 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOops, I Sampled it Again: Reinterpreting Confidence Intervals in Few-Shot Learning
Sep 04, 2024



The predominant method for computing confidence intervals (CI) in few-shot learning (FSL) is based on sampling the tasks with replacement, i.e.\ allowing the same samples to appear in multiple tasks. This makes the CI misleading in that it takes into account the randomness of the sampler but not the data itself. To quantify the extent of this problem, we conduct a comparative analysis between CIs computed with and without replacement. These reveal a notable underestimation by the predominant method. This observation calls for a reevaluation of how we interpret confidence intervals and the resulting conclusions in FSL comparative studies. Our research demonstrates that the use of paired tests can partially address this issue. Additionally, we explore methods to further reduce the (size of the) CI by strategically sampling tasks of a specific size. We also introduce a new optimized benchmark, which can be accessed at https://github.com/RafLaf/FSL-benchmark-again
Few and Fewer: Learning Better from Few Examples Using Fewer Base Classes
Jan 29, 2024When training data is scarce, it is common to make use of a feature extractor that has been pre-trained on a large base dataset, either by fine-tuning its parameters on the ``target'' dataset or by directly adopting its representation as features for a simple classifier. Fine-tuning is ineffective for few-shot learning, since the target dataset contains only a handful of examples. However, directly adopting the features without fine-tuning relies on the base and target distributions being similar enough that these features achieve separability and generalization. This paper investigates whether better features for the target dataset can be obtained by training on fewer base classes, seeking to identify a more useful base dataset for a given task.We consider cross-domain few-shot image classification in eight different domains from Meta-Dataset and entertain multiple real-world settings (domain-informed, task-informed and uninformed) where progressively less detail is known about the target task. To our knowledge, this is the first demonstration that fine-tuning on a subset of carefully selected base classes can significantly improve few-shot learning. Our contributions are simple and intuitive methods that can be implemented in any few-shot solution. We also give insights into the conditions in which these solutions are likely to provide a boost in accuracy. We release the code to reproduce all experiments from this paper on GitHub. https://github.com/RafLaf/Few-and-Fewer.git
EASY: Ensemble Augmented-Shot Y-shaped Learning: State-Of-The-Art Few-Shot Classification with Simple Ingredients
Feb 07, 2022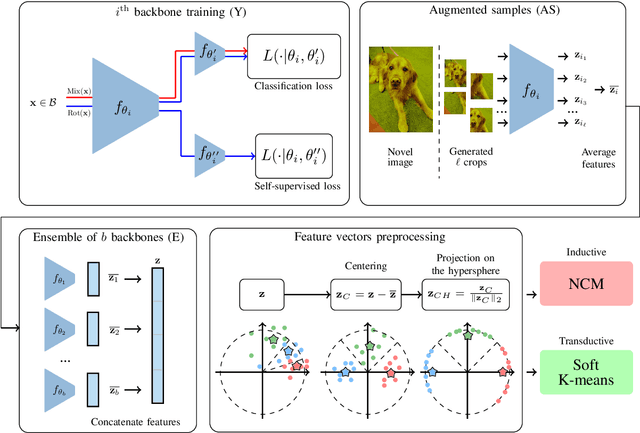
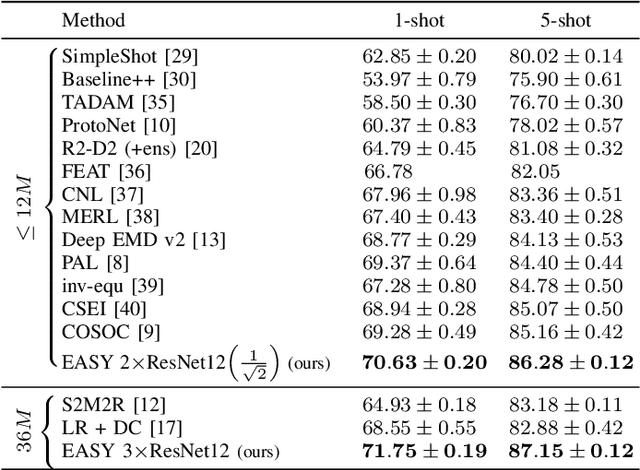
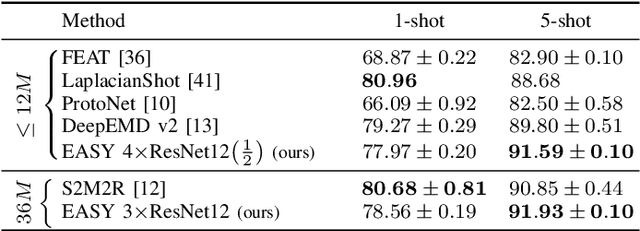

Few-shot learning aims at leveraging knowledge learned by one or more deep learning models, in order to obtain good classification performance on new problems, where only a few labeled samples per class are available. Recent years have seen a fair number of works in the field, introducing methods with numerous ingredients. A frequent problem, though, is the use of suboptimally trained models to extract knowledge, leading to interrogations on whether proposed approaches bring gains compared to using better initial models without the introduced ingredients. In this work, we propose a simple methodology, that reaches or even beats state of the art performance on multiple standardized benchmarks of the field, while adding almost no hyperparameters or parameters to those used for training the initial deep learning models on the generic dataset. This methodology offers a new baseline on which to propose (and fairly compare) new techniques or adapt existing ones.