 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Structured to Unstructured:A Comparative Analysis of Computer Vision and Graph Models in solving Mesh-based PDEs
May 31, 2024This article investigates the application of computer vision and graph-based models in solving mesh-based partial differential equations within high-performance computing environments. Focusing on structured, graded structured, and unstructured meshes, the study compares the performance and computational efficiency of three computer vision-based models against three graph-based models across three data\-sets. The research aims to identify the most suitable models for different mesh topographies, particularly highlighting the exploration of graded meshes, a less studied area. Results demonstrate that computer vision-based models, notably U-Net, outperform the graph models in prediction performance and efficiency in two (structured and graded) out of three mesh topographies. The study also reveals the unexpected effectiveness of computer vision-based models in handling unstructured meshes, suggesting a potential shift in methodological approaches for data-driven partial differential equation learning. The article underscores deep learning as a viable and potentially sustainable way to enhance traditional high-performance computing methods, advocating for informed model selection based on the topography of the mesh.
An Efficient Multi Quantile Regression Network with Ad Hoc Prevention of Quantile Crossing
May 31, 2024This article presents the Sorting Composite Quantile Regression Neural Network (SCQRNN), an advanced quantile regression model designed to prevent quantile crossing and enhance computational efficiency. Integrating ad hoc sorting in training, the SCQRNN ensures non-intersecting quantiles, boosting model reliability and interpretability. We demonstrate that the SCQRNN not only prevents quantile crossing and reduces computational complexity but also achieves faster convergence than traditional models. This advancement meets the requirements of high-performance computing for sustainable, accurate computation. In organic computing, the SCQRNN enhances self-aware systems with predictive uncertainties, enriching applications across finance, meteorology, climate science, and engineering.
DADO -- Low-Cost Selection Strategies for Deep Active Design Optimization
Jul 10, 2023



In this experience report, we apply deep active learning to the field of design optimization to reduce the number of computationally expensive numerical simulations. We are interested in optimizing the design of structural components, where the shape is described by a set of parameters. If we can predict the performance based on these parameters and consider only the promising candidates for simulation, there is an enormous potential for saving computing power. We present two selection strategies for self-optimization to reduce the computational cost in multi-objective design optimization problems. Our proposed methodology provides an intuitive approach that is easy to apply, offers significant improvements over random sampling, and circumvents the need for uncertainty estimation. We evaluate our strategies on a large dataset from the domain of fluid dynamics and introduce two new evaluation metrics to determine the model's performance. Findings from our evaluation highlights the effectiveness of our selection strategies in accelerating design optimization. We believe that the introduced method is easily transferable to other self-optimization problems.
Variational Bayesian Inference for Hidden Markov Models With Multivariate Gaussian Output Distributions
May 27, 2016
Hidden Markov Models (HMM) have been used for several years in many time series analysis or pattern recognitions tasks. HMM are often trained by means of the Baum-Welch algorithm which can be seen as a special variant of an expectation maximization (EM) algorithm. Second-order training techniques such as Variational Bayesian Inference (VI) for probabilistic models regard the parameters of the probabilistic models as random variables and define distributions over these distribution parameters, hence the name of this technique. VI can also bee regarded as a special case of an EM algorithm. In this article, we bring both together and train HMM with multivariate Gaussian output distributions with VI. The article defines the new training technique for HMM. An evaluation based on some case studies and a comparison to related approaches is part of our ongoing work.
Towards Automation of Knowledge Understanding: An Approach for Probabilistic Generative Classifiers
May 20, 2016

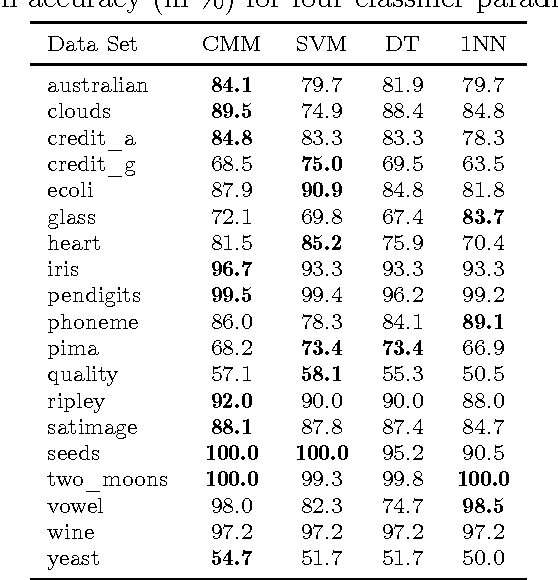

After data selection, pre-processing, transformation, and feature extraction, knowledge extraction is not the final step in a data mining process. It is then necessary to understand this knowledge in order to apply it efficiently and effectively. Up to now, there is a lack of appropriate techniques that support this significant step. This is partly due to the fact that the assessment of knowledge is often highly subjective, e.g., regarding aspects such as novelty or usefulness. These aspects depend on the specific knowledge and requirements of the data miner. There are, however, a number of aspects that are objective and for which it is possible to provide appropriate measures. In this article we focus on classification problems and use probabilistic generative classifiers based on mixture density models that are quite common in data mining applications. We define objective measures to assess the informativeness, uniqueness, importance, discrimination, representativity, uncertainty, and distinguishability of rules contained in these classifiers numerically. These measures not only support a data miner in evaluating results of a data mining process based on such classifiers. As we will see in illustrative case studies, they may also be used to improve the data mining process itself or to support the later application of the extracted knowledge.
Detecting Novel Processes with CANDIES -- An Holistic Novelty Detection Technique based on Probabilistic Models
May 18, 2016



In this article, we propose CANDIES (Combined Approach for Novelty Detection in Intelligent Embedded Systems), a new approach to novelty detection in technical systems. We assume that in a technical system several processes interact. If we observe these processes with sensors, we are able to model the observations (samples) with a probabilistic model, where, in an ideal case, the components of the parametric mixture density model we use, correspond to the processes in the real world. Eventually, at run-time, novel processes emerge in the technical systems such as in the case of an unpredictable failure. As a consequence, new kinds of samples are observed that require an adaptation of the model. CANDIES relies on mixtures of Gaussians which can be used for classification purposes, too. New processes may emerge in regions of the models' input spaces where few samples were observed before (low-density regions) or in regions where already many samples were available (high-density regions). The latter case is more difficult, but most existing solutions focus on the former. Novelty detection in low- and high-density regions requires different detection strategies. With CANDIES, we introduce a new technique to detect novel processes in high-density regions by means of a fast online goodness-of-fit test. For detection in low-density regions we combine this approach with a 2SND (Two-Stage-Novelty-Detector) which we presented in preliminary work. The properties of CANDIES are evaluated using artificial data and benchmark data from the field of intrusion detection in computer networks, where the task is to detect new kinds of attacks.