of CT Data for Self-Supervised Pre-Training of Deep Learning Models with Contrastive Learning Improves Downstream Classification Performance
Oct 18, 2024Self-supervised pre-training of deep learning models with contrastive learning is a widely used technique in image analysis. Current findings indicate a strong potential for contrastive pre-training on medical images. However, further research is necessary to incorporate the particular characteristics of these images. We hypothesize that the similarity of medical images hinders the success of contrastive learning in the medical imaging domain. To this end, we investigate different strategies based on deep embedding, information theory, and hashing in order to identify and reduce redundancy in medical pre-training datasets. The effect of these different reduction strategies on contrastive learning is evaluated on two pre-training datasets and several downstream classification tasks. In all of our experiments, dataset reduction leads to a considerable performance gain in downstream tasks, e.g., an AUC score improvement from 0.78 to 0.83 for the COVID CT Classification Grand Challenge, 0.97 to 0.98 for the OrganSMNIST Classification Challenge and 0.73 to 0.83 for a brain hemorrhage classification task. Furthermore, pre-training is up to nine times faster due to the dataset reduction. In conclusion, the proposed approach highlights the importance of dataset quality and provides a transferable approach to improve contrastive pre-training for classification downstream tasks on medical images.
* Published in Computers in Biology and Medicine
Learned Image Compression for HE-stained Histopathological Images via Stain Deconvolution
Jun 18, 2024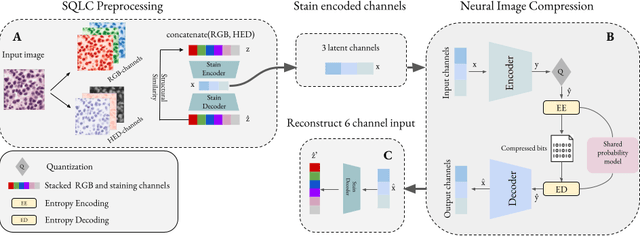
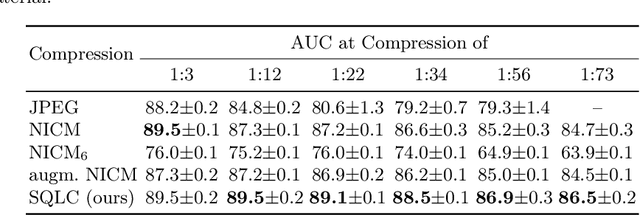
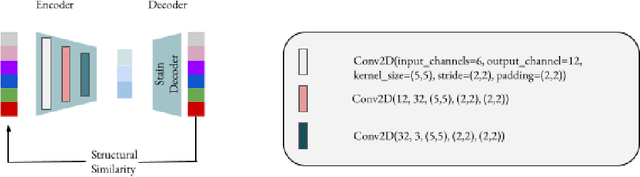
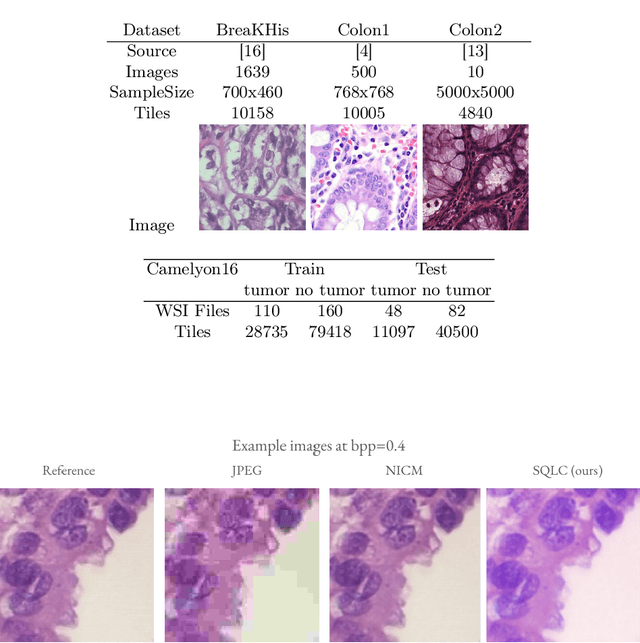
Processing histopathological Whole Slide Images (WSI) leads to massive storage requirements for clinics worldwide. Even after lossy image compression during image acquisition, additional lossy compression is frequently possible without substantially affecting the performance of deep learning-based (DL) downstream tasks. In this paper, we show that the commonly used JPEG algorithm is not best suited for further compression and we propose Stain Quantized Latent Compression (SQLC ), a novel DL based histopathology data compression approach. SQLC compresses staining and RGB channels before passing it through a compression autoencoder (CAE ) in order to obtain quantized latent representations for maximizing the compression. We show that our approach yields superior performance in a classification downstream task, compared to traditional approaches like JPEG, while image quality metrics like the Multi-Scale Structural Similarity Index (MS-SSIM) is largely preserved. Our method is online available.
Evaluating the Explainability of Attributes and Prototypes for a Medical Classification Model
Apr 15, 2024Due to the sensitive nature of medicine, it is particularly important and highly demanded that AI methods are explainable. This need has been recognised and there is great research interest in xAI solutions with medical applications. However, there is a lack of user-centred evaluation regarding the actual impact of the explanations. We evaluate attribute- and prototype-based explanations with the Proto-Caps model. This xAI model reasons the target classification with human-defined visual features of the target object in the form of scores and attribute-specific prototypes. The model thus provides a multimodal explanation that is intuitively understandable to humans thanks to predefined attributes. A user study involving six radiologists shows that the explanations are subjectivly perceived as helpful, as they reflect their decision-making process. The results of the model are considered a second opinion that radiologists can discuss using the model's explanations. However, it was shown that the inclusion and increased magnitude of model explanations objectively can increase confidence in the model's predictions when the model is incorrect. We can conclude that attribute scores and visual prototypes enhance confidence in the model. However, additional development and repeated user studies are needed to tailor the explanation to the respective use case.
Pre-examinations Improve Automated Metastases Detection on Cranial MRI
Mar 13, 2024Materials and methods: First, a dual-time approach was assessed, for which the CNN was provided sequences of the MRI that initially depicted new MM (diagnosis MRI) as well as of a prediagnosis MRI: inclusion of only contrast-enhanced T1-weighted images (CNNdual_ce) was compared with inclusion of also the native T1-weighted images, T2-weighted images, and FLAIR sequences of both time points (CNNdual_all).Second, results were compared with the corresponding single time approaches, in which the CNN was provided exclusively the respective sequences of the diagnosis MRI.Casewise diagnostic performance parameters were calculated from 5-fold cross-validation. Results: In total, 94 cases with 494 MMs were included. Overall, the highest diagnostic performance was achieved by inclusion of only the contrast-enhanced T1-weighted images of the diagnosis and of a prediagnosis MRI (CNNdual_ce, sensitivity = 73%, PPV = 25%, F1-score = 36%). Using exclusively contrast-enhanced T1-weighted images as input resulted in significantly less false-positives (FPs) compared with inclusion of further sequences beyond contrast-enhanced T1-weighted images (FPs = 5/7 for CNNdual_ce/CNNdual_all, P < 1e-5). Comparison of contrast-enhanced dual and mono time approaches revealed that exclusion of prediagnosis MRI significantly increased FPs (FPs = 5/10 for CNNdual_ce/CNNce, P < 1e-9).Approaches with only native sequences were clearly inferior to CNNs that were provided contrast-enhanced sequences. Conclusions: Automated MM detection on contrast-enhanced T1-weighted images performed with high sensitivity. Frequent FPs due to artifacts and vessels were significantly reduced by additional inclusion of prediagnosis MRI, but not by inclusion of further sequences beyond contrast-enhanced T1-weighted images. Future studies might investigate different change detection architectures for computer-aided detection.
Input Data Adaptive Learning for Sub-acute Ischemic Stroke Lesion Segmentation
Mar 12, 2024In machine learning larger databases are usually associated with higher classification accuracy due to better generalization. This generalization may lead to non-optimal classifiers in some medical applications with highly variable expressions of pathologies. This paper presents a method for learning from a large training base by adaptively selecting optimal training samples for given input data. In this way heterogeneous databases are supported two-fold. First, by being able to deal with sparsely annotated data allows a quick inclusion of new data set and second, by training an input-dependent classifier. The proposed approach is evaluated using the SISS challenge. The proposed algorithm leads to a significant improvement of the classification accuracy.