 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurvPFN: Towards Foundation Models for Survival Predictions
Jun 03, 2026Tabular foundation models (TFMs) have made rapid progress in standard classification and regression, but time-to-event survival prediction tasks have remained largely untouched. Unlike in standard regression tasks, survival prediction models must account for censored data. Standard TFMs cannot handle natively censored data, leading to biased and inaccurate predictions, making them unsuitable for real-world applications. To overcome this fundamental limitation, we propose \texttt{SurvPFN}, a prior-data fitted network (PFN), for survival prediction tasks. We pretrain \texttt{SurvPFN} on millions of synthetic survival prediction tasks to learn survival via distributional regression that accounts for censored data. \texttt{SurvPFN} works by (1) generating data with Weibull event times and a non-informative censoring mechanism; (2) integrating a censored event indicator; and (3) minimizing a censored negative log-likelihood. On SurvSet, a collection of real-world survival tasks, \texttt{SurvPFN} is highly competitive with classical and deep survival baselines without per-dataset fitting, a survival-specific architecture, or feature engineering. We show that survival can be treated as a continuous-time distributional regression problem with censored loss, unlocking the power of PFNs for time-to-event predictions.
Towards Pretraining Text Encoders for TabPFN
Jun 03, 2026Tabular foundation models, such as TabPFN, achieve strong performance on tabular datasets with numerical and categorical data, but do not natively handle high-cardinality text features. Standard pipelines, therefore, embed text with a language model and compress the resulting vectors with PCA into a small number of scalar features before inputting them into TabPFN. This creates an information bottleneck: most embedding dimensions are discarded, and the compressed representation must then be expanded again by TabPFN's feature encoder. End-to-end alternatives can avoid PCA, but they require large amounts of pretraining data containing text cells and usually perform subpar compared to tabular foundation models that were pretrained on large amounts of synthetic data. Inspired by modality-alignment approaches like LLaVA (vision-to-LLM token projection) and TableGPT-style systems (table-to-LLM token projection), we introduce the TabPFN Text Adapter (text-to-TFM token projection). We freeze both the sentence encoder and TabPFN, and train only a lightweight adapter that maps text embeddings into a short sequence of tokens in TabPFN's embedding space. This design removes the PCA bottleneck, preserves TabPFN's numerical strengths, and is more efficient to train than end-to-end text-tabular pipelines.
TabPFN-3: Technical Report
May 13, 2026Tabular data underpins most high-value prediction problems in science and industry, and TabPFN has driven the foundation model revolution for this modality. Designed with feedback from our users, TabPFN-3 builds on this foundation to scale state-of-the-art performance to datasets with 1M training rows and substantially reduce training and inference time. Pretrained exclusively on synthetic data from our prior, TabPFN-3 dramatically pushes the frontier of tabular prediction and brings substantial gains on time series, relational, and tabular-text data. On the standard tabular benchmark TabArena, a forward pass of TabPFN-3 outperforms all other models, including tuned and ensembled baselines, by a significant margin, and pareto-dominates the speed/performance frontier. On more diverse datasets, TabPFN-3 ranks first on datasets with many classes, and beats 8-hour-tuned gradient-boosted-tree baselines on datasets up to 1M training rows and 200 features. TabPFN-3 introduces test-time compute scaling to tabular foundation models. Our API offering TabPFN-3-Plus (Thinking) exploits this to beat all non-TabPFN models by over 200 Elo on TabArena, rising to 420 Elo on the largest data subset, and outperforms AutoGluon 1.5 extreme while being 10x faster, without using LLMs, real data, internet search or any other model besides TabPFN. TabPFN-3 extends the capabilities of our models, enabling SOTA prediction on relational data (new SOTA foundation model on RelBenchV1) and tabular-text data (SOTA on TabSTAR via TabPFN-3-Plus); and improves existing integrations: a specialized checkpoint, TabPFN-TS-3, ranks 2nd on the time-series benchmark fev-bench, and SHAP-value computation is up to 120x faster. TabPFN-3 achieves this performance while being up to 20x faster than TabPFN-2.5. In addition, a reduced KV cache and row-chunking scale to 1M rows on one H100 with fast inference speed.
STRABLE: Benchmarking Tabular Machine Learning with Strings
May 12, 2026Benchmarking tabular learning has revealed the benefit of dedicated architectures, pushing the state of the art. But real-world tables often contain string entries, beyond numbers, and these settings have been understudied due to a lack of a solid benchmarking suite. They lead to new research questions: Are dedicated learners needed, with end-to-end modeling of strings and numbers? Or does it suffice to encode strings as numbers, as with a categorical encoding? And if so, do the resulting tables resemble numerical tabular data, calling for the same learners? To enable these studies, we contribute STRABLE, a benchmarking corpus of 108 tables, all real-world learning problems with strings and numbers across diverse application fields. We run the first large-scale empirical study of tabular learning with strings, evaluating 445 pipelines. These pipelines span end-to-end architectures and modular pipelines, where strings are first encoded, then post-processed, and finally passed to a tabular learner. We find that, because most tables in the wild are categorical-dominant, advanced tabular learners paired with simple string embeddings achieve good predictions at low computational cost. On free-text-dominant tables, large LLM encoders become competitive. Their performance also appears sensitive to post-processing, with differences across LLM families. Finally, we show that STRABLE is a good set of tables to study "string tabular" learning as it leads to generalizable pipeline rankings that are close to the oracle rankings. We thus establish STRABLE as a foundation for research on tabular learning with strings, an important yet understudied area.
MulTaBench: Benchmarking Multimodal Tabular Learning with Text and Image
May 11, 2026Tabular Foundation Models have recently established the state of the art in supervised tabular learning, by leveraging pretraining to learn generalizable representations of numerical and categorical structured data. However, they lack native support for unstructured modalities such as text and image, and rely on frozen, pretrained embeddings to process them. On established Multimodal Tabular Learning benchmarks, we show that tuning the embeddings to the task improves performance. Existing benchmarks, however, often focus on the mere co-occurrence of modalities; this leads to high variance across datasets and masks the benefits of task-specific tuning. To address this gap, we introduce MulTaBench, a benchmark of 40 datasets, split equally between image-tabular and text-tabular tasks. We focus on predictive tasks where the modalities provide complementary predictive signal, and where generic embeddings lose critical information, necessitating Target-Aware Representations that are aligned with the task. Our experimental results demonstrate that the gains from target-aware representation tuning generalize across both text and image modalities, several tabular learners, encoder scales, and embedding dimensions. MulTaBench constitutes the largest image-tabular benchmarking effort to date, spanning high-impact domains such as healthcare and e-commerce. It is designed to enable the research of novel architectures which incorporate joint modeling and target-aware representations, paving the way for the development of novel Multimodal Tabular Foundation Models.
HAPEns: Hardware-Aware Post-Hoc Ensembling for Tabular Data
Mar 11, 2026Ensembling is commonly used in machine learning on tabular data to boost predictive performance and robustness, but larger ensembles often lead to increased hardware demand. We introduce HAPEns, a post-hoc ensembling method that explicitly balances accuracy against hardware efficiency. Inspired by multi-objective and quality diversity optimization, HAPEns constructs a diverse set of ensembles along the Pareto front of predictive performance and resource usage. Existing hardware-aware post-hoc ensembling baselines are not available, highlighting the novelty of our approach. Experiments on 83 tabular classification datasets show that HAPEns significantly outperforms baselines, finding superior trade-offs for ensemble performance and deployment cost. Ablation studies also reveal that memory usage is a particularly effective objective metric. Further, we show that even a greedy ensembling algorithm can be significantly improved in this task with a static multi-objective weighting scheme.
Causal Data Augmentation for Robust Fine-Tuning of Tabular Foundation Models
Jan 07, 2026Fine-tuning tabular foundation models (TFMs) under data scarcity is challenging, as early stopping on even scarcer validation data often fails to capture true generalization performance. We propose CausalMixFT, a method that enhances fine-tuning robustness and downstream performance by generating structurally consistent synthetic samples using Structural Causal Models (SCMs) fitted on the target dataset. This approach augments limited real data with causally informed synthetic examples, preserving feature dependencies while expanding training diversity. Evaluated across 33 classification datasets from TabArena and over 2300 fine-tuning runs, our CausalMixFT method consistently improves median normalized ROC-AUC from 0.10 (standard fine-tuning) to 0.12, outperforming purely statistical generators such as CTGAN (-0.01), TabEBM (-0.04), and TableAugment (-0.09). Moreover, it narrows the median validation-test performance correlation gap from 0.67 to 0.30, enabling more reliable validation-based early stopping, a key step toward improving fine-tuning stability under data scarcity. These results demonstrate that incorporating causal structure into data augmentation provides an effective and principled route to fine-tuning tabular foundation models in low-data regimes.
TabPFN-2.5: Advancing the State of the Art in Tabular Foundation Models
Nov 11, 2025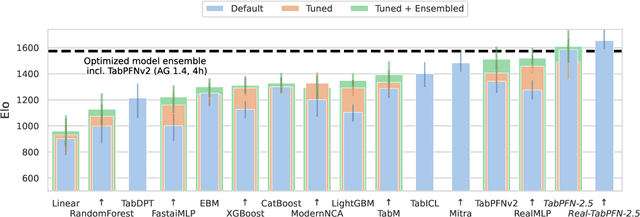
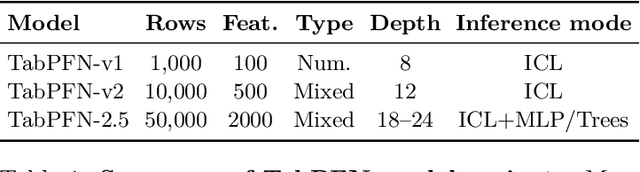
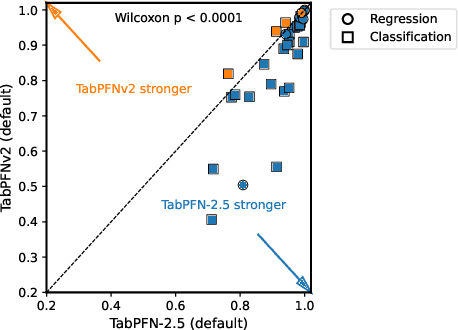
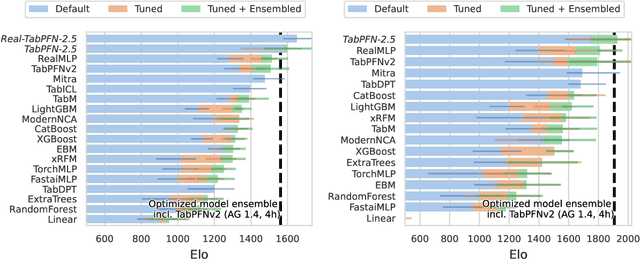
The first tabular foundation model, TabPFN, and its successor TabPFNv2 have impacted tabular AI substantially, with dozens of methods building on it and hundreds of applications across different use cases. This report introduces TabPFN-2.5, the next generation of our tabular foundation model, built for datasets with up to 50,000 data points and 2,000 features, a 20x increase in data cells compared to TabPFNv2. TabPFN-2.5 is now the leading method for the industry standard benchmark TabArena (which contains datasets with up to 100,000 training data points), substantially outperforming tuned tree-based models and matching the accuracy of AutoGluon 1.4, a complex four-hour tuned ensemble that even includes the previous TabPFNv2. Remarkably, default TabPFN-2.5 has a 100% win rate against default XGBoost on small to medium-sized classification datasets (<=10,000 data points, 500 features) and a 87% win rate on larger datasets up to 100K samples and 2K features (85% for regression). For production use cases, we introduce a new distillation engine that converts TabPFN-2.5 into a compact MLP or tree ensemble, preserving most of its accuracy while delivering orders-of-magnitude lower latency and plug-and-play deployment. This new release will immediately strengthen the performance of the many applications and methods already built on the TabPFN ecosystem.
Does TabPFN Understand Causal Structures?
Nov 10, 2025Causal discovery is fundamental for multiple scientific domains, yet extracting causal information from real world data remains a significant challenge. Given the recent success on real data, we investigate whether TabPFN, a transformer-based tabular foundation model pre-trained on synthetic datasets generated from structural causal models, encodes causal information in its internal representations. We develop an adapter framework using a learnable decoder and causal tokens that extract causal signals from TabPFN's frozen embeddings and decode them into adjacency matrices for causal discovery. Our evaluations demonstrate that TabPFN's embeddings contain causal information, outperforming several traditional causal discovery algorithms, with such causal information being concentrated in mid-range layers. These findings establish a new direction for interpretable and adaptable foundation models and demonstrate the potential for leveraging pre-trained tabular models for causal discovery.
nanoTabPFN: A Lightweight and Educational Reimplementation of TabPFN
Nov 05, 2025Tabular foundation models such as TabPFN have revolutionized predictive machine learning for tabular data. At the same time, the driving factors of this revolution are hard to understand. Existing open-source tabular foundation models are implemented in complicated pipelines boasting over 10,000 lines of code, lack architecture documentation or code quality. In short, the implementations are hard to understand, not beginner-friendly, and complicated to adapt for new experiments. We introduce nanoTabPFN, a simplified and lightweight implementation of the TabPFN v2 architecture and a corresponding training loop that uses pre-generated training data. nanoTabPFN makes tabular foundation models more accessible to students and researchers alike. For example, restricted to a small data setting it achieves a performance comparable to traditional machine learning baselines within one minute of pre-training on a single GPU (160,000x faster than TabPFN v2 pretraining). This eliminated requirement of large computational resources makes pre-training tabular foundation models accessible for educational purposes. Our code is available at https://github.com/automl/nanoTabPFN.