 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREVE: A Foundation Model for EEG -- Adapting to Any Setup with Large-Scale Pretraining on 25,000 Subjects
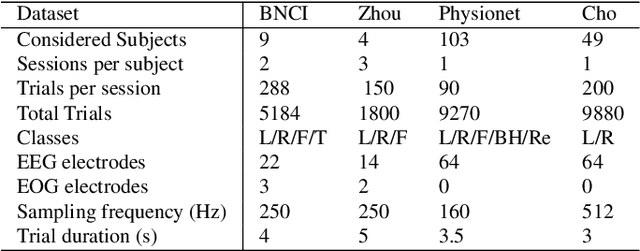
Oct 24, 2025Foundation models have transformed AI by reducing reliance on task-specific data through large-scale pretraining. While successful in language and vision, their adoption in EEG has lagged due to the heterogeneity of public datasets, which are collected under varying protocols, devices, and electrode configurations. Existing EEG foundation models struggle to generalize across these variations, often restricting pretraining to a single setup, resulting in suboptimal performance, in particular under linear probing. We present REVE (Representation for EEG with Versatile Embeddings), a pretrained model explicitly designed to generalize across diverse EEG signals. REVE introduces a novel 4D positional encoding scheme that enables it to process signals of arbitrary length and electrode arrangement. Using a masked autoencoding objective, we pretrain REVE on over 60,000 hours of EEG data from 92 datasets spanning 25,000 subjects, representing the largest EEG pretraining effort to date. REVE achieves state-of-the-art results on 10 downstream EEG tasks, including motor imagery classification, seizure detection, sleep staging, cognitive load estimation, and emotion recognition. With little to no fine-tuning, it demonstrates strong generalization, and nuanced spatio-temporal modeling. We release code, pretrained weights, and tutorials to support standardized EEG research and accelerate progress in clinical neuroscience.
LLM meets Vision-Language Models for Zero-Shot One-Class Classification
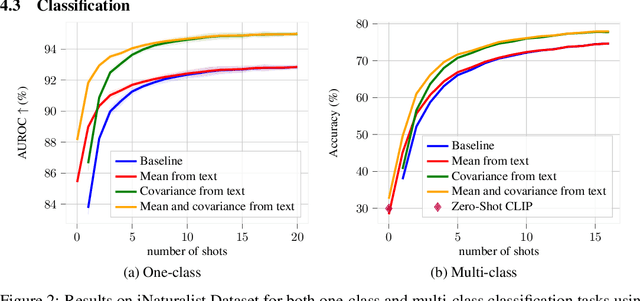
Apr 02, 2024We consider the problem of zero-shot one-class visual classification. In this setting, only the label of the target class is available, and the goal is to discriminate between positive and negative query samples without requiring any validation example from the target task. We propose a two-step solution that first queries large language models for visually confusing objects and then relies on vision-language pre-trained models (e.g., CLIP) to perform classification. By adapting large-scale vision benchmarks, we demonstrate the ability of the proposed method to outperform adapted off-the-shelf alternatives in this setting. Namely, we propose a realistic benchmark where negative query samples are drawn from the same original dataset as positive ones, including a granularity-controlled version of iNaturalist, where negative samples are at a fixed distance in the taxonomy tree from the positive ones. Our work shows that it is possible to discriminate between a single category and other semantically related ones using only its label
Unsupervised Adaptive Deep Learning Method For BCI Motor Imagery Decoding
Mar 15, 2024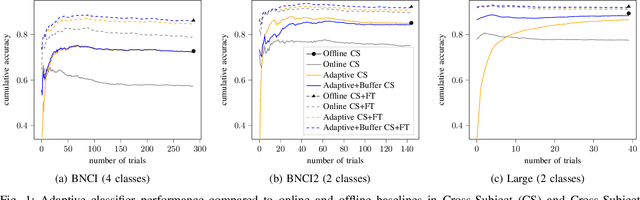
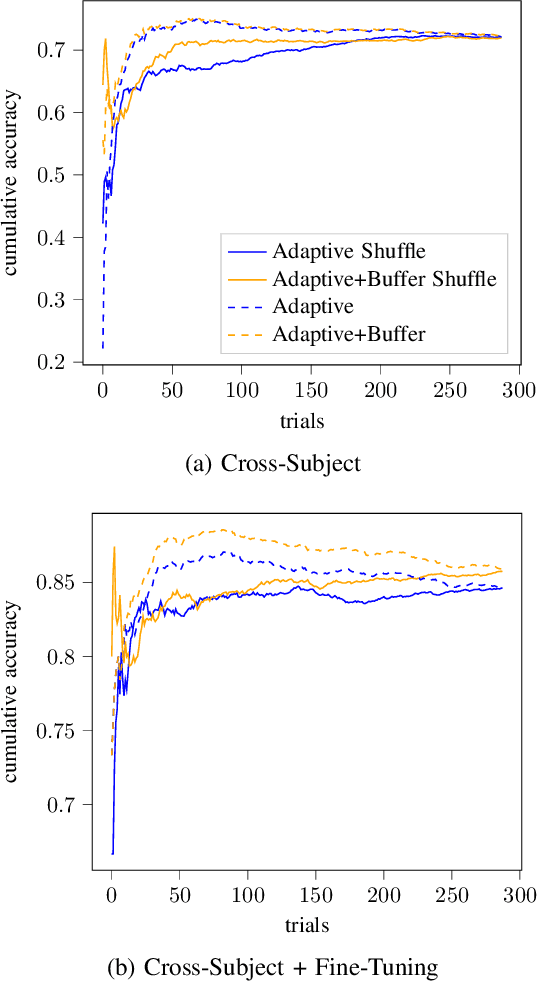
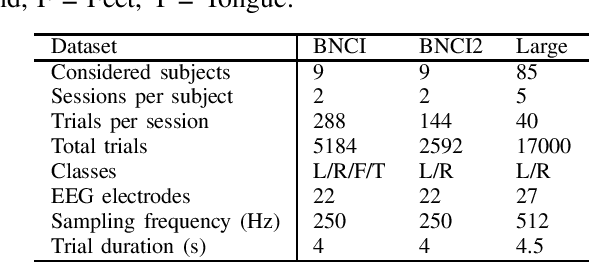
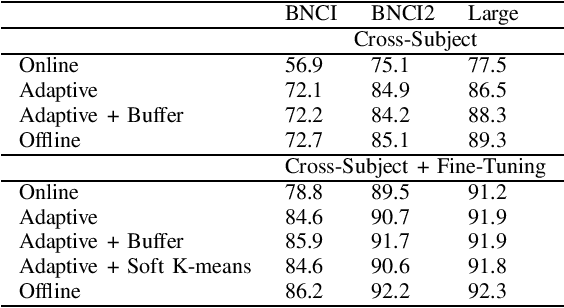
In the context of Brain-Computer Interfaces, we propose an adaptive method that reaches offline performance level while being usable online without requiring supervision. Interestingly, our method does not require retraining the model, as it consists in using a frozen efficient deep learning backbone while continuously realigning data, both at input and latent spaces, based on streaming observations. We demonstrate its efficiency for Motor Imagery brain decoding from electroencephalography data, considering challenging cross-subject scenarios. For reproducibility, we share the code of our experiments.
Inferring Latent Class Statistics from Text for Robust Visual Few-Shot Learning
Nov 24, 2023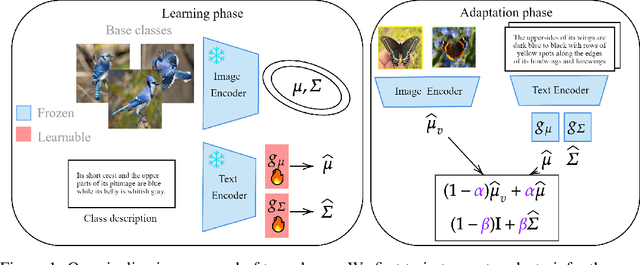


In the realm of few-shot learning, foundation models like CLIP have proven effective but exhibit limitations in cross-domain robustness especially in few-shot settings. Recent works add text as an extra modality to enhance the performance of these models. Most of these approaches treat text as an auxiliary modality without fully exploring its potential to elucidate the underlying class visual features distribution. In this paper, we present a novel approach that leverages text-derived statistics to predict the mean and covariance of the visual feature distribution for each class. This predictive framework enriches the latent space, yielding more robust and generalizable few-shot learning models. We demonstrate the efficacy of incorporating both mean and covariance statistics in improving few-shot classification performance across various datasets. Our method shows that we can use text to predict the mean and covariance of the distribution offering promising improvements in few-shot learning scenarios.
A Strong and Simple Deep Learning Baseline for BCI MI Decoding
Sep 11, 2023


We propose EEG-SimpleConv, a straightforward 1D convolutional neural network for Motor Imagery decoding in BCI. Our main motivation is to propose a very simple baseline to compare to, using only very standard ingredients from the literature. We evaluate its performance on four EEG Motor Imagery datasets, including simulated online setups, and compare it to recent Deep Learning and Machine Learning approaches. EEG-SimpleConv is at least as good or far more efficient than other approaches, showing strong knowledge-transfer capabilities across subjects, at the cost of a low inference time. We advocate that using off-the-shelf ingredients rather than coming with ad-hoc solutions can significantly help the adoption of Deep Learning approaches for BCI. We make the code of the models and the experiments accessible.
Disambiguation of One-Shot Visual Classification Tasks: A Simplex-Based Approach
Jan 16, 2023
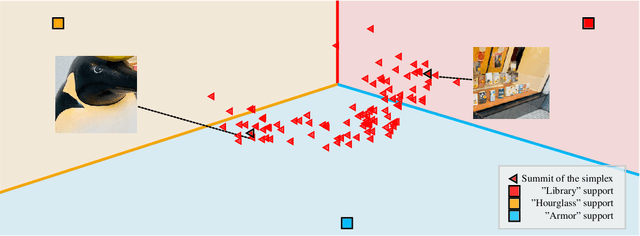

The field of visual few-shot classification aims at transferring the state-of-the-art performance of deep learning visual systems onto tasks where only a very limited number of training samples are available. The main solution consists in training a feature extractor using a large and diverse dataset to be applied to the considered few-shot task. Thanks to the encoded priors in the feature extractors, classification tasks with as little as one example (or "shot'') for each class can be solved with high accuracy, even when the shots display individual features not representative of their classes. Yet, the problem becomes more complicated when some of the given shots display multiple objects. In this paper, we present a strategy which aims at detecting the presence of multiple and previously unseen objects in a given shot. This methodology is based on identifying the corners of a simplex in a high dimensional space. We introduce an optimization routine and showcase its ability to successfully detect multiple (previously unseen) objects in raw images. Then, we introduce a downstream classifier meant to exploit the presence of multiple objects to improve the performance of few-shot classification, in the case of extreme settings where only one shot is given for its class. Using standard benchmarks of the field, we show the ability of the proposed method to slightly, yet statistically significantly, improve accuracy in these settings.
Spatial Graph Signal Interpolation with an Application for Merging BCI Datasets with Various Dimensionalities
Oct 28, 2022BCI Motor Imagery datasets usually are small and have different electrodes setups. When training a Deep Neural Network, one may want to capitalize on all these datasets to increase the amount of data available and hence obtain good generalization results. To this end, we introduce a spatial graph signal interpolation technique, that allows to interpolate efficiently multiple electrodes. We conduct a set of experiments with five BCI Motor Imagery datasets comparing the proposed interpolation with spherical splines interpolation. We believe that this work provides novel ideas on how to leverage graphs to interpolate electrodes and on how to homogenize multiple datasets.
Pruning Graph Convolutional Networks to select meaningful graph frequencies for fMRI decoding
Mar 09, 2022
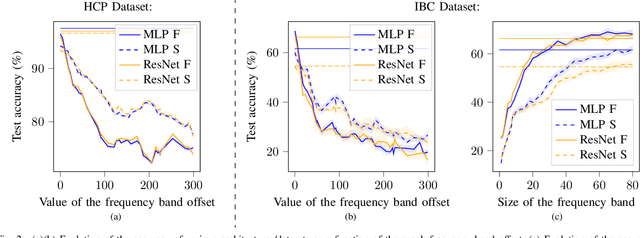
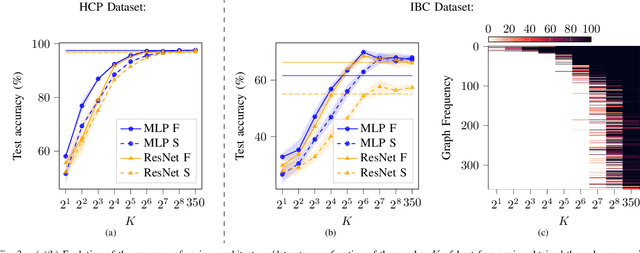
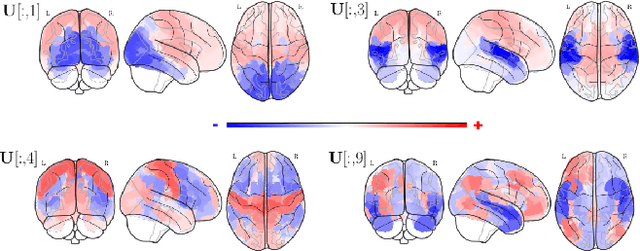
Graph Signal Processing is a promising framework to manipulate brain signals as it allows to encompass the spatial dependencies between the activity in regions of interest in the brain. In this work, we are interested in better understanding what are the graph frequencies that are the most useful to decode fMRI signals. To this end, we introduce a deep learning architecture and adapt a pruning methodology to automatically identify such frequencies. We experiment with various datasets, architectures and graphs, and show that low graph frequencies are consistently identified as the most important for fMRI decoding, with a stronger contribution for the functional graph over the structural one. We believe that this work provides novel insights on how graph-based methods can be deployed to increase fMRI decoding accuracy and interpretability.
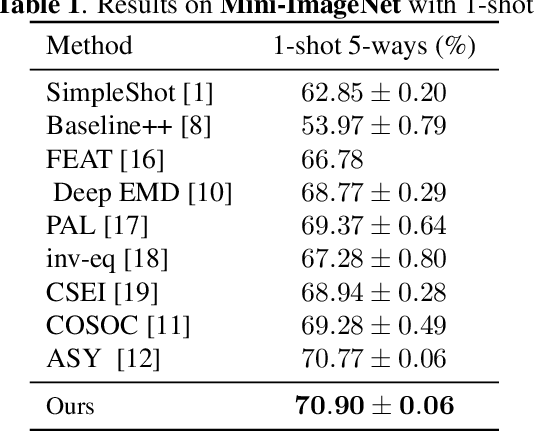
EASY: Ensemble Augmented-Shot Y-shaped Learning: State-Of-The-Art Few-Shot Classification with Simple Ingredients
Feb 07, 2022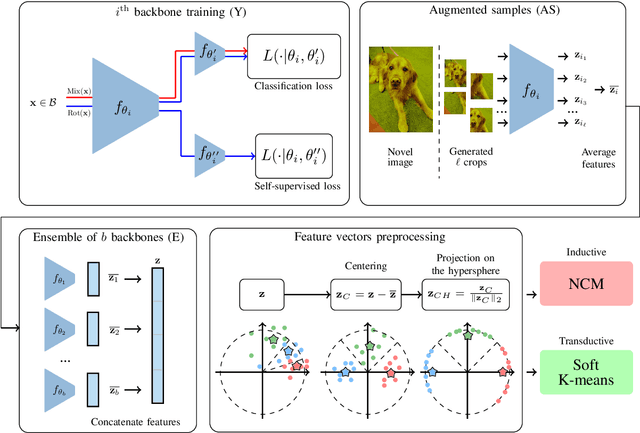
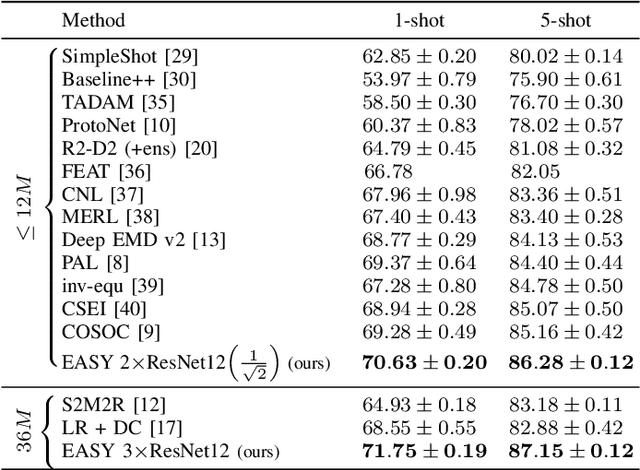
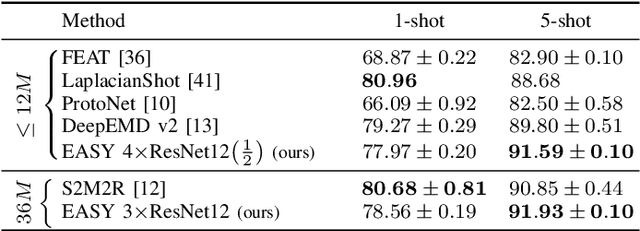

Few-shot learning aims at leveraging knowledge learned by one or more deep learning models, in order to obtain good classification performance on new problems, where only a few labeled samples per class are available. Recent years have seen a fair number of works in the field, introducing methods with numerous ingredients. A frequent problem, though, is the use of suboptimally trained models to extract knowledge, leading to interrogations on whether proposed approaches bring gains compared to using better initial models without the introduced ingredients. In this work, we propose a simple methodology, that reaches or even beats state of the art performance on multiple standardized benchmarks of the field, while adding almost no hyperparameters or parameters to those used for training the initial deep learning models on the generic dataset. This methodology offers a new baseline on which to propose (and fairly compare) new techniques or adapt existing ones.