 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrimus: Enforcing Attention Usage for 3D Medical Image Segmentation
Mar 03, 2025
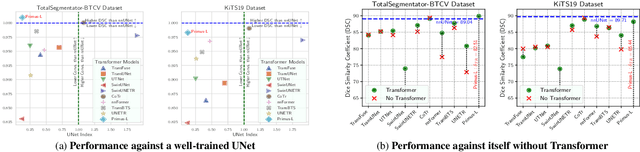
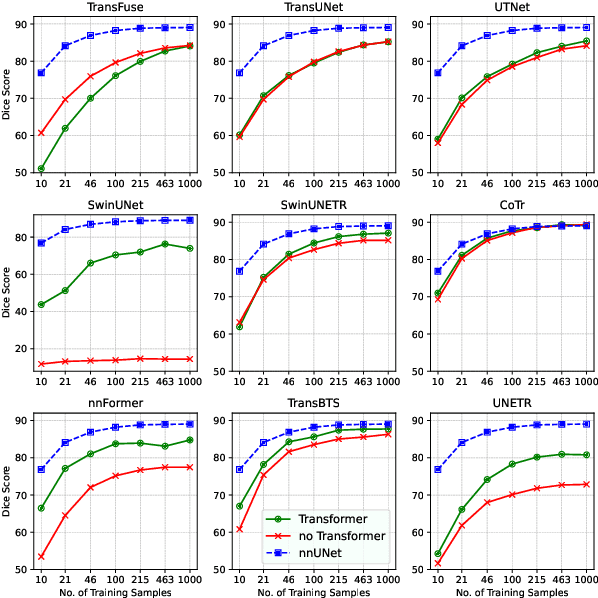
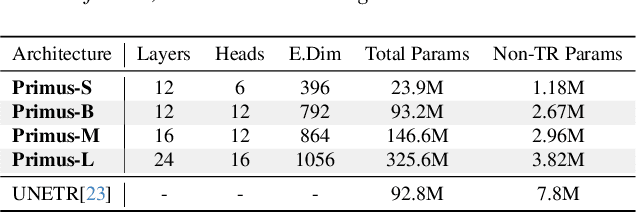
Transformers have achieved remarkable success across multiple fields, yet their impact on 3D medical image segmentation remains limited with convolutional networks still dominating major benchmarks. In this work, we a) analyze current Transformer-based segmentation models and identify critical shortcomings, particularly their over-reliance on convolutional blocks. Further, we demonstrate that in some architectures, performance is unaffected by the absence of the Transformer, thereby demonstrating their limited effectiveness. To address these challenges, we move away from hybrid architectures and b) introduce a fully Transformer-based segmentation architecture, termed Primus. Primus leverages high-resolution tokens, combined with advances in positional embeddings and block design, to maximally leverage its Transformer blocks. Through these adaptations Primus surpasses current Transformer-based methods and competes with state-of-the-art convolutional models on multiple public datasets. By doing so, we create the first pure Transformer architecture and take a significant step towards making Transformers state-of-the-art for 3D medical image segmentation.
Unlocking the Potential of Digital Pathology: Novel Baselines for Compression
Dec 17, 2024



Digital pathology offers a groundbreaking opportunity to transform clinical practice in histopathological image analysis, yet faces a significant hurdle: the substantial file sizes of pathological Whole Slide Images (WSI). While current digital pathology solutions rely on lossy JPEG compression to address this issue, lossy compression can introduce color and texture disparities, potentially impacting clinical decision-making. While prior research addresses perceptual image quality and downstream performance independently of each other, we jointly evaluate compression schemes for perceptual and downstream task quality on four different datasets. In addition, we collect an initially uncompressed dataset for an unbiased perceptual evaluation of compression schemes. Our results show that deep learning models fine-tuned for perceptual quality outperform conventional compression schemes like JPEG-XL or WebP for further compression of WSI. However, they exhibit a significant bias towards the compression artifacts present in the training data and struggle to generalize across various compression schemes. We introduce a novel evaluation metric based on feature similarity between original files and compressed files that aligns very well with the actual downstream performance on the compressed WSI. Our metric allows for a general and standardized evaluation of lossy compression schemes and mitigates the requirement to independently assess different downstream tasks. Our study provides novel insights for the assessment of lossy compression schemes for WSI and encourages a unified evaluation of lossy compression schemes to accelerate the clinical uptake of digital pathology.
Embarrassingly Simple Scribble Supervision for 3D Medical Segmentation
Mar 19, 2024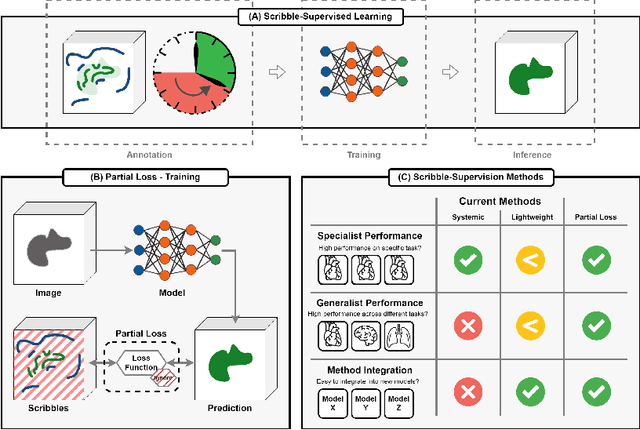
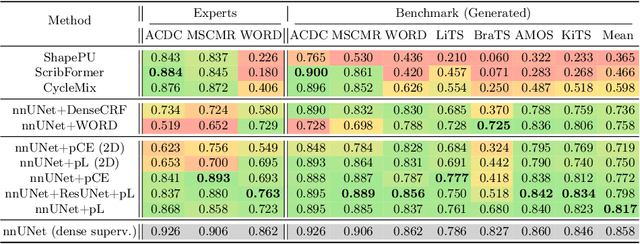
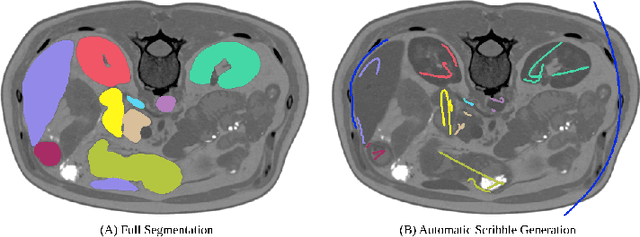

Traditionally, segmentation algorithms require dense annotations for training, demanding significant annotation efforts, particularly within the 3D medical imaging field. Scribble-supervised learning emerges as a possible solution to this challenge, promising a reduction in annotation efforts when creating large-scale datasets. Recently, a plethora of methods for optimized learning from scribbles have been proposed, but have so far failed to position scribble annotation as a beneficial alternative. We relate this shortcoming to two major issues: 1) the complex nature of many methods which deeply ties them to the underlying segmentation model, thus preventing a migration to more powerful state-of-the-art models as the field progresses and 2) the lack of a systematic evaluation to validate consistent performance across the broader medical domain, resulting in a lack of trust when applying these methods to new segmentation problems. To address these issues, we propose a comprehensive scribble supervision benchmark consisting of seven datasets covering a diverse set of anatomies and pathologies imaged with varying modalities. We furthermore propose the systematic use of partial losses, i.e. losses that are only computed on annotated voxels. Contrary to most existing methods, these losses can be seamlessly integrated into state-of-the-art segmentation methods, enabling them to learn from scribble annotations while preserving their original loss formulations. Our evaluation using nnU-Net reveals that while most existing methods suffer from a lack of generalization, the proposed approach consistently delivers state-of-the-art performance. Thanks to its simplicity, our approach presents an embarrassingly simple yet effective solution to the challenges of scribble supervision. Source code as well as our extensive scribble benchmarking suite will be made publicly available upon publication.
Precise Energy Consumption Measurements of Heterogeneous Artificial Intelligence Workloads
Dec 03, 2022



With the rise of AI in recent years and the increase in complexity of the models, the growing demand in computational resources is starting to pose a significant challenge. The need for higher compute power is being met with increasingly more potent accelerators and the use of large compute clusters. However, the gain in prediction accuracy from large models trained on distributed and accelerated systems comes at the price of a substantial increase in energy demand, and researchers have started questioning the environmental friendliness of such AI methods at scale. Consequently, energy efficiency plays an important role for AI model developers and infrastructure operators alike. The energy consumption of AI workloads depends on the model implementation and the utilized hardware. Therefore, accurate measurements of the power draw of AI workflows on different types of compute nodes is key to algorithmic improvements and the design of future compute clusters and hardware. To this end, we present measurements of the energy consumption of two typical applications of deep learning models on different types of compute nodes. Our results indicate that 1. deriving energy consumption directly from runtime is not accurate, but the consumption of the compute node needs to be considered regarding its composition; 2. neglecting accelerator hardware on mixed nodes results in overproportional inefficiency regarding energy consumption; 3. energy consumption of model training and inference should be considered separately - while training on GPUs outperforms all other node types regarding both runtime and energy consumption, inference on CPU nodes can be comparably efficient. One advantage of our approach is that the information on energy consumption is available to all users of the supercomputer, enabling an easy transfer to other workloads alongside a raise in user-awareness of energy consumption.
Optimizing Edge Detection for Image Segmentation with Multicut Penalties
Dec 10, 2021
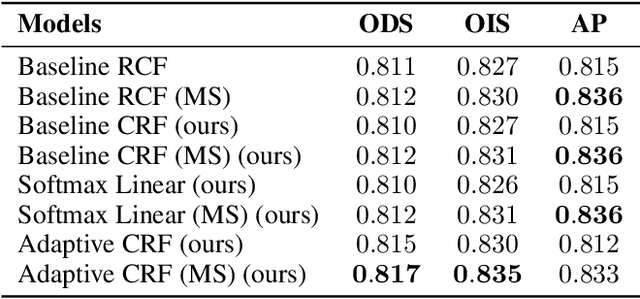
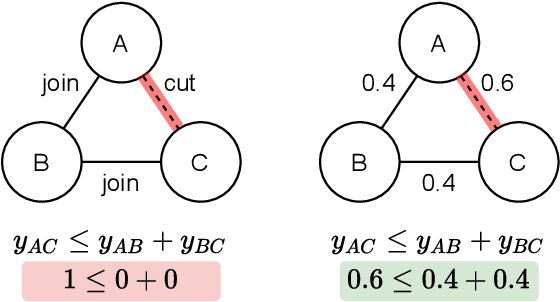

The Minimum Cost Multicut Problem (MP) is a popular way for obtaining a graph decomposition by optimizing binary edge labels over edge costs. While the formulation of a MP from independently estimated costs per edge is highly flexible and intuitive, solving the MP is NP-hard and time-expensive. As a remedy, recent work proposed to predict edge probabilities with awareness to potential conflicts by incorporating cycle constraints in the prediction process. We argue that such formulation, while providing a first step towards end-to-end learnable edge weights, is suboptimal, since it is built upon a loose relaxation of the MP. We therefore propose an adaptive CRF that allows to progressively consider more violated constraints and, in consequence, to issue solutions with higher validity. Experiments on the BSDS500 benchmark for natural image segmentation as well as on electron microscopic recordings show that our approach yields more precise edge detection and image segmentation.