 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Automation of Knowledge Understanding: An Approach for Probabilistic Generative Classifiers
May 20, 2016

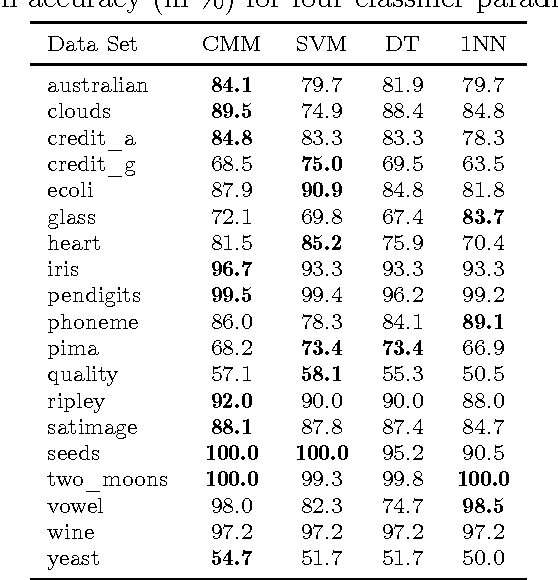

After data selection, pre-processing, transformation, and feature extraction, knowledge extraction is not the final step in a data mining process. It is then necessary to understand this knowledge in order to apply it efficiently and effectively. Up to now, there is a lack of appropriate techniques that support this significant step. This is partly due to the fact that the assessment of knowledge is often highly subjective, e.g., regarding aspects such as novelty or usefulness. These aspects depend on the specific knowledge and requirements of the data miner. There are, however, a number of aspects that are objective and for which it is possible to provide appropriate measures. In this article we focus on classification problems and use probabilistic generative classifiers based on mixture density models that are quite common in data mining applications. We define objective measures to assess the informativeness, uniqueness, importance, discrimination, representativity, uncertainty, and distinguishability of rules contained in these classifiers numerically. These measures not only support a data miner in evaluating results of a data mining process based on such classifiers. As we will see in illustrative case studies, they may also be used to improve the data mining process itself or to support the later application of the extracted knowledge.