 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Scaling Laws for Symbolic Regression
Oct 30, 2025



Symbolic regression (SR) aims to discover the underlying mathematical expressions that explain observed data. This holds promise for both gaining scientific insight and for producing inherently interpretable and generalizable models for tabular data. In this work we focus on the basics of SR. Deep learning-based SR has recently become competitive with genetic programming approaches, but the role of scale has remained largely unexplored. Inspired by scaling laws in language modeling, we present the first systematic investigation of scaling in SR, using a scalable end-to-end transformer pipeline and carefully generated training data. Across five different model sizes and spanning three orders of magnitude in compute, we find that both validation loss and solved rate follow clear power-law trends with compute. We further identify compute-optimal hyperparameter scaling: optimal batch size and learning rate grow with model size, and a token-to-parameter ratio of $\approx$15 is optimal in our regime, with a slight upward trend as compute increases. These results demonstrate that SR performance is largely predictable from compute and offer important insights for training the next generation of SR models.
Learning in Compact Spaces with Approximately Normalized Transformers
May 28, 2025In deep learning, regularization and normalization are common solutions for challenges such as overfitting, numerical instabilities, and the increasing variance in the residual stream. An alternative approach is to force all parameters and representations to lie on a hypersphere. This removes the need for regularization and increases convergence speed, but comes with additional costs. In this work, we propose a more holistic but approximate normalization (anTransformer). Our approach constrains the norm of parameters and normalizes all representations via scalar multiplications motivated by the tight concentration of the norms of high-dimensional random vectors. When applied to GPT training, we observe a 40% faster convergence compared to models with QK normalization, with less than 3% additional runtime. Deriving scaling laws for anGPT, we found our method enables training with larger batch sizes and fewer hyperparameters, while matching the favorable scaling characteristics of classic GPT architectures.
Unlocking State-Tracking in Linear RNNs Through Negative Eigenvalues
Nov 19, 2024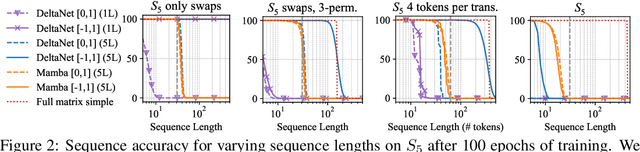
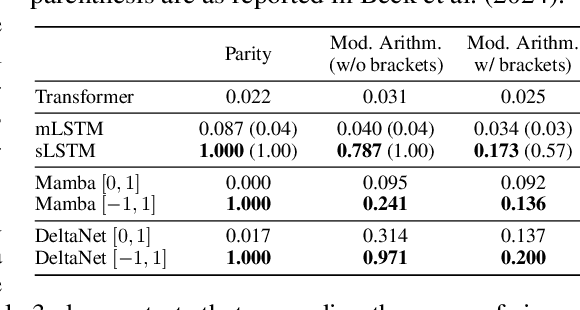
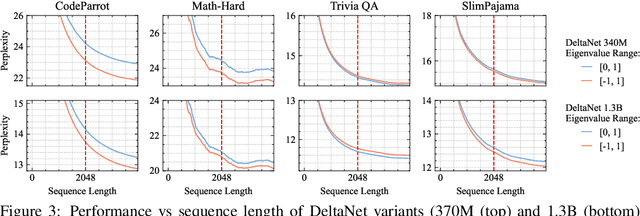
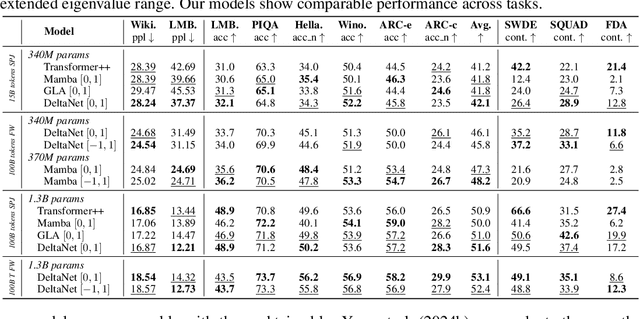
Linear Recurrent Neural Networks (LRNNs) such as Mamba, RWKV, GLA, mLSTM, and DeltaNet have emerged as efficient alternatives to Transformers in large language modeling, offering linear scaling with sequence length and improved training efficiency. However, LRNNs struggle to perform state-tracking which may impair performance in tasks such as code evaluation or tracking a chess game. Even parity, the simplest state-tracking task, which non-linear RNNs like LSTM handle effectively, cannot be solved by current LRNNs. Recently, Sarrof et al. (2024) demonstrated that the failure of LRNNs like Mamba to solve parity stems from restricting the value range of their diagonal state-transition matrices to $[0, 1]$ and that incorporating negative values can resolve this issue. We extend this result to non-diagonal LRNNs, which have recently shown promise in models such as DeltaNet. We prove that finite precision LRNNs with state-transition matrices having only positive eigenvalues cannot solve parity, while complex eigenvalues are needed to count modulo $3$. Notably, we also prove that LRNNs can learn any regular language when their state-transition matrices are products of identity minus vector outer product matrices, each with eigenvalues in the range $[-1, 1]$. Our empirical results confirm that extending the eigenvalue range of models like Mamba and DeltaNet to include negative values not only enables them to solve parity but consistently improves their performance on state-tracking tasks. Furthermore, pre-training LRNNs with an extended eigenvalue range for language modeling achieves comparable performance and stability while showing promise on code and math data. Our work enhances the expressivity of modern LRNNs, broadening their applicability without changing the cost of training or inference.
Transfer Learning for Finetuning Large Language Models
Nov 02, 2024



As the landscape of large language models expands, efficiently finetuning for specific tasks becomes increasingly crucial. At the same time, the landscape of parameter-efficient finetuning methods rapidly expands. Consequently, practitioners face a multitude of complex choices when searching for an optimal finetuning pipeline for large language models. To reduce the complexity for practitioners, we investigate transfer learning for finetuning large language models and aim to transfer knowledge about configurations from related finetuning tasks to a new task. In this work, we transfer learn finetuning by meta-learning performance and cost surrogate models for grey-box meta-optimization from a new meta-dataset. Counter-intuitively, we propose to rely only on transfer learning for new datasets. Thus, we do not use task-specific Bayesian optimization but prioritize knowledge transferred from related tasks over task-specific feedback. We evaluate our method on eight synthetic question-answer datasets and a meta-dataset consisting of 1,800 runs of finetuning Microsoft's Phi-3. Our transfer learning is superior to zero-shot, default finetuning, and meta-optimization baselines. Our results demonstrate the transferability of finetuning to adapt large language models more effectively.
New Horizons in Parameter Regularization: A Constraint Approach
Nov 15, 2023



This work presents constrained parameter regularization (CPR), an alternative to traditional weight decay. Instead of applying a constant penalty uniformly to all parameters, we enforce an upper bound on a statistical measure (e.g., the L$_2$-norm) of individual parameter groups. This reformulates learning as a constrained optimization problem. To solve this, we utilize an adaptation of the augmented Lagrangian method. Our approach allows for varying regularization strengths across different parameter groups, removing the need for explicit penalty coefficients in the regularization terms. CPR only requires two hyperparameters and introduces no measurable runtime overhead. We offer empirical evidence of CPR's effectiveness through experiments in the "grokking" phenomenon, image classification, and language modeling. Our findings show that CPR can counteract the effects of grokking, and it consistently matches or surpasses the performance of traditional weight decay.
RecycleNet: Latent Feature Recycling Leads to Iterative Decision Refinement
Sep 14, 2023



Despite the remarkable success of deep learning systems over the last decade, a key difference still remains between neural network and human decision-making: As humans, we cannot only form a decision on the spot, but also ponder, revisiting an initial guess from different angles, distilling relevant information, arriving at a better decision. Here, we propose RecycleNet, a latent feature recycling method, instilling the pondering capability for neural networks to refine initial decisions over a number of recycling steps, where outputs are fed back into earlier network layers in an iterative fashion. This approach makes minimal assumptions about the neural network architecture and thus can be implemented in a wide variety of contexts. Using medical image segmentation as the evaluation environment, we show that latent feature recycling enables the network to iteratively refine initial predictions even beyond the iterations seen during training, converging towards an improved decision. We evaluate this across a variety of segmentation benchmarks and show consistent improvements even compared with top-performing segmentation methods. This allows trading increased computation time for improved performance, which can be beneficial, especially for safety-critical applications.
Towards Automated Design of Riboswitches
Jul 17, 2023



Experimental screening and selection pipelines for the discovery of novel riboswitches are expensive, time-consuming, and inefficient. Using computational methods to reduce the number of candidates for the screen could drastically decrease these costs. However, existing computational approaches do not fully satisfy all requirements for the design of such initial screening libraries. In this work, we present a new method, libLEARNA, capable of providing RNA focus libraries of diverse variable-length qualified candidates. Our novel structure-based design approach considers global properties as well as desired sequence and structure features. We demonstrate the benefits of our method by designing theophylline riboswitch libraries, following a previously published protocol, and yielding 30% more unique high-quality candidates.
Scalable Deep Learning for RNA Secondary Structure Prediction
Jul 14, 2023



The field of RNA secondary structure prediction has made significant progress with the adoption of deep learning techniques. In this work, we present the RNAformer, a lean deep learning model using axial attention and recycling in the latent space. We gain performance improvements by designing the architecture for modeling the adjacency matrix directly in the latent space and by scaling the size of the model. Our approach achieves state-of-the-art performance on the popular TS0 benchmark dataset and even outperforms methods that use external information. Further, we show experimentally that the RNAformer can learn a biophysical model of the RNA folding process.
Probabilistic Transformer: Modelling Ambiguities and Distributions for RNA Folding and Molecule Design
May 27, 2022
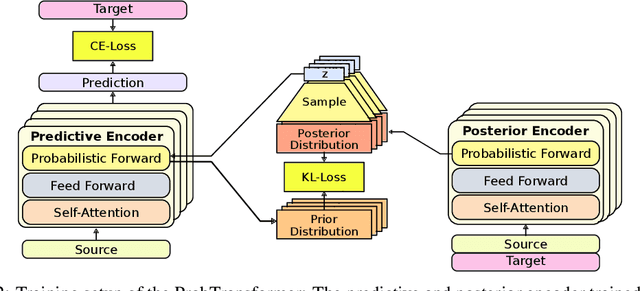
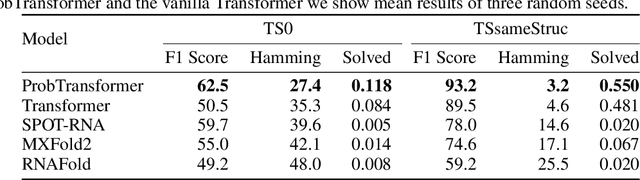
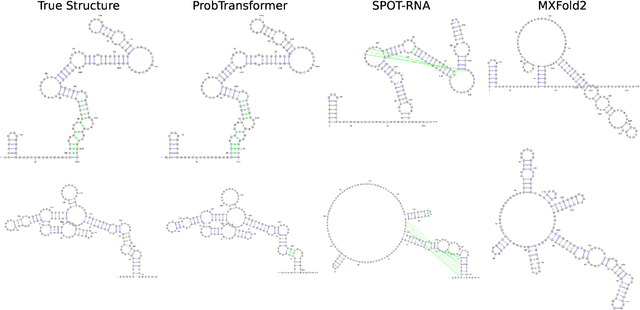
Our world is ambiguous and this is reflected in the data we use to train our algorithms. This is especially true when we try to model natural processes where collected data is affected by noisy measurements and differences in measurement techniques. Sometimes, the process itself can be ambiguous, such as in the case of RNA folding, where a single nucleotide sequence can fold into multiple structures. This ambiguity suggests that a predictive model should have similar probabilistic characteristics to match the data it models. Therefore, we propose a hierarchical latent distribution to enhance one of the most successful deep learning models, the Transformer, to accommodate ambiguities and data distributions. We show the benefits of our approach on a synthetic task, with state-of-the-art results in RNA folding, and demonstrate its generative capabilities on property-based molecule design, outperforming existing work.
Hyperparameter Transfer Across Developer Adjustments
Oct 25, 2020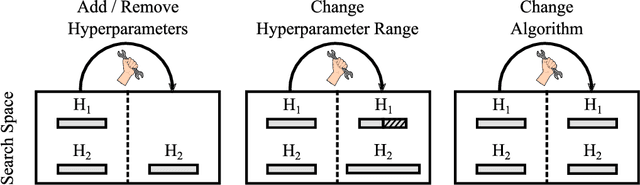

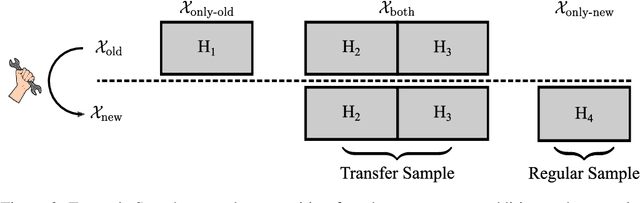
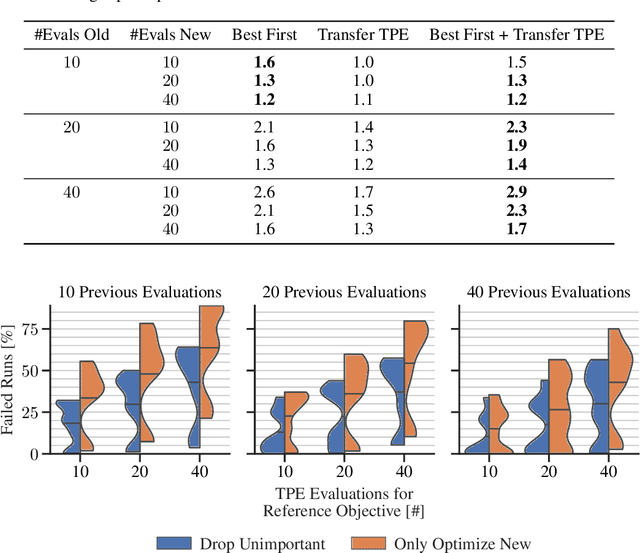
After developer adjustments to a machine learning (ML) algorithm, how can the results of an old hyperparameter optimization (HPO) automatically be used to speedup a new HPO? This question poses a challenging problem, as developer adjustments can change which hyperparameter settings perform well, or even the hyperparameter search space itself. While many approaches exist that leverage knowledge obtained on previous tasks, so far, knowledge from previous development steps remains entirely untapped. In this work, we remedy this situation and propose a new research framework: hyperparameter transfer across adjustments (HT-AA). To lay a solid foundation for this research framework, we provide four simple HT-AA baseline algorithms and eight benchmarks changing various aspects of ML algorithms, their hyperparameter search spaces, and the neural architectures used. The best baseline, on average and depending on the budgets for the old and new HPO, reaches a given performance 1.2--2.6x faster than a prominent HPO algorithm without transfer. As HPO is a crucial step in ML development but requires extensive computational resources, this speedup would lead to faster development cycles, lower costs, and reduced environmental impacts. To make these benefits available to ML developers off-the-shelf and to facilitate future research on HT-AA, we provide python packages for our baselines and benchmarks.