 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetter than Average: Spatially-Aware Aggregation of Segmentation Uncertainty Improves Downstream Performance
Mar 31, 2026Uncertainty Quantification (UQ) is crucial for ensuring the reliability of automated image segmentations in safety-critical domains like biomedical image analysis or autonomous driving. In segmentation, UQ generates pixel-wise uncertainty scores that must be aggregated into image-level scores for downstream tasks like Out-of-Distribution (OoD) or failure detection. Despite routine use of aggregation strategies, their properties and impact on downstream task performance have not yet been comprehensively studied. Global Average is the default choice, yet it does not account for spatial and structural features of segmentation uncertainty. Alternatives like patch-, class- and threshold-based strategies exist, but lack systematic comparison, leading to inconsistent reporting and unclear best practices. We address this gap by (1) formally analyzing properties, limitations, and pitfalls of common strategies; (2) proposing novel strategies that incorporate spatial uncertainty structure and (3) benchmarking their performance on OoD and failure detection across ten datasets that vary in image geometry and structure. We find that aggregators leveraging spatial structure yield stronger performance in both downstream tasks studied. However, the performance of individual aggregators depends heavily on dataset characteristics, so we (4) propose a meta-aggregator that integrates multiple aggregators and performs robustly across datasets.
Finally Outshining the Random Baseline: A Simple and Effective Solution for Active Learning in 3D Biomedical Imaging
Jan 20, 2026Active learning (AL) has the potential to drastically reduce annotation costs in 3D biomedical image segmentation, where expert labeling of volumetric data is both time-consuming and expensive. Yet, existing AL methods are unable to consistently outperform improved random sampling baselines adapted to 3D data, leaving the field without a reliable solution. We introduce Class-stratified Scheduled Power Predictive Entropy (ClaSP PE), a simple and effective query strategy that addresses two key limitations of standard uncertainty-based AL methods: class imbalance and redundancy in early selections. ClaSP PE combines class-stratified querying to ensure coverage of underrepresented structures and log-scale power noising with a decaying schedule to enforce query diversity in early-stage AL and encourage exploitation later. In our evaluation on 24 experimental settings using four 3D biomedical datasets within the comprehensive nnActive benchmark, ClaSP PE is the only method that generally outperforms improved random baselines in terms of both segmentation quality with statistically significant gains, whilst remaining annotation efficient. Furthermore, we explicitly simulate the real-world application by testing our method on four previously unseen datasets without manual adaptation, where all experiment parameters are set according to predefined guidelines. The results confirm that ClaSP PE robustly generalizes to novel tasks without requiring dataset-specific tuning. Within the nnActive framework, we present compelling evidence that an AL method can consistently outperform random baselines adapted to 3D segmentation, in terms of both performance and annotation efficiency in a realistic, close-to-production scenario. Our open-source implementation and clear deployment guidelines make it readily applicable in practice. Code is at https://github.com/MIC-DKFZ/nnActive.
SURE-VQA: Systematic Understanding of Robustness Evaluation in Medical VQA Tasks
Nov 29, 2024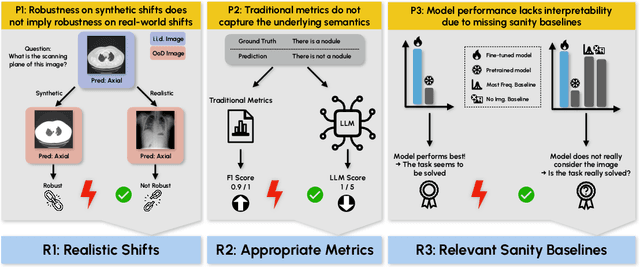
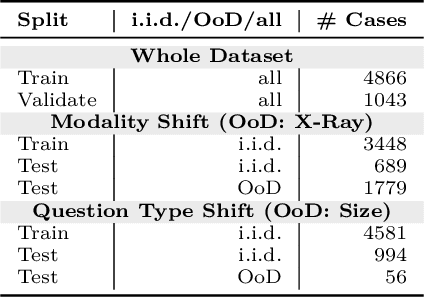
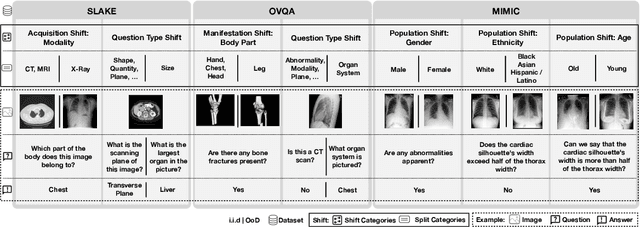

Vision-Language Models (VLMs) have great potential in medical tasks, like Visual Question Answering (VQA), where they could act as interactive assistants for both patients and clinicians. Yet their robustness to distribution shifts on unseen data remains a critical concern for safe deployment. Evaluating such robustness requires a controlled experimental setup that allows for systematic insights into the model's behavior. However, we demonstrate that current setups fail to offer sufficiently thorough evaluations, limiting their ability to accurately assess model robustness. To address this gap, our work introduces a novel framework, called SURE-VQA, centered around three key requirements to overcome the current pitfalls and systematically analyze the robustness of VLMs: 1) Since robustness on synthetic shifts does not necessarily translate to real-world shifts, robustness should be measured on real-world shifts that are inherent to the VQA data; 2) Traditional token-matching metrics often fail to capture underlying semantics, necessitating the use of large language models (LLMs) for more accurate semantic evaluation; 3) Model performance often lacks interpretability due to missing sanity baselines, thus meaningful baselines should be reported that allow assessing the multimodal impact on the VLM. To demonstrate the relevance of this framework, we conduct a study on the robustness of various fine-tuning methods across three medical datasets with four different types of distribution shifts. Our study reveals several important findings: 1) Sanity baselines that do not utilize image data can perform surprisingly well; 2) We confirm LoRA as the best-performing PEFT method; 3) No PEFT method consistently outperforms others in terms of robustness to shifts. Code is provided at https://github.com/IML-DKFZ/sure-vqa.
Navigating the Maze of Explainable AI: A Systematic Approach to Evaluating Methods and Metrics
Sep 25, 2024Explainable AI (XAI) is a rapidly growing domain with a myriad of proposed methods as well as metrics aiming to evaluate their efficacy. However, current studies are often of limited scope, examining only a handful of XAI methods and ignoring underlying design parameters for performance, such as the model architecture or the nature of input data. Moreover, they often rely on one or a few metrics and neglect thorough validation, increasing the risk of selection bias and ignoring discrepancies among metrics. These shortcomings leave practitioners confused about which method to choose for their problem. In response, we introduce LATEC, a large-scale benchmark that critically evaluates 17 prominent XAI methods using 20 distinct metrics. We systematically incorporate vital design parameters like varied architectures and diverse input modalities, resulting in 7,560 examined combinations. Through LATEC, we showcase the high risk of conflicting metrics leading to unreliable rankings and consequently propose a more robust evaluation scheme. Further, we comprehensively evaluate various XAI methods to assist practitioners in selecting appropriate methods aligning with their needs. Curiously, the emerging top-performing method, Expected Gradients, is not examined in any relevant related study. LATEC reinforces its role in future XAI research by publicly releasing all 326k saliency maps and 378k metric scores as a (meta-)evaluation dataset.
Overcoming Common Flaws in the Evaluation of Selective Classification Systems
Jul 01, 2024



Selective Classification, wherein models can reject low-confidence predictions, promises reliable translation of machine-learning based classification systems to real-world scenarios such as clinical diagnostics. While current evaluation of these systems typically assumes fixed working points based on pre-defined rejection thresholds, methodological progress requires benchmarking the general performance of systems akin to the $\mathrm{AUROC}$ in standard classification. In this work, we define 5 requirements for multi-threshold metrics in selective classification regarding task alignment, interpretability, and flexibility, and show how current approaches fail to meet them. We propose the Area under the Generalized Risk Coverage curve ($\mathrm{AUGRC}$), which meets all requirements and can be directly interpreted as the average risk of undetected failures. We empirically demonstrate the relevance of $\mathrm{AUGRC}$ on a comprehensive benchmark spanning 6 data sets and 13 confidence scoring functions. We find that the proposed metric substantially changes metric rankings on 5 out of the 6 data sets.
ValUES: A Framework for Systematic Validation of Uncertainty Estimation in Semantic Segmentation
Jan 16, 2024



Uncertainty estimation is an essential and heavily-studied component for the reliable application of semantic segmentation methods. While various studies exist claiming methodological advances on the one hand, and successful application on the other hand, the field is currently hampered by a gap between theory and practice leaving fundamental questions unanswered: Can data-related and model-related uncertainty really be separated in practice? Which components of an uncertainty method are essential for real-world performance? Which uncertainty method works well for which application? In this work, we link this research gap to a lack of systematic and comprehensive evaluation of uncertainty methods. Specifically, we identify three key pitfalls in current literature and present an evaluation framework that bridges the research gap by providing 1) a controlled environment for studying data ambiguities as well as distribution shifts, 2) systematic ablations of relevant method components, and 3) test-beds for the five predominant uncertainty applications: OoD-detection, active learning, failure detection, calibration, and ambiguity modeling. Empirical results on simulated as well as real-world data demonstrate how the proposed framework is able to answer the predominant questions in the field revealing for instance that 1) separation of uncertainty types works on simulated data but does not necessarily translate to real-world data, 2) aggregation of scores is a crucial but currently neglected component of uncertainty methods, 3) While ensembles are performing most robustly across the different downstream tasks and settings, test-time augmentation often constitutes a light-weight alternative. Code is at: https://github.com/IML-DKFZ/values
cOOpD: Reformulating COPD classification on chest CT scans as anomaly detection using contrastive representations
Jul 14, 2023



Classification of heterogeneous diseases is challenging due to their complexity, variability of symptoms and imaging findings. Chronic Obstructive Pulmonary Disease (COPD) is a prime example, being underdiagnosed despite being the third leading cause of death. Its sparse, diffuse and heterogeneous appearance on computed tomography challenges supervised binary classification. We reformulate COPD binary classification as an anomaly detection task, proposing cOOpD: heterogeneous pathological regions are detected as Out-of-Distribution (OOD) from normal homogeneous lung regions. To this end, we learn representations of unlabeled lung regions employing a self-supervised contrastive pretext model, potentially capturing specific characteristics of diseased and healthy unlabeled regions. A generative model then learns the distribution of healthy representations and identifies abnormalities (stemming from COPD) as deviations. Patient-level scores are obtained by aggregating region OOD scores. We show that cOOpD achieves the best performance on two public datasets, with an increase of 8.2% and 7.7% in terms of AUROC compared to the previous supervised state-of-the-art. Additionally, cOOpD yields well-interpretable spatial anomaly maps and patient-level scores which we show to be of additional value in identifying individuals in the early stage of progression. Experiments in artificially designed real-world prevalence settings further support that anomaly detection is a powerful way of tackling COPD classification.
Toward Realistic Evaluation of Deep Active Learning Algorithms in Image Classification
Jan 25, 2023



Active Learning (AL) aims to reduce the labeling burden by interactively querying the most informative observations from a data pool. Despite extensive research on improving AL query methods in the past years, recent studies have questioned the advantages of AL, especially in the light of emerging alternative training paradigms such as semi-supervised (Semi-SL) and self-supervised learning (Self-SL). Thus, today's AL literature paints an inconsistent picture and leaves practitioners wondering whether and how to employ AL in their tasks. We argue that this heterogeneous landscape is caused by a lack of a systematic and realistic evaluation of AL algorithms, including key parameters such as complex and imbalanced datasets, realistic labeling scenarios, systematic method configuration, and integration of Semi-SL and Self-SL. To this end, we present an AL benchmarking suite and run extensive experiments on five datasets shedding light on the questions: when and how to apply AL?
CRADL: Contrastive Representations for Unsupervised Anomaly Detection and Localization
Jan 05, 2023



Unsupervised anomaly detection in medical imaging aims to detect and localize arbitrary anomalies without requiring annotated anomalous data during training. Often, this is achieved by learning a data distribution of normal samples and detecting anomalies as regions in the image which deviate from this distribution. Most current state-of-the-art methods use latent variable generative models operating directly on the images. However, generative models have been shown to mostly capture low-level features, s.a. pixel-intensities, instead of rich semantic features, which also applies to their representations. We circumvent this problem by proposing CRADL whose core idea is to model the distribution of normal samples directly in the low-dimensional representation space of an encoder trained with a contrastive pretext-task. By utilizing the representations of contrastive learning, we aim to fix the over-fixation on low-level features and learn more semantic-rich representations. Our experiments on anomaly detection and localization tasks using three distinct evaluation datasets show that 1) contrastive representations are superior to representations of generative latent variable models and 2) the CRADL framework shows competitive or superior performance to state-of-the-art.
A Call to Reflect on Evaluation Practices for Failure Detection in Image Classification
Nov 28, 2022
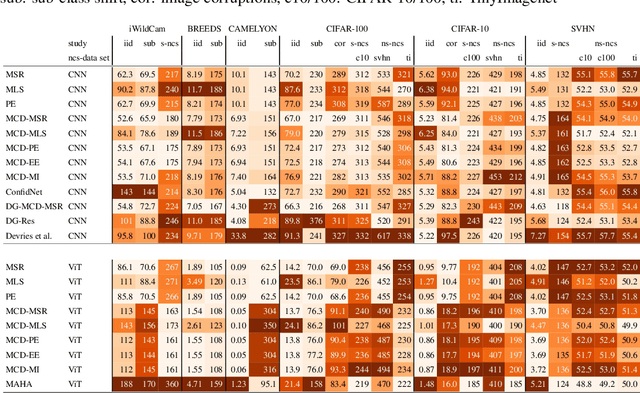
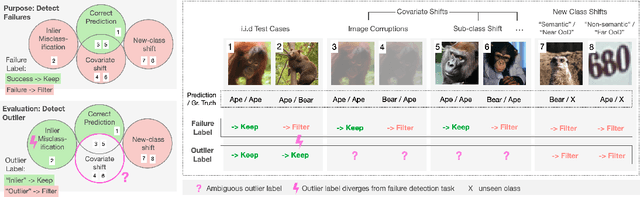
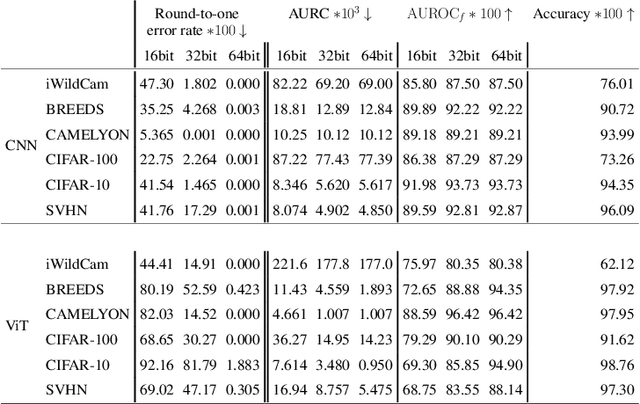
Reliable application of machine learning-based decision systems in the wild is one of the major challenges currently investigated by the field. A large portion of established approaches aims to detect erroneous predictions by means of assigning confidence scores. This confidence may be obtained by either quantifying the model's predictive uncertainty, learning explicit scoring functions, or assessing whether the input is in line with the training distribution. Curiously, while these approaches all state to address the same eventual goal of detecting failures of a classifier upon real-life application, they currently constitute largely separated research fields with individual evaluation protocols, which either exclude a substantial part of relevant methods or ignore large parts of relevant failure sources. In this work, we systematically reveal current pitfalls caused by these inconsistencies and derive requirements for a holistic and realistic evaluation of failure detection. To demonstrate the relevance of this unified perspective, we present a large-scale empirical study for the first time enabling benchmarking confidence scoring functions w.r.t all relevant methods and failure sources. The revelation of a simple softmax response baseline as the overall best performing method underlines the drastic shortcomings of current evaluation in the abundance of publicized research on confidence scoring. Code and trained models are at https://github.com/IML-DKFZ/fd-shifts.