 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Learning as Discrete Communication
Feb 10, 2026Most self-supervised learning (SSL) methods learn continuous visual representations by aligning different views of the same input, offering limited control over how information is structured across representation dimensions. In this work, we frame visual self-supervised learning as a discrete communication process between a teacher and a student network, where semantic information is transmitted through a fixed-capacity binary channel. Rather than aligning continuous features, the student predicts multi-label binary messages produced by the teacher. Discrete agreement is enforced through an element-wise binary cross-entropy objective, while a coding-rate regularization term encourages effective utilization of the constrained channel, promoting structured representations. We further show that periodically reinitializing the projection head strengthens this effect by encouraging embeddings that remain predictive across multiple discrete encodings. Extensive experiments demonstrate consistent improvements over continuous agreement baselines on image classification, retrieval, and dense visual prediction tasks, as well as under domain shift through self-supervised adaptation. Beyond backbone representations, we analyze the learned binary codes and show that they form a compact and informative discrete language, capturing semantic factors reusable across classes.
Audio-to-Image Bird Species Retrieval without Audio-Image Pairs via Text Distillation
Jan 31, 2026Audio-to-image retrieval offers an interpretable alternative to audio-only classification for bioacoustic species recognition, but learning aligned audio-image representations is challenging due to the scarcity of paired audio-image data. We propose a simple and data-efficient approach that enables audio-to-image retrieval without any audio-image supervision. Our proposed method uses text as a semantic intermediary: we distill the text embedding space of a pretrained image-text model (BioCLIP-2), which encodes rich visual and taxonomic structure, into a pretrained audio-text model (BioLingual) by fine-tuning its audio encoder with a contrastive objective. This distillation transfers visually grounded semantics into the audio representation, inducing emergent alignment between audio and image embeddings without using images during training. We evaluate the resulting model on multiple bioacoustic benchmarks. The distilled audio encoder preserves audio discriminative power while substantially improving audio-text alignment on focal recordings and soundscape datasets. Most importantly, on the SSW60 benchmark, the proposed approach achieves strong audio-to-image retrieval performance exceeding baselines based on zero-shot model combinations or learned mappings between text embeddings, despite not training on paired audio-image data. These results demonstrate that indirect semantic transfer through text is sufficient to induce meaningful audio-image alignment, providing a practical solution for visually grounded species recognition in data-scarce bioacoustic settings.
Compact Hypercube Embeddings for Fast Text-based Wildlife Observation Retrieval
Jan 30, 2026Large-scale biodiversity monitoring platforms increasingly rely on multimodal wildlife observations. While recent foundation models enable rich semantic representations across vision, audio, and language, retrieving relevant observations from massive archives remains challenging due to the computational cost of high-dimensional similarity search. In this work, we introduce compact hypercube embeddings for fast text-based wildlife observation retrieval, a framework that enables efficient text-based search over large-scale wildlife image and audio databases using compact binary representations. Building on the cross-view code alignment hashing framework, we extend lightweight hashing beyond a single-modality setup to align natural language descriptions with visual or acoustic observations in a shared Hamming space. Our approach leverages pretrained wildlife foundation models, including BioCLIP and BioLingual, and adapts them efficiently for hashing using parameter-efficient fine-tuning. We evaluate our method on large-scale benchmarks, including iNaturalist2024 for text-to-image retrieval and iNatSounds2024 for text-to-audio retrieval, as well as multiple soundscape datasets to assess robustness under domain shift. Results show that retrieval using discrete hypercube embeddings achieves competitive, and in several cases superior, performance compared to continuous embeddings, while drastically reducing memory and search cost. Moreover, we observe that the hashing objective consistently improves the underlying encoder representations, leading to stronger retrieval and zero-shot generalization. These results demonstrate that binary, language-based retrieval enables scalable and efficient search over large wildlife archives for biodiversity monitoring systems.
Image Hashing via Cross-View Code Alignment in the Age of Foundation Models
Nov 03, 2025Efficient large-scale retrieval requires representations that are both compact and discriminative. Foundation models provide powerful visual and multimodal embeddings, but nearest neighbor search in these high-dimensional spaces is computationally expensive. Hashing offers an efficient alternative by enabling fast Hamming distance search with binary codes, yet existing approaches often rely on complex pipelines, multi-term objectives, designs specialized for a single learning paradigm, and long training times. We introduce CroVCA (Cross-View Code Alignment), a simple and unified principle for learning binary codes that remain consistent across semantically aligned views. A single binary cross-entropy loss enforces alignment, while coding-rate maximization serves as an anti-collapse regularizer to promote balanced and diverse codes. To implement this, we design HashCoder, a lightweight MLP hashing network with a final batch normalization layer to enforce balanced codes. HashCoder can be used as a probing head on frozen embeddings or to adapt encoders efficiently via LoRA fine-tuning. Across benchmarks, CroVCA achieves state-of-the-art results in just 5 training epochs. At 16 bits, it particularly well-for instance, unsupervised hashing on COCO completes in under 2 minutes and supervised hashing on ImageNet100 in about 3 minutes on a single GPU. These results highlight CroVCA's efficiency, adaptability, and broad applicability.
Hashing-Baseline: Rethinking Hashing in the Age of Pretrained Models
Sep 17, 2025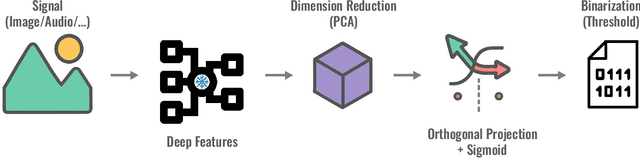
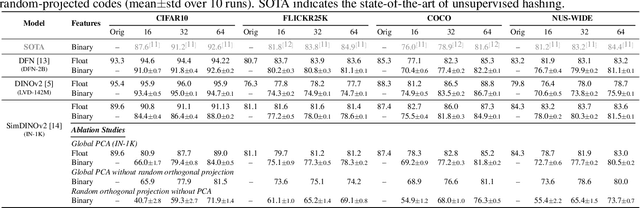


Information retrieval with compact binary embeddings, also referred to as hashing, is crucial for scalable fast search applications, yet state-of-the-art hashing methods require expensive, scenario-specific training. In this work, we introduce Hashing-Baseline, a strong training-free hashing method leveraging powerful pretrained encoders that produce rich pretrained embeddings. We revisit classical, training-free hashing techniques: principal component analysis, random orthogonal projection, and threshold binarization, to produce a strong baseline for hashing. Our approach combines these techniques with frozen embeddings from state-of-the-art vision and audio encoders to yield competitive retrieval performance without any additional learning or fine-tuning. To demonstrate the generality and effectiveness of this approach, we evaluate it on standard image retrieval benchmarks as well as a newly introduced benchmark for audio hashing.
Can Masked Autoencoders Also Listen to Birds?
Apr 17, 2025Masked Autoencoders (MAEs) pretrained on AudioSet fail to capture the fine-grained acoustic characteristics of specialized domains such as bioacoustic monitoring. Bird sound classification is critical for assessing environmental health, yet general-purpose models inadequately address its unique acoustic challenges. To address this, we introduce Bird-MAE, a domain-specialized MAE pretrained on the large-scale BirdSet dataset. We explore adjustments to pretraining, fine-tuning and utilizing frozen representations. Bird-MAE achieves state-of-the-art results across all BirdSet downstream tasks, substantially improving multi-label classification performance compared to the general-purpose Audio-MAE baseline. Additionally, we propose prototypical probing, a parameter-efficient method for leveraging MAEs' frozen representations. Bird-MAE's prototypical probes outperform linear probing by up to 37\% in MAP and narrow the gap to fine-tuning to approximately 3\% on average on BirdSet.
Domain-Invariant Representation Learning of Bird Sounds
Sep 16, 2024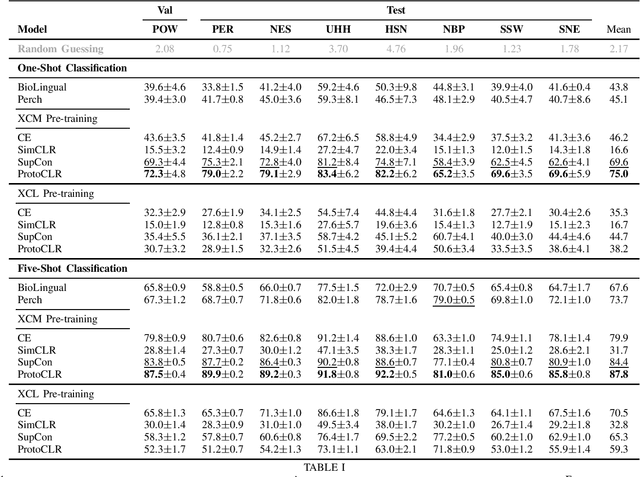
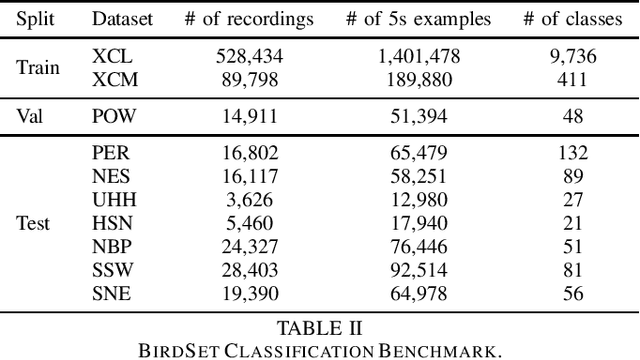
Passive acoustic monitoring (PAM) is crucial for bioacoustic research, enabling non-invasive species tracking and biodiversity monitoring. Citizen science platforms like Xeno-Canto provide large annotated datasets from focal recordings, where the target species is intentionally recorded. However, PAM requires monitoring in passive soundscapes, creating a domain shift between focal and passive recordings, which challenges deep learning models trained on focal recordings. To address this, we leverage supervised contrastive learning to improve domain generalization in bird sound classification, enforcing domain invariance across same-class examples from different domains. We also propose ProtoCLR (Prototypical Contrastive Learning of Representations), which reduces the computational complexity of the SupCon loss by comparing examples to class prototypes instead of pairwise comparisons. Additionally, we present a new few-shot classification benchmark based on BirdSet, a large-scale bird sound dataset, and demonstrate the effectiveness of our approach in achieving strong transfer performance.
Acoustic identification of individual animals with hierarchical contrastive learning
Sep 13, 2024



Acoustic identification of individual animals (AIID) is closely related to audio-based species classification but requires a finer level of detail to distinguish between individual animals within the same species. In this work, we frame AIID as a hierarchical multi-label classification task and propose the use of hierarchy-aware loss functions to learn robust representations of individual identities that maintain the hierarchical relationships among species and taxa. Our results demonstrate that hierarchical embeddings not only enhance identification accuracy at the individual level but also at higher taxonomic levels, effectively preserving the hierarchical structure in the learned representations. By comparing our approach with non-hierarchical models, we highlight the advantage of enforcing this structure in the embedding space. Additionally, we extend the evaluation to the classification of novel individual classes, demonstrating the potential of our method in open-set classification scenarios.
Mixture of Mixups for Multi-label Classification of Rare Anuran Sounds
Mar 14, 2024



Multi-label imbalanced classification poses a significant challenge in machine learning, particularly evident in bioacoustics where animal sounds often co-occur, and certain sounds are much less frequent than others. This paper focuses on the specific case of classifying anuran species sounds using the dataset AnuraSet, that contains both class imbalance and multi-label examples. To address these challenges, we introduce Mixture of Mixups (Mix2), a framework that leverages mixing regularization methods Mixup, Manifold Mixup, and MultiMix. Experimental results show that these methods, individually, may lead to suboptimal results; however, when applied randomly, with one selected at each training iteration, they prove effective in addressing the mentioned challenges, particularly for rare classes with few occurrences. Further analysis reveals that Mix2 is also proficient in classifying sounds across various levels of class co-occurrences.
Self-Supervised Learning for Few-Shot Bird Sound Classification
Jan 16, 2024
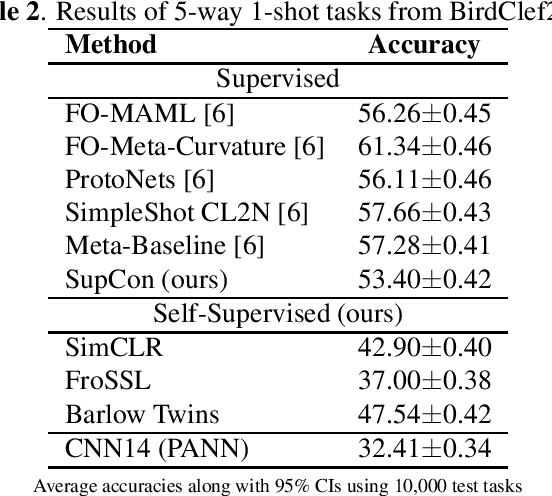
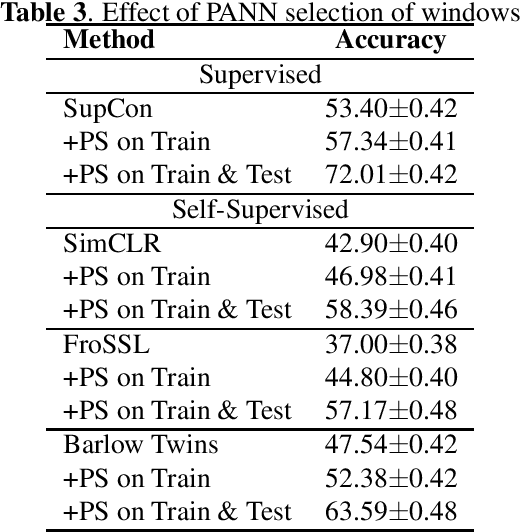
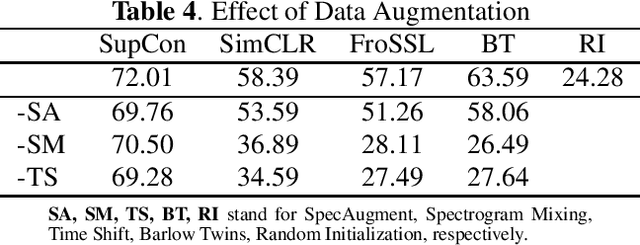
Self-supervised learning (SSL) in audio holds significant potential across various domains, particularly in situations where abundant, unlabeled data is readily available at no cost. This is particularly pertinent in bioacoustics, where biologists routinely collect extensive sound datasets from the natural environment. In this study, we demonstrate that SSL is capable of acquiring meaningful representations of bird sounds from audio recordings without the need for annotations. Our experiments showcase that these learned representations exhibit the capacity to generalize to new bird species in few-shot learning (FSL) scenarios. Additionally, we show that selecting windows with high bird activation for self-supervised learning, using a pretrained audio neural network, significantly enhances the quality of the learned representations.