 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBioimageAIpub: a toolbox for AI-ready bioimaging data publishing
Dec 17, 2025Modern bioimage analysis approaches are data hungry, making it necessary for researchers to scavenge data beyond those collected within their (bio)imaging facilities. In addition to scale, bioimaging datasets must be accompanied with suitable, high-quality annotations and metadata. Although established data repositories such as the Image Data Resource (IDR) and BioImage Archive offer rich metadata, their contents typically cannot be directly consumed by image analysis tools without substantial data wrangling. Such a tedious assembly and conversion of (meta)data can account for a dedicated amount of time investment for researchers, hindering the development of more powerful analysis tools. Here, we introduce BioimageAIpub, a workflow that streamlines bioimaging data conversion, enabling a seamless upload to HuggingFace, a widely used platform for sharing machine learning datasets and models.
Kaapana: A Comprehensive Open-Source Platform for Integrating AI in Medical Imaging Research Environments
Dec 10, 2025
Developing generalizable AI for medical imaging requires both access to large, multi-center datasets and standardized, reproducible tooling within research environments. However, leveraging real-world imaging data in clinical research environments is still hampered by strict regulatory constraints, fragmented software infrastructure, and the challenges inherent in conducting large-cohort multicentre studies. This leads to projects that rely on ad-hoc toolchains that are hard to reproduce, difficult to scale beyond single institutions and poorly suited for collaboration between clinicians and data scientists. We present Kaapana, a comprehensive open-source platform for medical imaging research that is designed to bridge this gap. Rather than building single-use, site-specific tooling, Kaapana provides a modular, extensible framework that unifies data ingestion, cohort curation, processing workflows and result inspection under a common user interface. By bringing the algorithm to the data, it enables institutions to keep control over their sensitive data while still participating in distributed experimentation and model development. By integrating flexible workflow orchestration with user-facing applications for researchers, Kaapana reduces technical overhead, improves reproducibility and enables conducting large-scale, collaborative, multi-centre imaging studies. We describe the core concepts of the platform and illustrate how they can support diverse use cases, from local prototyping to nation-wide research networks. The open-source codebase is available at https://github.com/kaapana/kaapana
Medical Image De-Identification Benchmark Challenge
Jul 31, 2025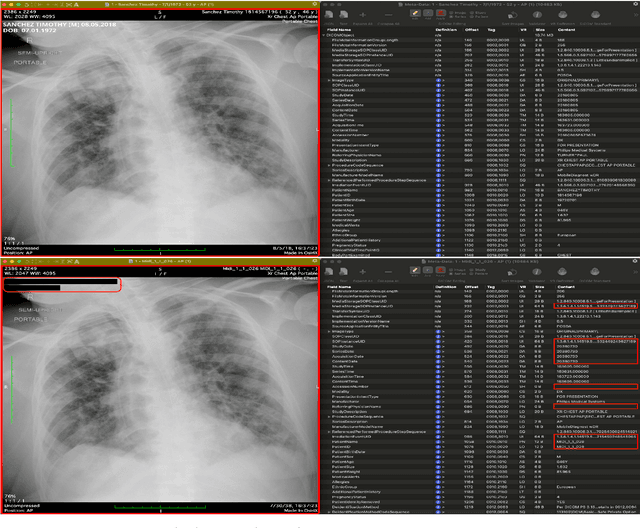
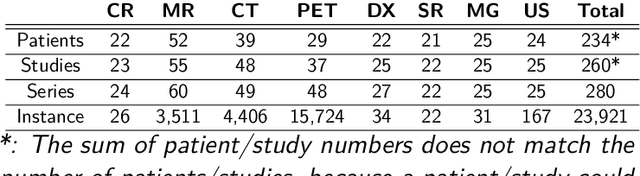
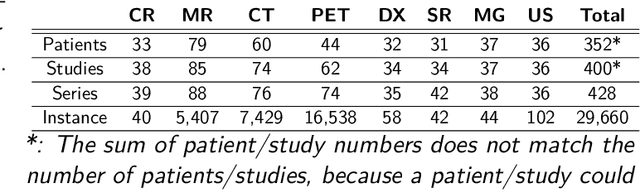
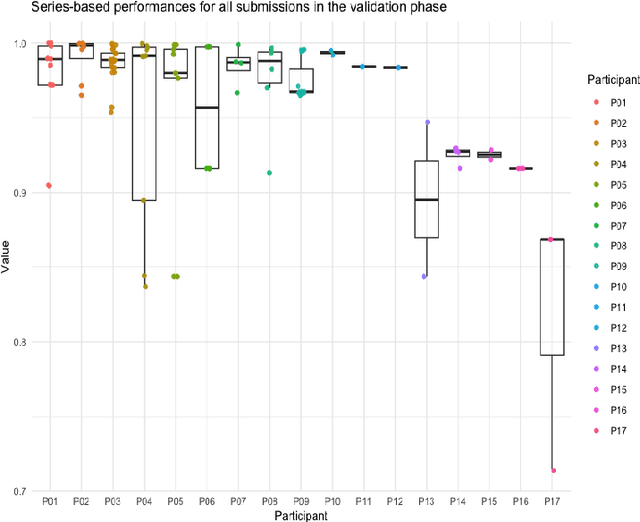
The de-identification (deID) of protected health information (PHI) and personally identifiable information (PII) is a fundamental requirement for sharing medical images, particularly through public repositories, to ensure compliance with patient privacy laws. In addition, preservation of non-PHI metadata to inform and enable downstream development of imaging artificial intelligence (AI) is an important consideration in biomedical research. The goal of MIDI-B was to provide a standardized platform for benchmarking of DICOM image deID tools based on a set of rules conformant to the HIPAA Safe Harbor regulation, the DICOM Attribute Confidentiality Profiles, and best practices in preservation of research-critical metadata, as defined by The Cancer Imaging Archive (TCIA). The challenge employed a large, diverse, multi-center, and multi-modality set of real de-identified radiology images with synthetic PHI/PII inserted. The MIDI-B Challenge consisted of three phases: training, validation, and test. Eighty individuals registered for the challenge. In the training phase, we encouraged participants to tune their algorithms using their in-house or public data. The validation and test phases utilized the DICOM images containing synthetic identifiers (of 216 and 322 subjects, respectively). Ten teams successfully completed the test phase of the challenge. To measure success of a rule-based approach to image deID, scores were computed as the percentage of correct actions from the total number of required actions. The scores ranged from 97.91% to 99.93%. Participants employed a variety of open-source and proprietary tools with customized configurations, large language models, and optical character recognition (OCR). In this paper we provide a comprehensive report on the MIDI-B Challenge's design, implementation, results, and lessons learned.
Enhanced Diagnostic Fidelity in Pathology Whole Slide Image Compression via Deep Learning
Mar 14, 2025Accurate diagnosis of disease often depends on the exhaustive examination of Whole Slide Images (WSI) at microscopic resolution. Efficient handling of these data-intensive images requires lossy compression techniques. This paper investigates the limitations of the widely-used JPEG algorithm, the current clinical standard, and reveals severe image artifacts impacting diagnostic fidelity. To overcome these challenges, we introduce a novel deep-learning (DL)-based compression method tailored for pathology images. By enforcing feature similarity of deep features between the original and compressed images, our approach achieves superior Peak Signal-to-Noise Ratio (PSNR), Multi-Scale Structural Similarity Index (MS-SSIM), and Learned Perceptual Image Patch Similarity (LPIPS) scores compared to JPEG-XL, Webp, and other DL compression methods.
Unlocking the Potential of Digital Pathology: Novel Baselines for Compression
Dec 17, 2024



Digital pathology offers a groundbreaking opportunity to transform clinical practice in histopathological image analysis, yet faces a significant hurdle: the substantial file sizes of pathological Whole Slide Images (WSI). While current digital pathology solutions rely on lossy JPEG compression to address this issue, lossy compression can introduce color and texture disparities, potentially impacting clinical decision-making. While prior research addresses perceptual image quality and downstream performance independently of each other, we jointly evaluate compression schemes for perceptual and downstream task quality on four different datasets. In addition, we collect an initially uncompressed dataset for an unbiased perceptual evaluation of compression schemes. Our results show that deep learning models fine-tuned for perceptual quality outperform conventional compression schemes like JPEG-XL or WebP for further compression of WSI. However, they exhibit a significant bias towards the compression artifacts present in the training data and struggle to generalize across various compression schemes. We introduce a novel evaluation metric based on feature similarity between original files and compressed files that aligns very well with the actual downstream performance on the compressed WSI. Our metric allows for a general and standardized evaluation of lossy compression schemes and mitigates the requirement to independently assess different downstream tasks. Our study provides novel insights for the assessment of lossy compression schemes for WSI and encourages a unified evaluation of lossy compression schemes to accelerate the clinical uptake of digital pathology.
Learned Image Compression for HE-stained Histopathological Images via Stain Deconvolution
Jun 18, 2024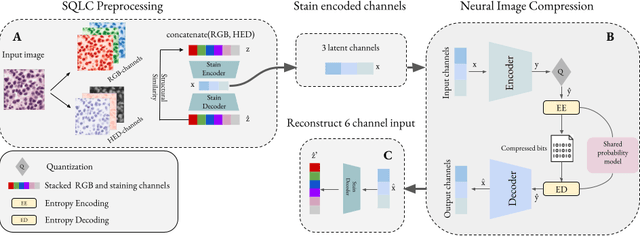
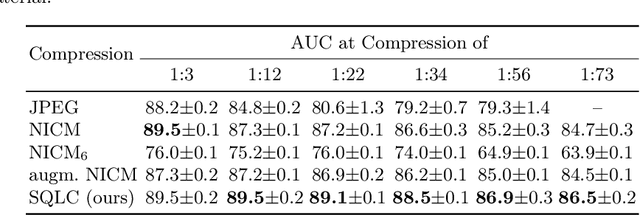
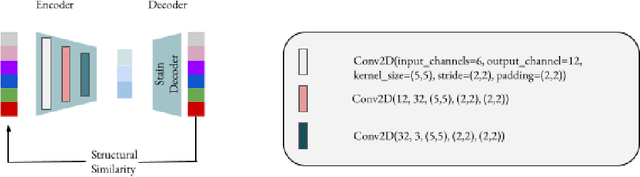
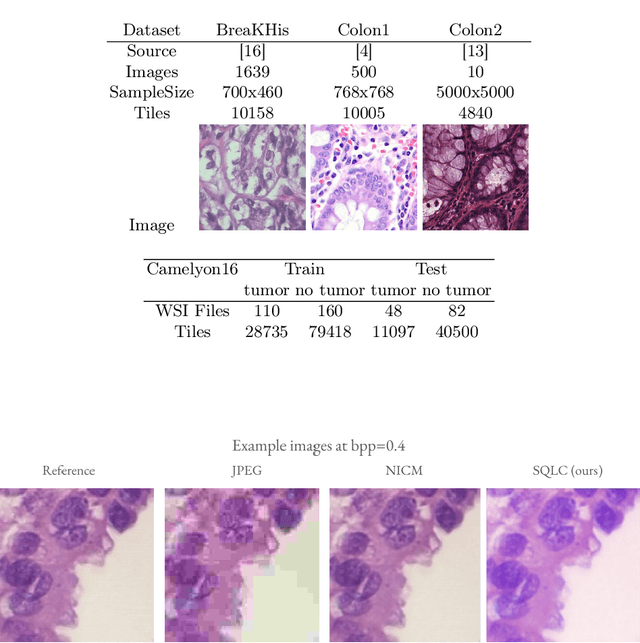
Processing histopathological Whole Slide Images (WSI) leads to massive storage requirements for clinics worldwide. Even after lossy image compression during image acquisition, additional lossy compression is frequently possible without substantially affecting the performance of deep learning-based (DL) downstream tasks. In this paper, we show that the commonly used JPEG algorithm is not best suited for further compression and we propose Stain Quantized Latent Compression (SQLC ), a novel DL based histopathology data compression approach. SQLC compresses staining and RGB channels before passing it through a compression autoencoder (CAE ) in order to obtain quantized latent representations for maximizing the compression. We show that our approach yields superior performance in a classification downstream task, compared to traditional approaches like JPEG, while image quality metrics like the Multi-Scale Structural Similarity Index (MS-SSIM) is largely preserved. Our method is online available.
cOOpD: Reformulating COPD classification on chest CT scans as anomaly detection using contrastive representations
Jul 14, 2023



Classification of heterogeneous diseases is challenging due to their complexity, variability of symptoms and imaging findings. Chronic Obstructive Pulmonary Disease (COPD) is a prime example, being underdiagnosed despite being the third leading cause of death. Its sparse, diffuse and heterogeneous appearance on computed tomography challenges supervised binary classification. We reformulate COPD binary classification as an anomaly detection task, proposing cOOpD: heterogeneous pathological regions are detected as Out-of-Distribution (OOD) from normal homogeneous lung regions. To this end, we learn representations of unlabeled lung regions employing a self-supervised contrastive pretext model, potentially capturing specific characteristics of diseased and healthy unlabeled regions. A generative model then learns the distribution of healthy representations and identifies abnormalities (stemming from COPD) as deviations. Patient-level scores are obtained by aggregating region OOD scores. We show that cOOpD achieves the best performance on two public datasets, with an increase of 8.2% and 7.7% in terms of AUROC compared to the previous supervised state-of-the-art. Additionally, cOOpD yields well-interpretable spatial anomaly maps and patient-level scores which we show to be of additional value in identifying individuals in the early stage of progression. Experiments in artificially designed real-world prevalence settings further support that anomaly detection is a powerful way of tackling COPD classification.
Precise Energy Consumption Measurements of Heterogeneous Artificial Intelligence Workloads
Dec 03, 2022



With the rise of AI in recent years and the increase in complexity of the models, the growing demand in computational resources is starting to pose a significant challenge. The need for higher compute power is being met with increasingly more potent accelerators and the use of large compute clusters. However, the gain in prediction accuracy from large models trained on distributed and accelerated systems comes at the price of a substantial increase in energy demand, and researchers have started questioning the environmental friendliness of such AI methods at scale. Consequently, energy efficiency plays an important role for AI model developers and infrastructure operators alike. The energy consumption of AI workloads depends on the model implementation and the utilized hardware. Therefore, accurate measurements of the power draw of AI workflows on different types of compute nodes is key to algorithmic improvements and the design of future compute clusters and hardware. To this end, we present measurements of the energy consumption of two typical applications of deep learning models on different types of compute nodes. Our results indicate that 1. deriving energy consumption directly from runtime is not accurate, but the consumption of the compute node needs to be considered regarding its composition; 2. neglecting accelerator hardware on mixed nodes results in overproportional inefficiency regarding energy consumption; 3. energy consumption of model training and inference should be considered separately - while training on GPUs outperforms all other node types regarding both runtime and energy consumption, inference on CPU nodes can be comparably efficient. One advantage of our approach is that the information on energy consumption is available to all users of the supercomputer, enabling an easy transfer to other workloads alongside a raise in user-awareness of energy consumption.