 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Vision Transformer with Prototypes for Interpretable Medical Image Classification
Paper and Code
Feb 13, 2025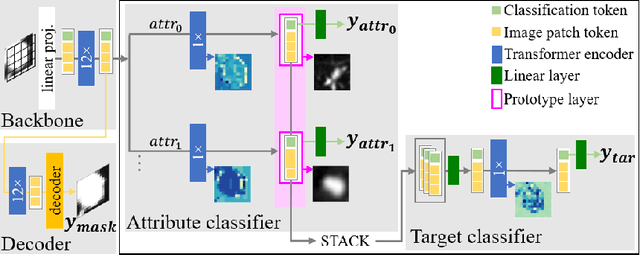
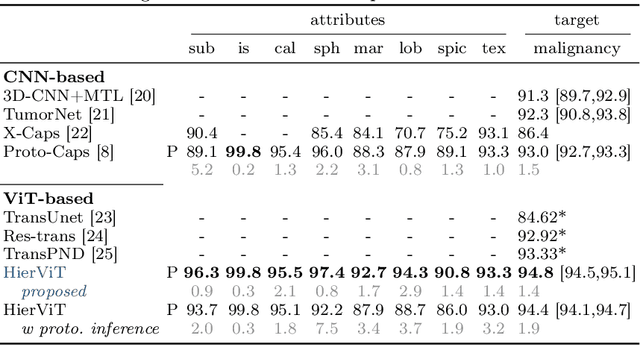

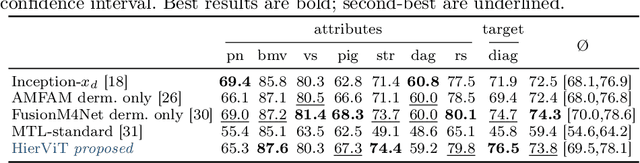
Explainability is a highly demanded requirement for applications in high-risk areas such as medicine. Vision Transformers have mainly been limited to attention extraction to provide insight into the model's reasoning. Our approach combines the high performance of Vision Transformers with the introduction of new explainability capabilities. We present HierViT, a Vision Transformer that is inherently interpretable and adapts its reasoning to that of humans. A hierarchical structure is used to process domain-specific features for prediction. It is interpretable by design, as it derives the target output with human-defined features that are visualized by exemplary images (prototypes). By incorporating domain knowledge about these decisive features, the reasoning is semantically similar to human reasoning and therefore intuitive. Moreover, attention heatmaps visualize the crucial regions for identifying each feature, thereby providing HierViT with a versatile tool for validating predictions. Evaluated on two medical benchmark datasets, LIDC-IDRI for lung nodule assessment and derm7pt for skin lesion classification, HierViT achieves superior and comparable prediction accuracy, respectively, while offering explanations that align with human reasoning.