 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCRONOS: Continuous Time Reconstruction for 4D Medical Longitudinal Series
Dec 18, 2025Forecasting how 3D medical scans evolve over time is important for disease progression, treatment planning, and developmental assessment. Yet existing models either rely on a single prior scan, fixed grid times, or target global labels, which limits voxel-level forecasting under irregular sampling. We present CRONOS, a unified framework for many-to-one prediction from multiple past scans that supports both discrete (grid-based) and continuous (real-valued) timestamps in one model, to the best of our knowledge the first to achieve continuous sequence-to-image forecasting for 3D medical data. CRONOS learns a spatio-temporal velocity field that transports context volumes toward a target volume at an arbitrary time, while operating directly in 3D voxel space. Across three public datasets spanning Cine-MRI, perfusion CT, and longitudinal MRI, CRONOS outperforms other baselines, while remaining computationally competitive. We will release code and evaluation protocols to enable reproducible, multi-dataset benchmarking of multi-context, continuous-time forecasting.
Temporal Flow Matching for Learning Spatio-Temporal Trajectories in 4D Longitudinal Medical Imaging
Aug 29, 2025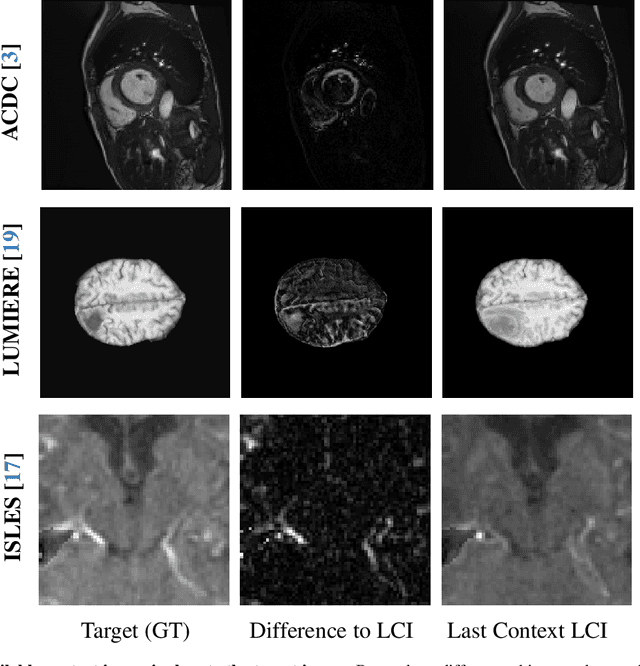

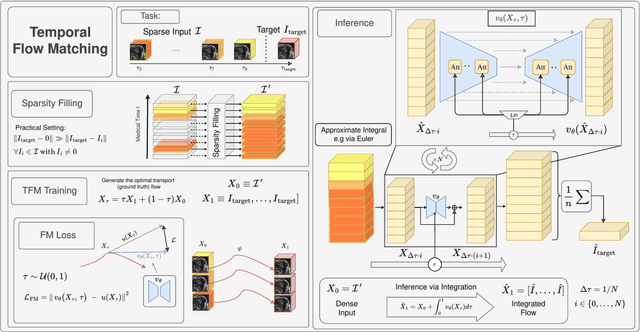
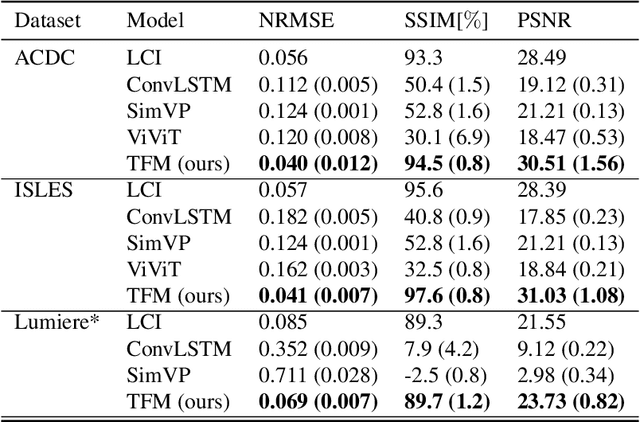
Understanding temporal dynamics in medical imaging is crucial for applications such as disease progression modeling, treatment planning and anatomical development tracking. However, most deep learning methods either consider only single temporal contexts, or focus on tasks like classification or regression, limiting their ability for fine-grained spatial predictions. While some approaches have been explored, they are often limited to single timepoints, specific diseases or have other technical restrictions. To address this fundamental gap, we introduce Temporal Flow Matching (TFM), a unified generative trajectory method that (i) aims to learn the underlying temporal distribution, (ii) by design can fall back to a nearest image predictor, i.e. predicting the last context image (LCI), as a special case, and (iii) supports $3D$ volumes, multiple prior scans, and irregular sampling. Extensive benchmarks on three public longitudinal datasets show that TFM consistently surpasses spatio-temporal methods from natural imaging, establishing a new state-of-the-art and robust baseline for $4D$ medical image prediction.
nnLandmark: A Self-Configuring Method for 3D Medical Landmark Detection
Apr 10, 2025Landmark detection plays a crucial role in medical imaging tasks that rely on precise spatial localization, including specific applications in diagnosis, treatment planning, image registration, and surgical navigation. However, manual annotation is labor-intensive and requires expert knowledge. While deep learning shows promise in automating this task, progress is hindered by limited public datasets, inconsistent benchmarks, and non-standardized baselines, restricting reproducibility, fair comparisons, and model generalizability. This work introduces nnLandmark, a self-configuring deep learning framework for 3D medical landmark detection, adapting nnU-Net to perform heatmap-based regression. By leveraging nnU-Net's automated configuration, nnLandmark eliminates the need for manual parameter tuning, offering out-of-the-box usability. It achieves state-of-the-art accuracy across two public datasets, with a mean radial error (MRE) of 1.5 mm on the Mandibular Molar Landmark (MML) dental CT dataset and 1.2 mm for anatomical fiducials on a brain MRI dataset (AFIDs), where nnLandmark aligns with the inter-rater variability of 1.5 mm. With its strong generalization, reproducibility, and ease of deployment, nnLandmark establishes a reliable baseline for 3D landmark detection, supporting research in anatomical localization and clinical workflows that depend on precise landmark identification. The code will be available soon.
Decoupling Semantic Similarity from Spatial Alignment for Neural Networks
Oct 30, 2024
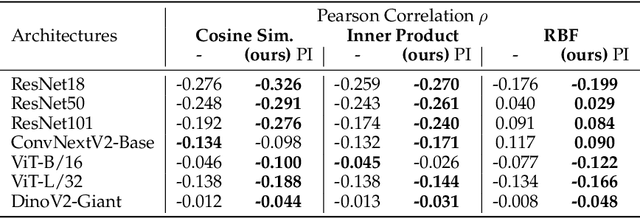
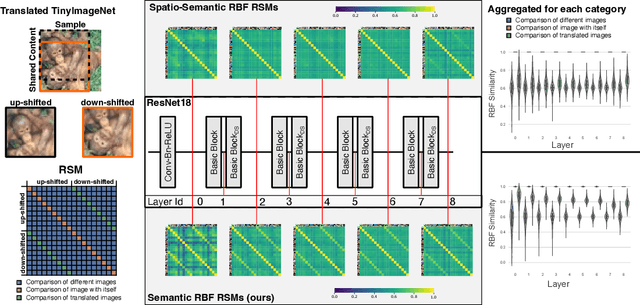

What representation do deep neural networks learn? How similar are images to each other for neural networks? Despite the overwhelming success of deep learning methods key questions about their internal workings still remain largely unanswered, due to their internal high dimensionality and complexity. To address this, one approach is to measure the similarity of activation responses to various inputs. Representational Similarity Matrices (RSMs) distill this similarity into scalar values for each input pair. These matrices encapsulate the entire similarity structure of a system, indicating which input leads to similar responses. While the similarity between images is ambiguous, we argue that the spatial location of semantic objects does neither influence human perception nor deep learning classifiers. Thus this should be reflected in the definition of similarity between image responses for computer vision systems. Revisiting the established similarity calculations for RSMs we expose their sensitivity to spatial alignment. In this paper, we propose to solve this through semantic RSMs, which are invariant to spatial permutation. We measure semantic similarity between input responses by formulating it as a set-matching problem. Further, we quantify the superiority of semantic RSMs over spatio-semantic RSMs through image retrieval and by comparing the similarity between representations to the similarity between predicted class probabilities.
Visual Prompt Engineering for Medical Vision Language Models in Radiology
Aug 28, 2024



Medical image classification in radiology faces significant challenges, particularly in generalizing to unseen pathologies. In contrast, CLIP offers a promising solution by leveraging multimodal learning to improve zero-shot classification performance. However, in the medical domain, lesions can be small and might not be well represented in the embedding space. Therefore, in this paper, we explore the potential of visual prompt engineering to enhance the capabilities of Vision Language Models (VLMs) in radiology. Leveraging BiomedCLIP, trained on extensive biomedical image-text pairs, we investigate the impact of embedding visual markers directly within radiological images to guide the model's attention to critical regions. Our evaluation on the JSRT dataset, focusing on lung nodule malignancy classification, demonstrates that incorporating visual prompts $\unicode{x2013}$ such as arrows, circles, and contours $\unicode{x2013}$ significantly improves classification metrics including AUROC, AUPRC, F1 score, and accuracy. Moreover, the study provides attention maps, showcasing enhanced model interpretability and focus on clinically relevant areas. These findings underscore the efficacy of visual prompt engineering as a straightforward yet powerful approach to advance VLM performance in medical image analysis.
Comparative Benchmarking of Failure Detection Methods in Medical Image Segmentation: Unveiling the Role of Confidence Aggregation
Jun 05, 2024



Semantic segmentation is an essential component of medical image analysis research, with recent deep learning algorithms offering out-of-the-box applicability across diverse datasets. Despite these advancements, segmentation failures remain a significant concern for real-world clinical applications, necessitating reliable detection mechanisms. This paper introduces a comprehensive benchmarking framework aimed at evaluating failure detection methodologies within medical image segmentation. Through our analysis, we identify the strengths and limitations of current failure detection metrics, advocating for the risk-coverage analysis as a holistic evaluation approach. Utilizing a collective dataset comprising five public 3D medical image collections, we assess the efficacy of various failure detection strategies under realistic test-time distribution shifts. Our findings highlight the importance of pixel confidence aggregation and we observe superior performance of the pairwise Dice score (Roy et al., 2019) between ensemble predictions, positioning it as a simple and robust baseline for failure detection in medical image segmentation. To promote ongoing research, we make the benchmarking framework available to the community.
Leveraging Foundation Models for Content-Based Medical Image Retrieval in Radiology
Mar 11, 2024Content-based image retrieval (CBIR) has the potential to significantly improve diagnostic aid and medical research in radiology. Current CBIR systems face limitations due to their specialization to certain pathologies, limiting their utility. In response, we propose using vision foundation models as powerful and versatile off-the-shelf feature extractors for content-based medical image retrieval. By benchmarking these models on a comprehensive dataset of 1.6 million 2D radiological images spanning four modalities and 161 pathologies, we identify weakly-supervised models as superior, achieving a P@1 of up to 0.594. This performance not only competes with a specialized model but does so without the need for fine-tuning. Our analysis further explores the challenges in retrieving pathological versus anatomical structures, indicating that accurate retrieval of pathological features presents greater difficulty. Despite these challenges, our research underscores the vast potential of foundation models for CBIR in radiology, proposing a shift towards versatile, general-purpose medical image retrieval systems that do not require specific tuning.
RecycleNet: Latent Feature Recycling Leads to Iterative Decision Refinement
Sep 14, 2023



Despite the remarkable success of deep learning systems over the last decade, a key difference still remains between neural network and human decision-making: As humans, we cannot only form a decision on the spot, but also ponder, revisiting an initial guess from different angles, distilling relevant information, arriving at a better decision. Here, we propose RecycleNet, a latent feature recycling method, instilling the pondering capability for neural networks to refine initial decisions over a number of recycling steps, where outputs are fed back into earlier network layers in an iterative fashion. This approach makes minimal assumptions about the neural network architecture and thus can be implemented in a wide variety of contexts. Using medical image segmentation as the evaluation environment, we show that latent feature recycling enables the network to iteratively refine initial predictions even beyond the iterations seen during training, converging towards an improved decision. We evaluate this across a variety of segmentation benchmarks and show consistent improvements even compared with top-performing segmentation methods. This allows trading increased computation time for improved performance, which can be beneficial, especially for safety-critical applications.
Exploring new ways: Enforcing representational dissimilarity to learn new features and reduce error consistency
Jul 05, 2023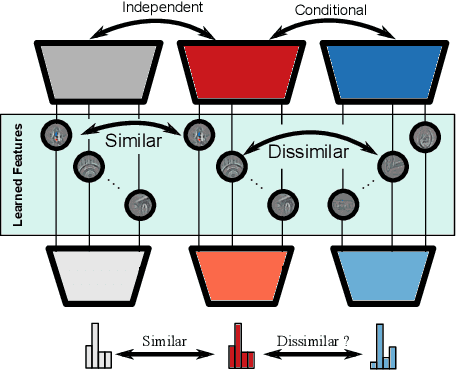
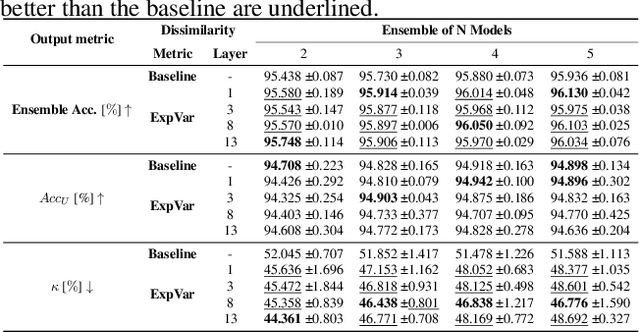

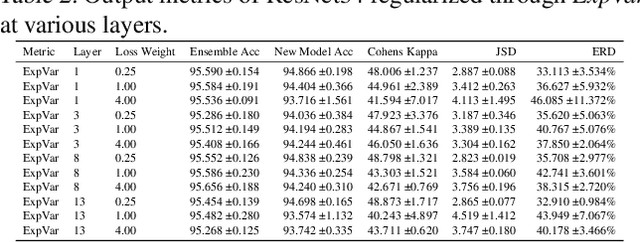
Independently trained machine learning models tend to learn similar features. Given an ensemble of independently trained models, this results in correlated predictions and common failure modes. Previous attempts focusing on decorrelation of output predictions or logits yielded mixed results, particularly due to their reduction in model accuracy caused by conflicting optimization objectives. In this paper, we propose the novel idea of utilizing methods of the representational similarity field to promote dissimilarity during training instead of measuring similarity of trained models. To this end, we promote intermediate representations to be dissimilar at different depths between architectures, with the goal of learning robust ensembles with disjoint failure modes. We show that highly dissimilar intermediate representations result in less correlated output predictions and slightly lower error consistency, resulting in higher ensemble accuracy. With this, we shine first light on the connection between intermediate representations and their impact on the output predictions.
SAM.MD: Zero-shot medical image segmentation capabilities of the Segment Anything Model
Apr 10, 2023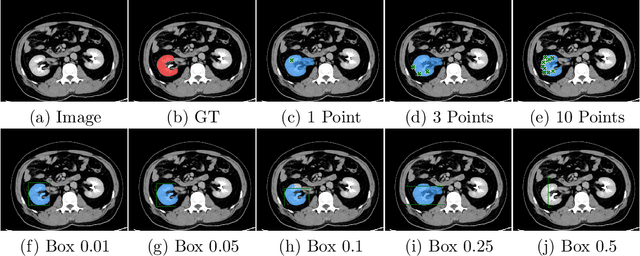
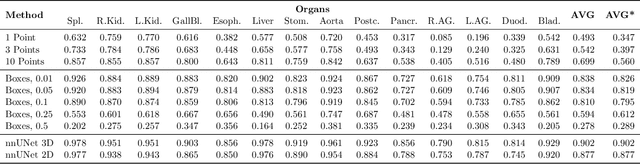
Foundation models have taken over natural language processing and image generation domains due to the flexibility of prompting. With the recent introduction of the Segment Anything Model (SAM), this prompt-driven paradigm has entered image segmentation with a hitherto unexplored abundance of capabilities. The purpose of this paper is to conduct an initial evaluation of the out-of-the-box zero-shot capabilities of SAM for medical image segmentation, by evaluating its performance on an abdominal CT organ segmentation task, via point or bounding box based prompting. We show that SAM generalizes well to CT data, making it a potential catalyst for the advancement of semi-automatic segmentation tools for clinicians. We believe that this foundation model, while not reaching state-of-the-art segmentation performance in our investigations, can serve as a highly potent starting point for further adaptations of such models to the intricacies of the medical domain. Keywords: medical image segmentation, SAM, foundation models, zero-shot learning