 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-to-Image Bird Species Retrieval without Audio-Image Pairs via Text Distillation
Jan 31, 2026Audio-to-image retrieval offers an interpretable alternative to audio-only classification for bioacoustic species recognition, but learning aligned audio-image representations is challenging due to the scarcity of paired audio-image data. We propose a simple and data-efficient approach that enables audio-to-image retrieval without any audio-image supervision. Our proposed method uses text as a semantic intermediary: we distill the text embedding space of a pretrained image-text model (BioCLIP-2), which encodes rich visual and taxonomic structure, into a pretrained audio-text model (BioLingual) by fine-tuning its audio encoder with a contrastive objective. This distillation transfers visually grounded semantics into the audio representation, inducing emergent alignment between audio and image embeddings without using images during training. We evaluate the resulting model on multiple bioacoustic benchmarks. The distilled audio encoder preserves audio discriminative power while substantially improving audio-text alignment on focal recordings and soundscape datasets. Most importantly, on the SSW60 benchmark, the proposed approach achieves strong audio-to-image retrieval performance exceeding baselines based on zero-shot model combinations or learned mappings between text embeddings, despite not training on paired audio-image data. These results demonstrate that indirect semantic transfer through text is sufficient to induce meaningful audio-image alignment, providing a practical solution for visually grounded species recognition in data-scarce bioacoustic settings.
Data-Efficient Self-Supervised Algorithms for Fine-Grained Birdsong Analysis
Nov 15, 2025Many bioacoustics, neuroscience, and linguistics research utilize birdsongs as proxy models to acquire knowledge in diverse areas. Developing models generally requires precisely annotated data at the level of syllables. Hence, automated and data-efficient methods that reduce annotation costs are in demand. This work presents a lightweight, yet performant neural network architecture for birdsong annotation called Residual-MLP-RNN. Then, it presents a robust three-stage training pipeline for developing reliable deep birdsong syllable detectors with minimal expert labor. The first stage is self-supervised learning from unlabeled data. Two of the most successful pretraining paradigms are explored, namely, masked prediction and online clustering. The second stage is supervised training with effective data augmentations to create a robust model for frame-level syllable detection. The third stage is semi-supervised post-training, which leverages the unlabeled data again. However, unlike the initial phase, this time it is aligned with the downstream task. The performance of this data-efficient approach is demonstrated for the complex song of the Canary in extreme label-scarcity scenarios. Canary has one of the most difficult songs to annotate, which implicitly validates the method for other birds. Finally, the potential of self-supervised embeddings is assessed for linear probing and unsupervised birdsong analysis.
Uncertainty Calibration of Multi-Label Bird Sound Classifiers
Nov 11, 2025Passive acoustic monitoring enables large-scale biodiversity assessment, but reliable classification of bioacoustic sounds requires not only high accuracy but also well-calibrated uncertainty estimates to ground decision-making. In bioacoustics, calibration is challenged by overlapping vocalisations, long-tailed species distributions, and distribution shifts between training and deployment data. The calibration of multi-label deep learning classifiers within the domain of bioacoustics has not yet been assessed. We systematically benchmark the calibration of four state-of-the-art multi-label bird sound classifiers on the BirdSet benchmark, evaluating both global, per-dataset and per-class calibration using threshold-free calibration metrics (ECE, MCS) alongside discrimination metrics (cmAP). Model calibration varies significantly across datasets and classes. While Perch v2 and ConvNeXt$_{BS}$ show better global calibration, results vary between datasets. Both models indicate consistent underconfidence, while AudioProtoPNet and BirdMAE are mostly overconfident. Surprisingly, calibration seems to be better for less frequent classes. Using simple post hoc calibration methods we demonstrate a straightforward way to improve calibration. A small labelled calibration set is sufficient to significantly improve calibration with Platt scaling, while global calibration parameters suffer from dataset variability. Our findings highlight the importance of evaluating and improving uncertainty calibration in bioacoustic classifiers.
Hashing-Baseline: Rethinking Hashing in the Age of Pretrained Models
Sep 17, 2025
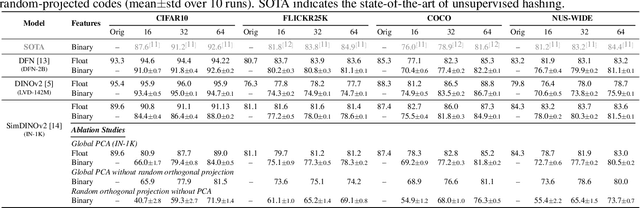


Information retrieval with compact binary embeddings, also referred to as hashing, is crucial for scalable fast search applications, yet state-of-the-art hashing methods require expensive, scenario-specific training. In this work, we introduce Hashing-Baseline, a strong training-free hashing method leveraging powerful pretrained encoders that produce rich pretrained embeddings. We revisit classical, training-free hashing techniques: principal component analysis, random orthogonal projection, and threshold binarization, to produce a strong baseline for hashing. Our approach combines these techniques with frozen embeddings from state-of-the-art vision and audio encoders to yield competitive retrieval performance without any additional learning or fine-tuning. To demonstrate the generality and effectiveness of this approach, we evaluate it on standard image retrieval benchmarks as well as a newly introduced benchmark for audio hashing.
Can Masked Autoencoders Also Listen to Birds?
Apr 17, 2025Masked Autoencoders (MAEs) pretrained on AudioSet fail to capture the fine-grained acoustic characteristics of specialized domains such as bioacoustic monitoring. Bird sound classification is critical for assessing environmental health, yet general-purpose models inadequately address its unique acoustic challenges. To address this, we introduce Bird-MAE, a domain-specialized MAE pretrained on the large-scale BirdSet dataset. We explore adjustments to pretraining, fine-tuning and utilizing frozen representations. Bird-MAE achieves state-of-the-art results across all BirdSet downstream tasks, substantially improving multi-label classification performance compared to the general-purpose Audio-MAE baseline. Additionally, we propose prototypical probing, a parameter-efficient method for leveraging MAEs' frozen representations. Bird-MAE's prototypical probes outperform linear probing by up to 37\% in MAP and narrow the gap to fine-tuning to approximately 3\% on average on BirdSet.
Multi-dataset synergistic in supervised learning to pre-label structural components in point clouds from shell construction scenes
Feb 20, 2025


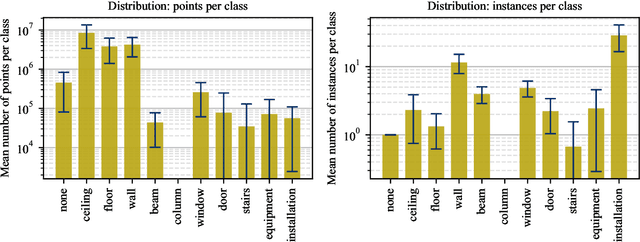
The significant effort required to annotate data for new training datasets hinders computer vision research and machine learning in the construction industry. This work explores adapting standard datasets and the latest transformer model architectures for point cloud semantic segmentation in the context of shell construction sites. Unlike common approaches focused on object segmentation of building interiors and furniture, this study addressed the challenges of segmenting complex structural components in Architecture, Engineering, and Construction (AEC). We establish a baseline through supervised training and a custom validation dataset, evaluate the cross-domain inference with large-scale indoor datasets, and utilize transfer learning to maximize segmentation performance with minimal new data. The findings indicate that with minimal fine-tuning, pre-trained transformer architectures offer an effective strategy for building component segmentation. Our results are promising for automating the annotation of new, previously unseen data when creating larger training resources and for the segmentation of frequently recurring objects.
dopanim: A Dataset of Doppelganger Animals with Noisy Annotations from Multiple Humans
Jul 30, 2024Human annotators typically provide annotated data for training machine learning models, such as neural networks. Yet, human annotations are subject to noise, impairing generalization performances. Methodological research on approaches counteracting noisy annotations requires corresponding datasets for a meaningful empirical evaluation. Consequently, we introduce a novel benchmark dataset, dopanim, consisting of about 15,750 animal images of 15 classes with ground truth labels. For approximately 10,500 of these images, 20 humans provided over 52,000 annotations with an accuracy of circa 67%. Its key attributes include (1) the challenging task of classifying doppelganger animals, (2) human-estimated likelihoods as annotations, and (3) annotator metadata. We benchmark well-known multi-annotator learning approaches using seven variants of this dataset and outline further evaluation use cases such as learning beyond hard class labels and active learning. Our dataset and a comprehensive codebase are publicly available to emulate the data collection process and to reproduce all empirical results.
Towards Deep Active Learning in Avian Bioacoustics
Jun 26, 2024

Passive acoustic monitoring (PAM) in avian bioacoustics enables cost-effective and extensive data collection with minimal disruption to natural habitats. Despite advancements in computational avian bioacoustics, deep learning models continue to encounter challenges in adapting to diverse environments in practical PAM scenarios. This is primarily due to the scarcity of annotations, which requires labor-intensive efforts from human experts. Active learning (AL) reduces annotation cost and speed ups adaption to diverse scenarios by querying the most informative instances for labeling. This paper outlines a deep AL approach, introduces key challenges, and conducts a small-scale pilot study.
Fast Fishing: Approximating BAIT for Efficient and Scalable Deep Active Image Classification
Apr 13, 2024



Deep active learning (AL) seeks to minimize the annotation costs for training deep neural networks. BAIT, a recently proposed AL strategy based on the Fisher Information, has demonstrated impressive performance across various datasets. However, BAIT's high computational and memory requirements hinder its applicability on large-scale classification tasks, resulting in current research neglecting BAIT in their evaluation. This paper introduces two methods to enhance BAIT's computational efficiency and scalability. Notably, we significantly reduce its time complexity by approximating the Fisher Information. In particular, we adapt the original formulation by i) taking the expectation over the most probable classes, and ii) constructing a binary classification task, leading to an alternative likelihood for gradient computations. Consequently, this allows the efficient use of BAIT on large-scale datasets, including ImageNet. Our unified and comprehensive evaluation across a variety of datasets demonstrates that our approximations achieve strong performance with considerably reduced time complexity. Furthermore, we provide an extensive open-source toolbox that implements recent state-of-the-art AL strategies, available at https://github.com/dhuseljic/dal-toolbox.
BirdSet: A Multi-Task Benchmark for Classification in Avian Bioacoustics
Mar 15, 2024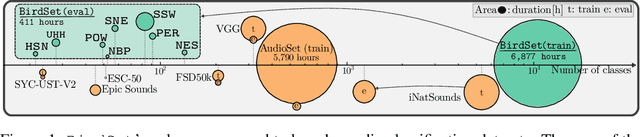
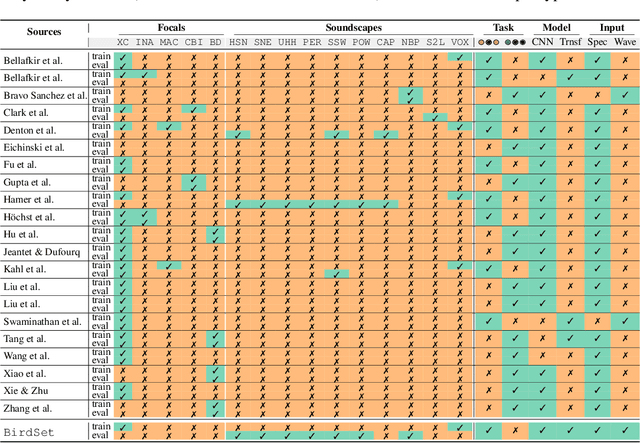

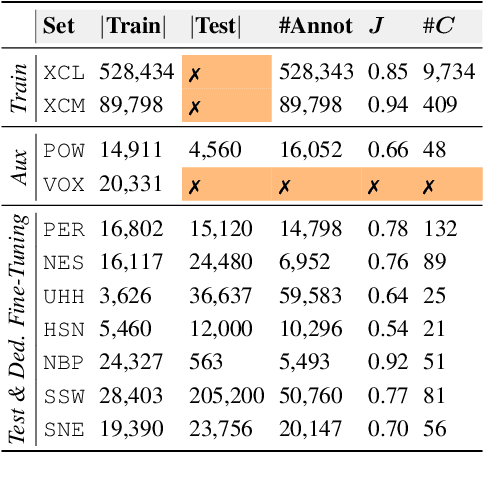
Deep learning (DL) models have emerged as a powerful tool in avian bioacoustics to diagnose environmental health and biodiversity. However, inconsistencies in research pose notable challenges hindering progress in this domain. Reliable DL models need to analyze bird calls flexibly across various species and environments to fully harness the potential of bioacoustics in a cost-effective passive acoustic monitoring scenario. Data fragmentation and opacity across studies complicate a comprehensive evaluation of general model performance. To overcome these challenges, we present the BirdSet benchmark, a unified framework consolidating research efforts with a holistic approach for classifying bird vocalizations in avian bioacoustics. BirdSet harmonizes open-source bird recordings into a curated dataset collection. This unified approach provides an in-depth understanding of model performance and identifies potential shortcomings across different tasks. By establishing baseline results of current models, BirdSet aims to facilitate comparability, guide subsequent data collection, and increase accessibility for newcomers to avian bioacoustics.