 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan pre-trained Deep Learning models predict groove ratings?
Mar 28, 2026This study explores the extent to which deep learning models can predict groove and its related perceptual dimensions directly from audio signals. We critically examine the effectiveness of seven state-of-the-art deep learning models in predicting groove ratings and responses to groove-related queries through the extraction of audio embeddings. Additionally, we compare these predictions with traditional handcrafted audio features. To better understand the underlying mechanics, we extend this methodology to analyze predictions based on source-separated instruments, thereby isolating the contributions of individual musical elements. Our analysis reveals a clear separation of groove characteristics driven by the underlying musical style of the tracks (funk, pop, and rock). These findings indicate that deep audio representations can successfully encode complex, style-dependent groove components that traditional features often miss. Ultimately, this work highlights the capacity of advanced deep learning models to capture the multifaceted concept of groove, demonstrating the strong potential of representation learning to advance predictive Music Information Retrieval methodologies.
REVE: A Foundation Model for EEG -- Adapting to Any Setup with Large-Scale Pretraining on 25,000 Subjects
Oct 24, 2025Foundation models have transformed AI by reducing reliance on task-specific data through large-scale pretraining. While successful in language and vision, their adoption in EEG has lagged due to the heterogeneity of public datasets, which are collected under varying protocols, devices, and electrode configurations. Existing EEG foundation models struggle to generalize across these variations, often restricting pretraining to a single setup, resulting in suboptimal performance, in particular under linear probing. We present REVE (Representation for EEG with Versatile Embeddings), a pretrained model explicitly designed to generalize across diverse EEG signals. REVE introduces a novel 4D positional encoding scheme that enables it to process signals of arbitrary length and electrode arrangement. Using a masked autoencoding objective, we pretrain REVE on over 60,000 hours of EEG data from 92 datasets spanning 25,000 subjects, representing the largest EEG pretraining effort to date. REVE achieves state-of-the-art results on 10 downstream EEG tasks, including motor imagery classification, seizure detection, sleep staging, cognitive load estimation, and emotion recognition. With little to no fine-tuning, it demonstrates strong generalization, and nuanced spatio-temporal modeling. We release code, pretrained weights, and tutorials to support standardized EEG research and accelerate progress in clinical neuroscience.
Domain-Invariant Representation Learning of Bird Sounds
Sep 16, 2024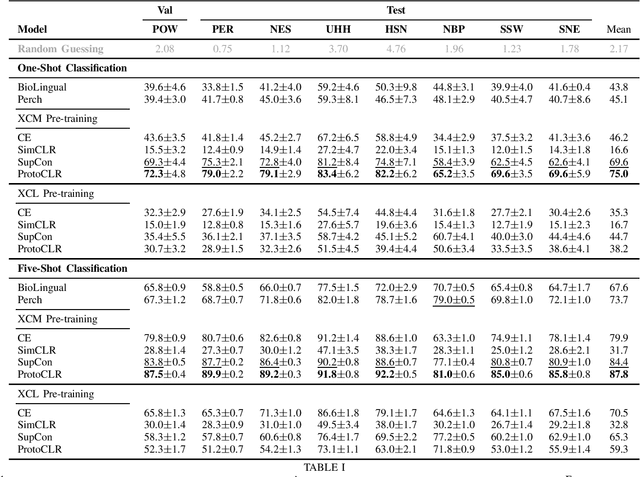
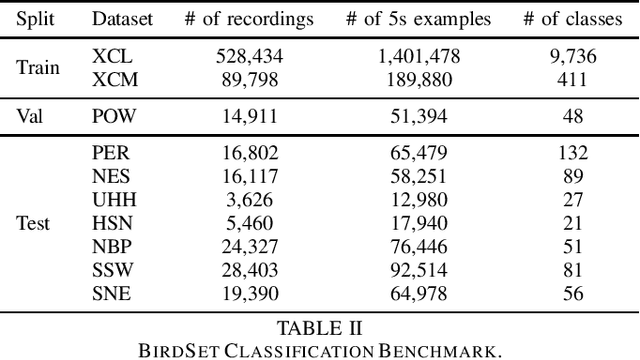
Passive acoustic monitoring (PAM) is crucial for bioacoustic research, enabling non-invasive species tracking and biodiversity monitoring. Citizen science platforms like Xeno-Canto provide large annotated datasets from focal recordings, where the target species is intentionally recorded. However, PAM requires monitoring in passive soundscapes, creating a domain shift between focal and passive recordings, which challenges deep learning models trained on focal recordings. To address this, we leverage supervised contrastive learning to improve domain generalization in bird sound classification, enforcing domain invariance across same-class examples from different domains. We also propose ProtoCLR (Prototypical Contrastive Learning of Representations), which reduces the computational complexity of the SupCon loss by comparing examples to class prototypes instead of pairwise comparisons. Additionally, we present a new few-shot classification benchmark based on BirdSet, a large-scale bird sound dataset, and demonstrate the effectiveness of our approach in achieving strong transfer performance.
Unsupervised Adaptive Deep Learning Method For BCI Motor Imagery Decoding
Mar 15, 2024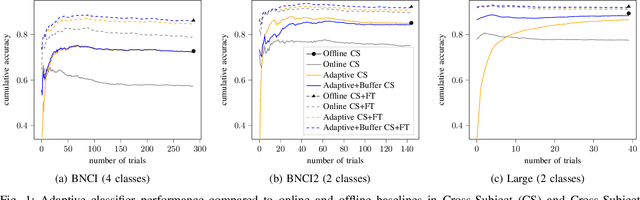
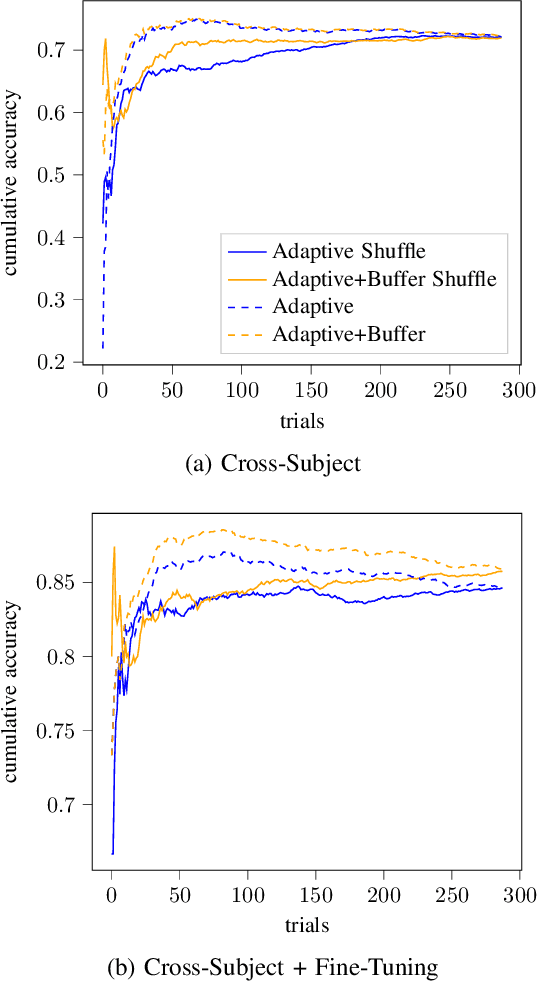
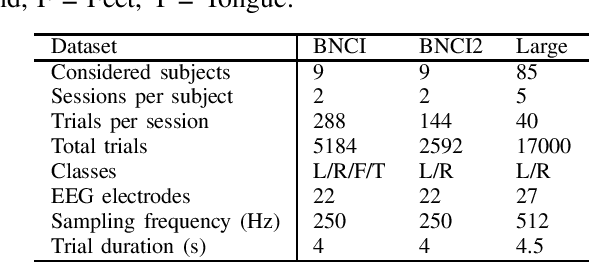
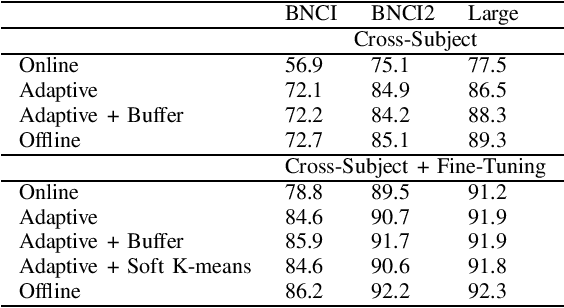
In the context of Brain-Computer Interfaces, we propose an adaptive method that reaches offline performance level while being usable online without requiring supervision. Interestingly, our method does not require retraining the model, as it consists in using a frozen efficient deep learning backbone while continuously realigning data, both at input and latent spaces, based on streaming observations. We demonstrate its efficiency for Motor Imagery brain decoding from electroencephalography data, considering challenging cross-subject scenarios. For reproducibility, we share the code of our experiments.
Mixture of Mixups for Multi-label Classification of Rare Anuran Sounds
Mar 14, 2024



Multi-label imbalanced classification poses a significant challenge in machine learning, particularly evident in bioacoustics where animal sounds often co-occur, and certain sounds are much less frequent than others. This paper focuses on the specific case of classifying anuran species sounds using the dataset AnuraSet, that contains both class imbalance and multi-label examples. To address these challenges, we introduce Mixture of Mixups (Mix2), a framework that leverages mixing regularization methods Mixup, Manifold Mixup, and MultiMix. Experimental results show that these methods, individually, may lead to suboptimal results; however, when applied randomly, with one selected at each training iteration, they prove effective in addressing the mentioned challenges, particularly for rare classes with few occurrences. Further analysis reveals that Mix2 is also proficient in classifying sounds across various levels of class co-occurrences.
Self-Supervised Learning for Few-Shot Bird Sound Classification
Jan 16, 2024
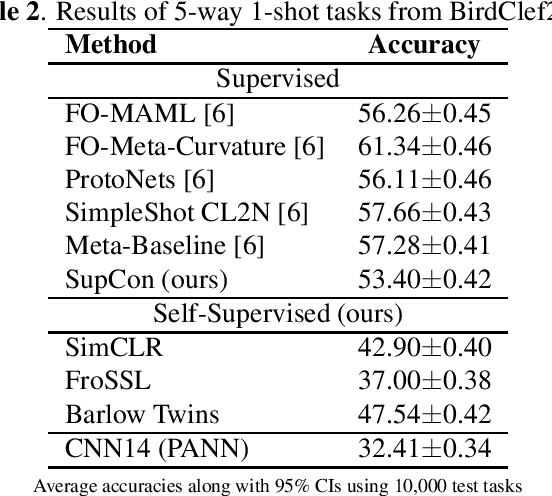
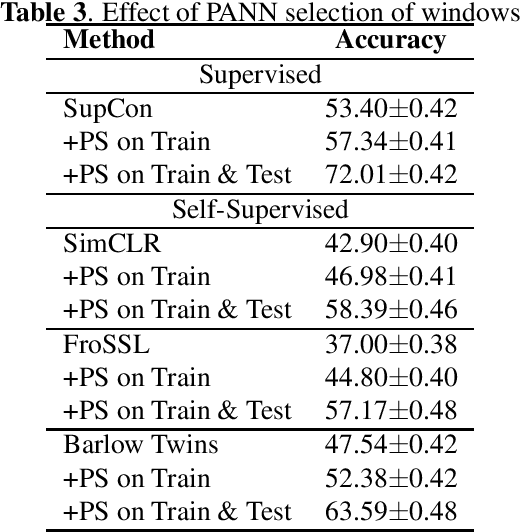
Self-supervised learning (SSL) in audio holds significant potential across various domains, particularly in situations where abundant, unlabeled data is readily available at no cost. This is particularly pertinent in bioacoustics, where biologists routinely collect extensive sound datasets from the natural environment. In this study, we demonstrate that SSL is capable of acquiring meaningful representations of bird sounds from audio recordings without the need for annotations. Our experiments showcase that these learned representations exhibit the capacity to generalize to new bird species in few-shot learning (FSL) scenarios. Additionally, we show that selecting windows with high bird activation for self-supervised learning, using a pretrained audio neural network, significantly enhances the quality of the learned representations.
Multi-Modal Learning-based Reconstruction of High-Resolution Spatial Wind Speed Fields
Dec 14, 2023



Wind speed at sea surface is a key quantity for a variety of scientific applications and human activities. Due to the non-linearity of the phenomenon, a complete description of such variable is made infeasible on both the small scale and large spatial extents. Methods relying on Data Assimilation techniques, despite being the state-of-the-art for Numerical Weather Prediction, can not provide the reconstructions with a spatial resolution that can compete with satellite imagery. In this work we propose a framework based on Variational Data Assimilation and Deep Learning concepts. This framework is applied to recover rich-in-time, high-resolution information on sea surface wind speed. We design our experiments using synthetic wind data and different sampling schemes for high-resolution and low-resolution versions of original data to emulate the real-world scenario of spatio-temporally heterogeneous observations. Extensive numerical experiments are performed to assess systematically the impact of low and high-resolution wind fields and in-situ observations on the model reconstruction performance. We show that in-situ observations with richer temporal resolution represent an added value in terms of the model reconstruction performance. We show how a multi-modal approach, that explicitly informs the model about the heterogeneity of the available observations, can improve the reconstruction task by exploiting the complementary information in spatial and local point-wise data. To conclude, we propose an analysis to test the robustness of the chosen framework against phase delay and amplitude biases in low-resolution data and against interruptions of in-situ observations supply at evaluation time
Regularized Contrastive Pre-training for Few-shot Bioacoustic Sound Detection
Sep 16, 2023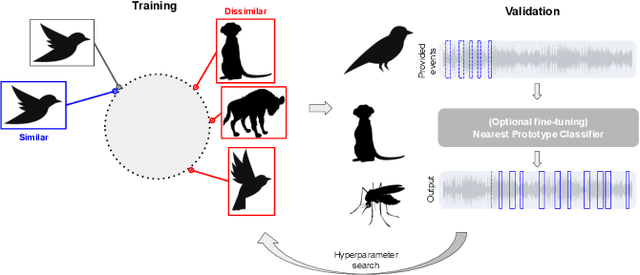
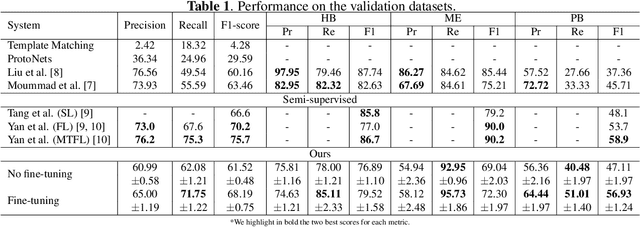
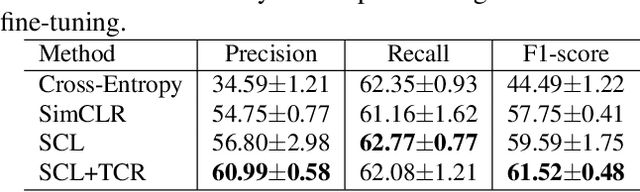
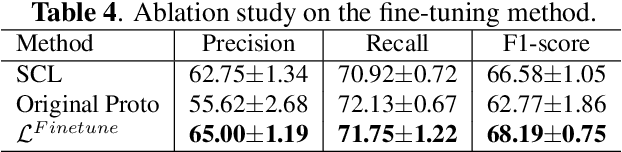
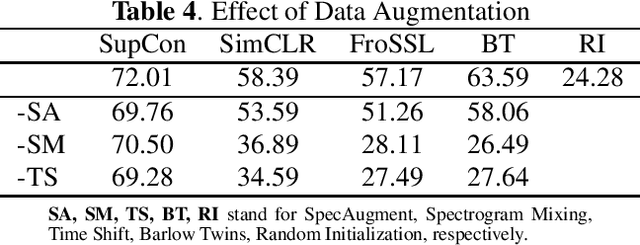
Bioacoustic sound event detection allows for better understanding of animal behavior and for better monitoring biodiversity using audio. Deep learning systems can help achieve this goal, however it is difficult to acquire sufficient annotated data to train these systems from scratch. To address this limitation, the Detection and Classification of Acoustic Scenes and Events (DCASE) community has recasted the problem within the framework of few-shot learning and organize an annual challenge for learning to detect animal sounds from only five annotated examples. In this work, we regularize supervised contrastive pre-training to learn features that can transfer well on new target tasks with animal sounds unseen during training, achieving a high F-score of 61.52%(0.48) when no feature adaptation is applied, and an F-score of 68.19%(0.75) when we further adapt the learned features for each new target task. This work aims to lower the entry bar to few-shot bioacoustic sound event detection by proposing a simple and yet effective framework for this task, by also providing open-source code.
A Strong and Simple Deep Learning Baseline for BCI MI Decoding
Sep 11, 2023
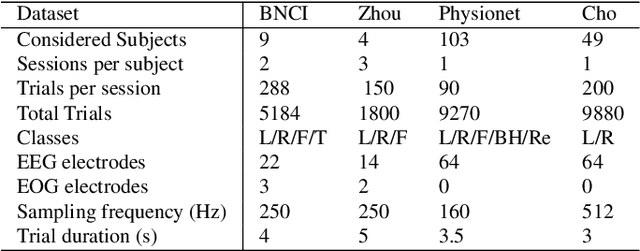


We propose EEG-SimpleConv, a straightforward 1D convolutional neural network for Motor Imagery decoding in BCI. Our main motivation is to propose a very simple baseline to compare to, using only very standard ingredients from the literature. We evaluate its performance on four EEG Motor Imagery datasets, including simulated online setups, and compare it to recent Deep Learning and Machine Learning approaches. EEG-SimpleConv is at least as good or far more efficient than other approaches, showing strong knowledge-transfer capabilities across subjects, at the cost of a low inference time. We advocate that using off-the-shelf ingredients rather than coming with ad-hoc solutions can significantly help the adoption of Deep Learning approaches for BCI. We make the code of the models and the experiments accessible.
Pretraining Representations for Bioacoustic Few-shot Detection using Supervised Contrastive Learning
Sep 02, 2023


Deep learning has been widely used recently for sound event detection and classification. Its success is linked to the availability of sufficiently large datasets, possibly with corresponding annotations when supervised learning is considered. In bioacoustic applications, most tasks come with few labelled training data, because annotating long recordings is time consuming and costly. Therefore supervised learning is not the best suited approach to solve bioacoustic tasks. The bioacoustic community recasted the problem of sound event detection within the framework of few-shot learning, i.e. training a system with only few labeled examples. The few-shot bioacoustic sound event detection task in the DCASE challenge focuses on detecting events in long audio recordings given only five annotated examples for each class of interest. In this paper, we show that learning a rich feature extractor from scratch can be achieved by leveraging data augmentation using a supervised contrastive learning framework. We highlight the ability of this framework to transfer well for five-shot event detection on previously unseen classes in the training data. We obtain an F-score of 63.46\% on the validation set and 42.7\% on the test set, ranking second in the DCASE challenge. We provide an ablation study for the critical choices of data augmentation techniques as well as for the learning strategy applied on the training set.