 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALINC: Active Learning for Inductive Node Classification via Graph Sampling
Jun 03, 2026Active learning (AL) for node classification typically focuses on selecting the most informative nodes for annotation within one or a few large graphs (e.g., in social network analysis). However, in other domains, such as molecular chemistry or electronic design automation, datasets consist of thousands of independent graphs. In many of these inductive settings, annotating an individual node requires a full-graph analysis, which effectively yields the remaining node labels on-the-fly. Therefore, these scenarios require AL strategies that select entire graphs instead of single nodes, a problem which has not been tackled in the literature so far. Thus, we introduce ALINC, an AL framework for inductive node classification via graph sampling. It bridges the existing methodological gap by elevating node-level utility measures to graph-level selection criteria through various aggregation mechanisms. In an extensive benchmark including ten strategies, three aggregation methods, and four datasets, we identify CoreSet, TypiClust, and BADGE as the top-performing graph sampling strategies. Our detailed analysis further reveals that the choice of the aggregation method is pivotal, as it substantially affects model performance and annotation costs. Finally, we demonstrate the effectiveness of ALINC in two use case studies: site-of-metabolism prediction in molecules and design automation of printed circuit board schematics.
BoSS: A Best-of-Strategies Selector as an Oracle for Deep Active Learning
Mar 13, 2026Active learning (AL) aims to reduce annotation costs while maximizing model performance by iteratively selecting valuable instances. While foundation models have made it easier to identify these instances, existing selection strategies still lack robustness across different models, annotation budgets, and datasets. To highlight the potential weaknesses of existing AL strategies and provide a reference point for research, we explore oracle strategies, i.e., strategies that approximate the optimal selection by accessing ground-truth information unavailable in practical AL scenarios. Current oracle strategies, however, fail to scale effectively to large datasets and complex deep neural networks. To tackle these limitations, we introduce the Best-of-Strategy Selector (BoSS), a scalable oracle strategy designed for large-scale AL scenarios. BoSS constructs a set of candidate batches through an ensemble of selection strategies and then selects the batch yielding the highest performance gain. As an ensemble of selection strategies, BoSS can be easily extended with new state-of-the-art strategies as they emerge, ensuring it remains a reliable oracle strategy in the future. Our evaluation demonstrates that i) BoSS outperforms existing oracle strategies, ii) state-of-the-art AL strategies still fall noticeably short of oracle performance, especially in large-scale datasets with many classes, and iii) one possible solution to counteract the inconsistent performance of AL strategies might be to employ an ensemble-based approach for the selection.
crowd-hpo: Realistic Hyperparameter Optimization and Benchmarking for Learning from Crowds with Noisy Labels
Apr 12, 2025Crowdworking is a cost-efficient solution to acquire class labels. Since these labels are subject to noise, various approaches to learning from crowds have been proposed. Typically, these approaches are evaluated with default hyperparameters, resulting in suboptimal performance, or with hyperparameters tuned using a validation set with ground truth class labels, representing an often unrealistic scenario. Moreover, both experimental setups can produce different rankings of approaches, complicating comparisons between studies. Therefore, we introduce crowd-hpo as a realistic benchmark and experimentation protocol including hyperparameter optimization under noisy crowd-labeled data. At its core, crowd-hpo investigates model selection criteria to identify well-performing hyperparameter configurations only with access to noisy crowd-labeled validation data. Extensive experimental evaluations with neural networks show that these criteria are effective for optimizing hyperparameters in learning from crowds approaches. Accordingly, incorporating such criteria into experimentation protocols is essential for enabling more realistic and fair benchmarking.
dopanim: A Dataset of Doppelganger Animals with Noisy Annotations from Multiple Humans
Jul 30, 2024Human annotators typically provide annotated data for training machine learning models, such as neural networks. Yet, human annotations are subject to noise, impairing generalization performances. Methodological research on approaches counteracting noisy annotations requires corresponding datasets for a meaningful empirical evaluation. Consequently, we introduce a novel benchmark dataset, dopanim, consisting of about 15,750 animal images of 15 classes with ground truth labels. For approximately 10,500 of these images, 20 humans provided over 52,000 annotations with an accuracy of circa 67%. Its key attributes include (1) the challenging task of classifying doppelganger animals, (2) human-estimated likelihoods as annotations, and (3) annotator metadata. We benchmark well-known multi-annotator learning approaches using seven variants of this dataset and outline further evaluation use cases such as learning beyond hard class labels and active learning. Our dataset and a comprehensive codebase are publicly available to emulate the data collection process and to reproduce all empirical results.
Towards Deep Active Learning in Avian Bioacoustics
Jun 26, 2024

Passive acoustic monitoring (PAM) in avian bioacoustics enables cost-effective and extensive data collection with minimal disruption to natural habitats. Despite advancements in computational avian bioacoustics, deep learning models continue to encounter challenges in adapting to diverse environments in practical PAM scenarios. This is primarily due to the scarcity of annotations, which requires labor-intensive efforts from human experts. Active learning (AL) reduces annotation cost and speed ups adaption to diverse scenarios by querying the most informative instances for labeling. This paper outlines a deep AL approach, introduces key challenges, and conducts a small-scale pilot study.
Annot-Mix: Learning with Noisy Class Labels from Multiple Annotators via a Mixup Extension
May 06, 2024Training with noisy class labels impairs neural networks' generalization performance. In this context, mixup is a popular regularization technique to improve training robustness by making memorizing false class labels more difficult. However, mixup neglects that, typically, multiple annotators, e.g., crowdworkers, provide class labels. Therefore, we propose an extension of mixup, which handles multiple class labels per instance while considering which class label originates from which annotator. Integrated into our multi-annotator classification framework annot-mix, it performs superiorly to eight state-of-the-art approaches on eleven datasets with noisy class labels provided either by human or simulated annotators. Our code is publicly available through our repository at https://github.com/ies-research/annot-mix.
Fast Fishing: Approximating BAIT for Efficient and Scalable Deep Active Image Classification
Apr 13, 2024



Deep active learning (AL) seeks to minimize the annotation costs for training deep neural networks. BAIT, a recently proposed AL strategy based on the Fisher Information, has demonstrated impressive performance across various datasets. However, BAIT's high computational and memory requirements hinder its applicability on large-scale classification tasks, resulting in current research neglecting BAIT in their evaluation. This paper introduces two methods to enhance BAIT's computational efficiency and scalability. Notably, we significantly reduce its time complexity by approximating the Fisher Information. In particular, we adapt the original formulation by i) taking the expectation over the most probable classes, and ii) constructing a binary classification task, leading to an alternative likelihood for gradient computations. Consequently, this allows the efficient use of BAIT on large-scale datasets, including ImageNet. Our unified and comprehensive evaluation across a variety of datasets demonstrates that our approximations achieve strong performance with considerably reduced time complexity. Furthermore, we provide an extensive open-source toolbox that implements recent state-of-the-art AL strategies, available at https://github.com/dhuseljic/dal-toolbox.
Active Label Refinement for Semantic Segmentation of Satellite Images
Sep 12, 2023
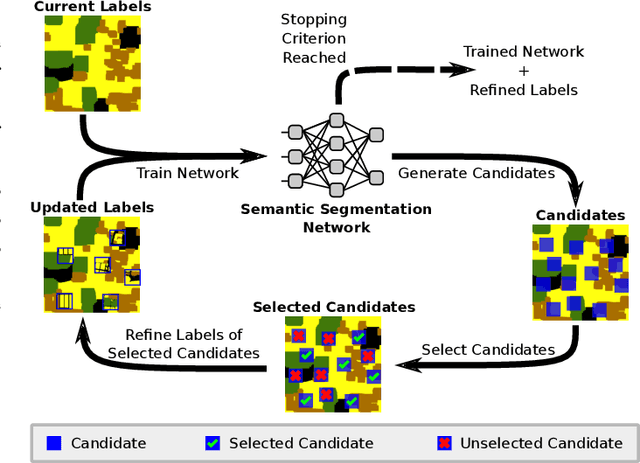
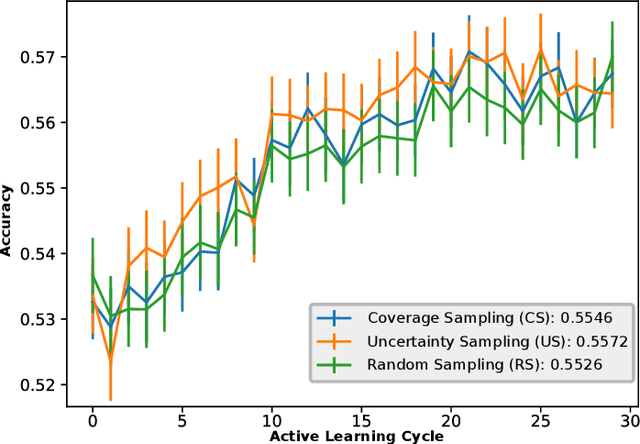
Remote sensing through semantic segmentation of satellite images contributes to the understanding and utilisation of the earth's surface. For this purpose, semantic segmentation networks are typically trained on large sets of labelled satellite images. However, obtaining expert labels for these images is costly. Therefore, we propose to rely on a low-cost approach, e.g. crowdsourcing or pretrained networks, to label the images in the first step. Since these initial labels are partially erroneous, we use active learning strategies to cost-efficiently refine the labels in the second step. We evaluate the active learning strategies using satellite images of Bengaluru in India, labelled with land cover and land use labels. Our experimental results suggest that an active label refinement to improve the semantic segmentation network's performance is beneficial.
ActiveGLAE: A Benchmark for Deep Active Learning with Transformers
Jun 16, 2023Deep active learning (DAL) seeks to reduce annotation costs by enabling the model to actively query instance annotations from which it expects to learn the most. Despite extensive research, there is currently no standardized evaluation protocol for transformer-based language models in the field of DAL. Diverse experimental settings lead to difficulties in comparing research and deriving recommendations for practitioners. To tackle this challenge, we propose the ActiveGLAE benchmark, a comprehensive collection of data sets and evaluation guidelines for assessing DAL. Our benchmark aims to facilitate and streamline the evaluation process of novel DAL strategies. Additionally, we provide an extensive overview of current practice in DAL with transformer-based language models. We identify three key challenges - data set selection, model training, and DAL settings - that pose difficulties in comparing query strategies. We establish baseline results through an extensive set of experiments as a reference point for evaluating future work. Based on our findings, we provide guidelines for researchers and practitioners.
Multi-annotator Deep Learning: A Probabilistic Framework for Classification
Apr 05, 2023



Solving complex classification tasks using deep neural networks typically requires large amounts of annotated data. However, corresponding class labels are noisy when provided by error-prone annotators, e.g., crowd workers. Training standard deep neural networks leads to subpar performances in such multi-annotator supervised learning settings. We address this issue by presenting a probabilistic training framework named multi-annotator deep learning (MaDL). A ground truth and an annotator performance model are jointly trained in an end-to-end learning approach. The ground truth model learns to predict instances' true class labels, while the annotator performance model infers probabilistic estimates of annotators' performances. A modular network architecture enables us to make varying assumptions regarding annotators' performances, e.g., an optional class or instance dependency. Further, we learn annotator embeddings to estimate annotators' densities within a latent space as proxies of their potentially correlated annotations. Together with a weighted loss function, we improve the learning from correlated annotation patterns. In a comprehensive evaluation, we examine three research questions about multi-annotator supervised learning. Our findings indicate MaDL's state-of-the-art performance and robustness against many correlated, spamming annotators.