 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHardware Aware Ensemble Selection for Balancing Predictive Accuracy and Cost
Aug 05, 2024
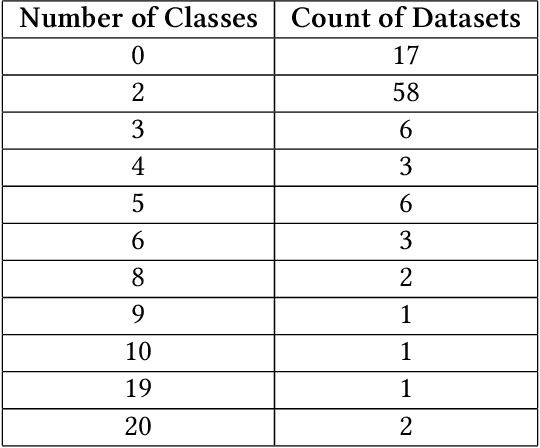


Automated Machine Learning (AutoML) significantly simplifies the deployment of machine learning models by automating tasks from data preprocessing to model selection to ensembling. AutoML systems for tabular data often employ post hoc ensembling, where multiple models are combined to improve predictive accuracy. This typically results in longer inference times, a major limitation in practical deployments. Addressing this, we introduce a hardware-aware ensemble selection approach that integrates inference time into post hoc ensembling. By leveraging an existing framework for ensemble selection with quality diversity optimization, our method evaluates ensemble candidates for their predictive accuracy and hardware efficiency. This dual focus allows for a balanced consideration of accuracy and operational efficiency. Thus, our approach enables practitioners to choose from a Pareto front of accurate and efficient ensembles. Our evaluation using 83 classification datasets shows that our approach sustains competitive accuracy and can significantly improve ensembles' operational efficiency. The results of this study provide a foundation for extending these principles to additional hardware constraints, setting the stage for the development of more resource-efficient AutoML systems.
Out-of-distribution Detection and Generation using Soft Brownian Offset Sampling and Autoencoders
May 04, 2021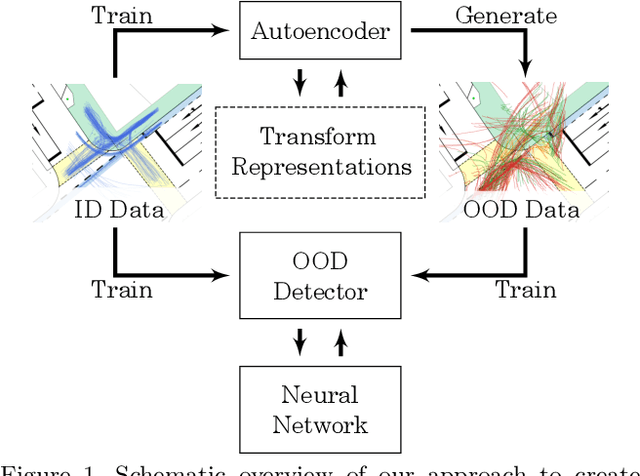
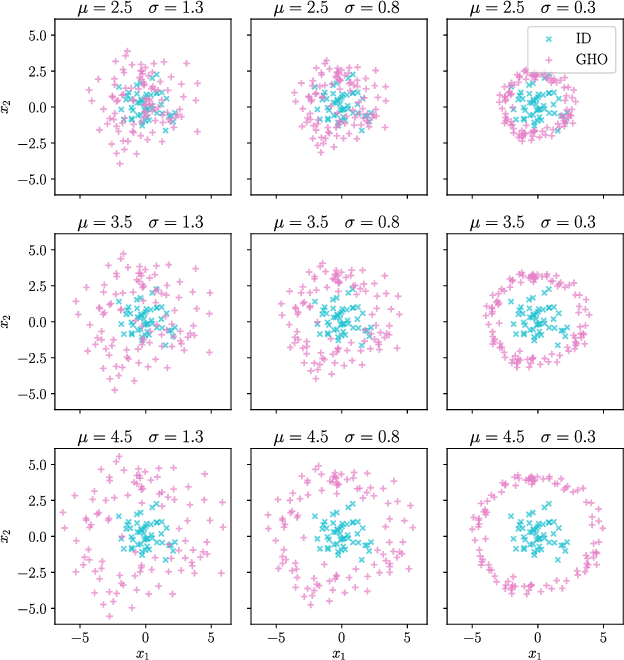
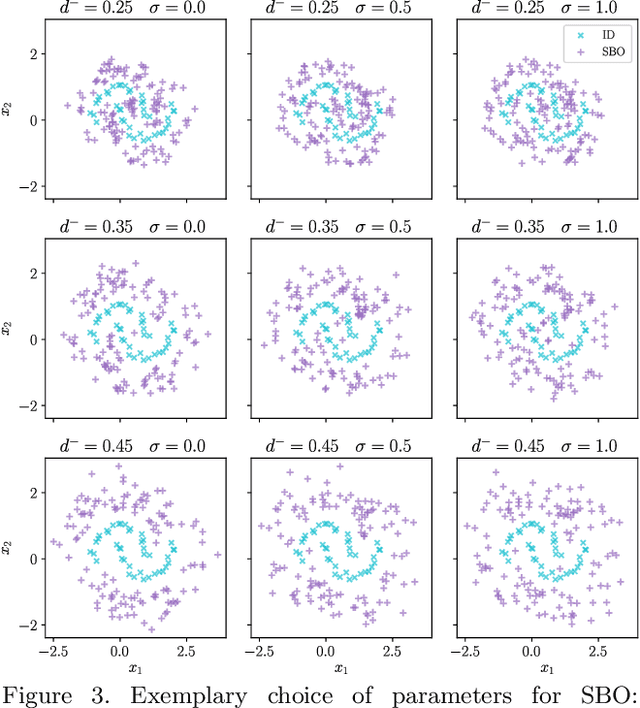
Deep neural networks often suffer from overconfidence which can be partly remedied by improved out-of-distribution detection. For this purpose, we propose a novel approach that allows for the generation of out-of-distribution datasets based on a given in-distribution dataset. This new dataset can then be used to improve out-of-distribution detection for the given dataset and machine learning task at hand. The samples in this dataset are with respect to the feature space close to the in-distribution dataset and therefore realistic and plausible. Hence, this dataset can also be used to safeguard neural networks, i.e., to validate the generalization performance. Our approach first generates suitable representations of an in-distribution dataset using an autoencoder and then transforms them using our novel proposed Soft Brownian Offset method. After transformation, the decoder part of the autoencoder allows for the generation of these implicit out-of-distribution samples. This newly generated dataset then allows for mixing with other datasets and thus improved training of an out-of-distribution classifier, increasing its performance. Experimentally, we show that our approach is promising for time series using synthetic data. Using our new method, we also show in a quantitative case study that we can improve the out-of-distribution detection for the MNIST dataset. Finally, we provide another case study on the synthetic generation of out-of-distribution trajectories, which can be used to validate trajectory prediction algorithms for automated driving.