 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOops, I Sampled it Again: Reinterpreting Confidence Intervals in Few-Shot Learning
Sep 04, 2024



The predominant method for computing confidence intervals (CI) in few-shot learning (FSL) is based on sampling the tasks with replacement, i.e.\ allowing the same samples to appear in multiple tasks. This makes the CI misleading in that it takes into account the randomness of the sampler but not the data itself. To quantify the extent of this problem, we conduct a comparative analysis between CIs computed with and without replacement. These reveal a notable underestimation by the predominant method. This observation calls for a reevaluation of how we interpret confidence intervals and the resulting conclusions in FSL comparative studies. Our research demonstrates that the use of paired tests can partially address this issue. Additionally, we explore methods to further reduce the (size of the) CI by strategically sampling tasks of a specific size. We also introduce a new optimized benchmark, which can be accessed at https://github.com/RafLaf/FSL-benchmark-again
An accurate detection is not all you need to combat label noise in web-noisy datasets
Jul 08, 2024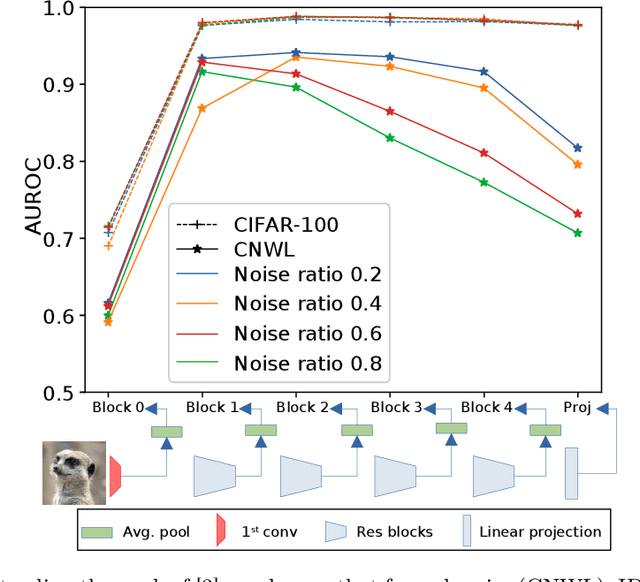
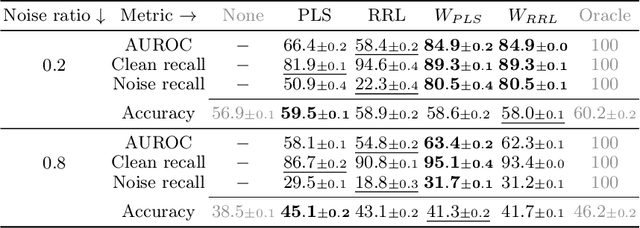

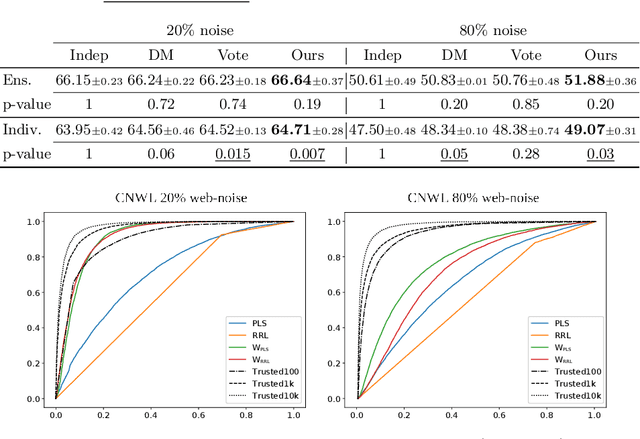
Training a classifier on web-crawled data demands learning algorithms that are robust to annotation errors and irrelevant examples. This paper builds upon the recent empirical observation that applying unsupervised contrastive learning to noisy, web-crawled datasets yields a feature representation under which the in-distribution (ID) and out-of-distribution (OOD) samples are linearly separable. We show that direct estimation of the separating hyperplane can indeed offer an accurate detection of OOD samples, and yet, surprisingly, this detection does not translate into gains in classification accuracy. Digging deeper into this phenomenon, we discover that the near-perfect detection misses a type of clean examples that are valuable for supervised learning. These examples often represent visually simple images, which are relatively easy to identify as clean examples using standard loss- or distance-based methods despite being poorly separated from the OOD distribution using unsupervised learning. Because we further observe a low correlation with SOTA metrics, this urges us to propose a hybrid solution that alternates between noise detection using linear separation and a state-of-the-art (SOTA) small-loss approach. When combined with the SOTA algorithm PLS, we substantially improve SOTA results for real-world image classification in the presence of web noise github.com/PaulAlbert31/LSA
Few and Fewer: Learning Better from Few Examples Using Fewer Base Classes
Jan 29, 2024When training data is scarce, it is common to make use of a feature extractor that has been pre-trained on a large base dataset, either by fine-tuning its parameters on the ``target'' dataset or by directly adopting its representation as features for a simple classifier. Fine-tuning is ineffective for few-shot learning, since the target dataset contains only a handful of examples. However, directly adopting the features without fine-tuning relies on the base and target distributions being similar enough that these features achieve separability and generalization. This paper investigates whether better features for the target dataset can be obtained by training on fewer base classes, seeking to identify a more useful base dataset for a given task.We consider cross-domain few-shot image classification in eight different domains from Meta-Dataset and entertain multiple real-world settings (domain-informed, task-informed and uninformed) where progressively less detail is known about the target task. To our knowledge, this is the first demonstration that fine-tuning on a subset of carefully selected base classes can significantly improve few-shot learning. Our contributions are simple and intuitive methods that can be implemented in any few-shot solution. We also give insights into the conditions in which these solutions are likely to provide a boost in accuracy. We release the code to reproduce all experiments from this paper on GitHub. https://github.com/RafLaf/Few-and-Fewer.git
On progressive sharpening, flat minima and generalisation
May 24, 2023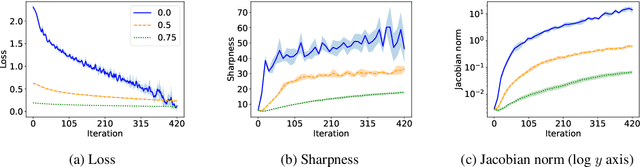

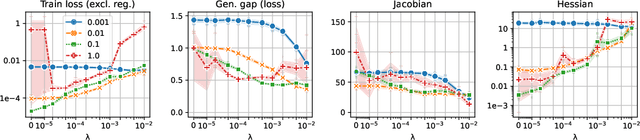
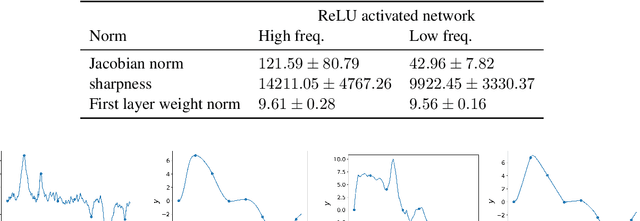
We present a new approach to understanding the relationship between loss curvature and generalisation in deep learning. Specifically, we use existing empirical analyses of the spectrum of deep network loss Hessians to ground an ansatz tying together the loss Hessian and the input-output Jacobian of a deep neural network. We then prove a series of theoretical results which quantify the degree to which the input-output Jacobian of a model approximates its Lipschitz norm over a data distribution, and deduce a novel generalisation bound in terms of the empirical Jacobian. We use our ansatz, together with our theoretical results, to give a new account of the recently observed progressive sharpening phenomenon, as well as the generalisation properties of flat minima. Experimental evidence is provided to validate our claims.
A global analysis of global optimisation
Oct 10, 2022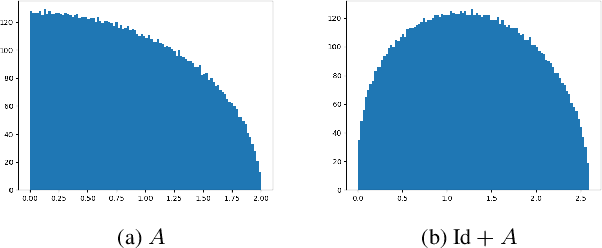
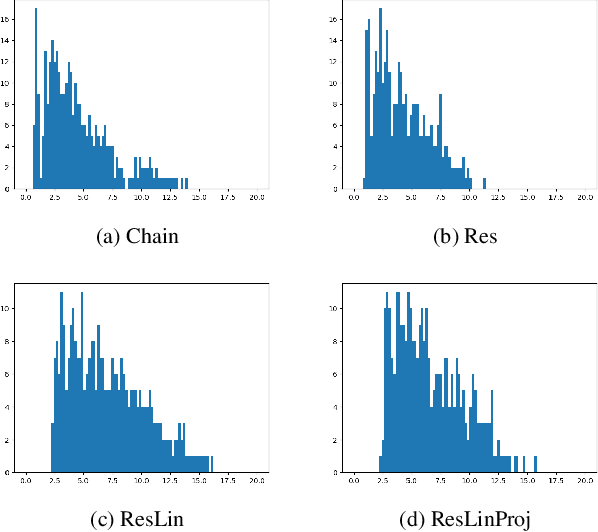
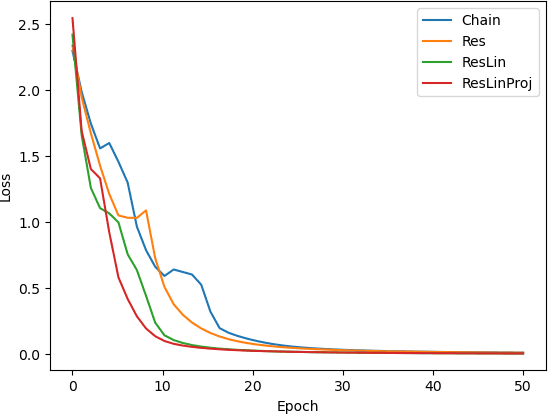
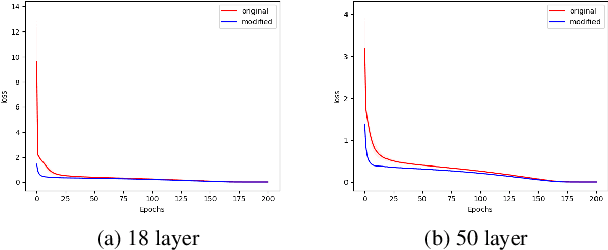
Theoretical understanding of the training of deep neural networks has made great strides in recent years. In particular, it has been shown that sufficient width and sufficiently small learning rate suffice to guarantee that chain networks trained with the square cost converge to global minima close to initialisation. However, this theory cannot apply to the cross-entropy cost, whose global minima exit only at infinity. In this paper, we introduce a general theoretical framework, designed for the study of optimisation, that encompasses ubiquitous architectural choices including batch normalisation, weight normalisation and skip connections. We use our framework to conduct a global analysis of the curvature and regularity properties of neural network loss landscapes, and give two applications. First, we give the first proof that a class of deep neural networks can be trained using gradient descent to global optima even when such optima only exist at infinity. Second, we use the theory in an empirical analysis of the effect of residual connections on training speed, which we verify with ResNets on MNIST, CIFAR10 and CIFAR100.
Learning with Neighbor Consistency for Noisy Labels
Feb 04, 2022



Recent advances in deep learning have relied on large, labelled datasets to train high-capacity models. However, collecting large datasets in a time- and cost-efficient manner often results in label noise. We present a method for learning from noisy labels that leverages similarities between training examples in feature space, encouraging the prediction of each example to be similar to its nearest neighbours. Compared to training algorithms that use multiple models or distinct stages, our approach takes the form of a simple, additional regularization term. It can be interpreted as an inductive version of the classical, transductive label propagation algorithm. We thoroughly evaluate our method on datasets evaluating both synthetic (CIFAR-10, CIFAR-100) and realistic (mini-WebVision, Clothing1M, mini-ImageNet-Red) noise, and achieve competitive or state-of-the-art accuracies across all of them.
Local Metrics for Multi-Object Tracking
Apr 06, 2021

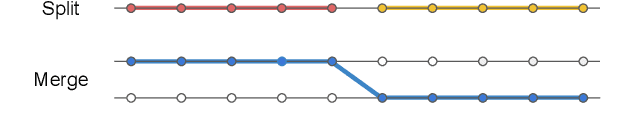

This paper introduces temporally local metrics for Multi-Object Tracking. These metrics are obtained by restricting existing metrics based on track matching to a finite temporal horizon, and provide new insight into the ability of trackers to maintain identity over time. Moreover, the horizon parameter offers a novel, meaningful mechanism by which to define the relative importance of detection and association, a common dilemma in applications where imperfect association is tolerable. It is shown that the historical Average Tracking Accuracy (ATA) metric exhibits superior sensitivity to association, enabling its proposed local variant, ALTA, to capture a wide range of characteristics. In particular, ALTA is better equipped to identify advances in association independent of detection. The paper further presents an error decomposition for ATA that reveals the impact of four distinct error types and is equally applicable to ALTA. The diagnostic capabilities of ALTA are demonstrated on the MOT 2017 and Waymo Open Dataset benchmarks.
Long-term Tracking in the Wild: A Benchmark
Aug 10, 2018
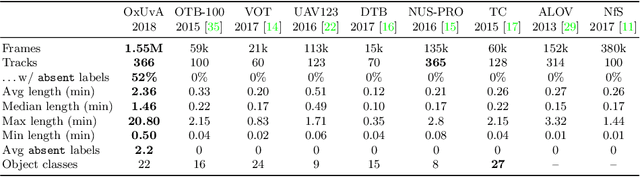
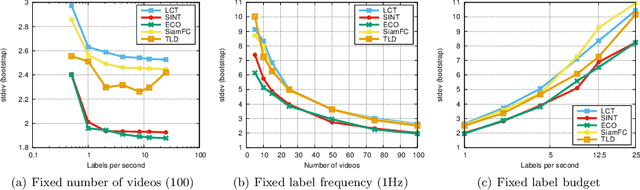
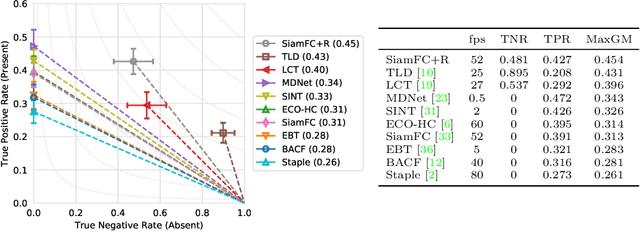
We introduce the OxUvA dataset and benchmark for evaluating single-object tracking algorithms. Benchmarks have enabled great strides in the field of object tracking by defining standardized evaluations on large sets of diverse videos. However, these works have focused exclusively on sequences that are just tens of seconds in length and in which the target is always visible. Consequently, most researchers have designed methods tailored to this "short-term" scenario, which is poorly representative of practitioners' needs. Aiming to address this disparity, we compile a long-term, large-scale tracking dataset of sequences with average length greater than two minutes and with frequent target object disappearance. The OxUvA dataset is much larger than the object tracking datasets of recent years: it comprises 366 sequences spanning 14 hours of video. We assess the performance of several algorithms, considering both the ability to locate the target and to determine whether it is present or absent. Our goal is to offer the community a large and diverse benchmark to enable the design and evaluation of tracking methods ready to be used "in the wild". The project website is http://oxuva.net
Devon: Deformable Volume Network for Learning Optical Flow
Feb 20, 2018
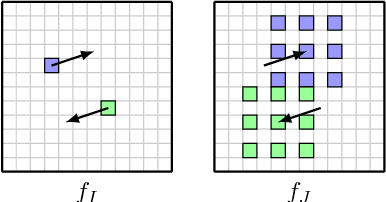
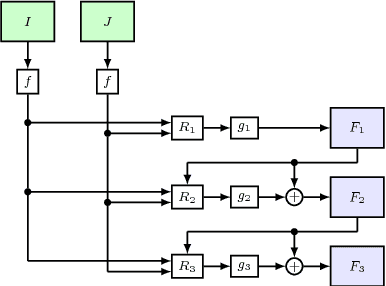
We propose a lightweight neural network model, Deformable Volume Network (Devon) for learning optical flow. Devon benefits from a multi-stage framework to iteratively refine its prediction. Each stage is by itself a neural network with an identical architecture. The optical flow between two stages is propagated with a newly proposed module, the deformable cost volume. The deformable cost volume does not distort the original images or their feature maps and therefore avoids the artifacts associated with warping, a common drawback in previous models. Devon only has one million parameters. Experiments show that Devon achieves comparable results to previous neural network models, despite of its small size.
End-to-end representation learning for Correlation Filter based tracking
Apr 20, 2017


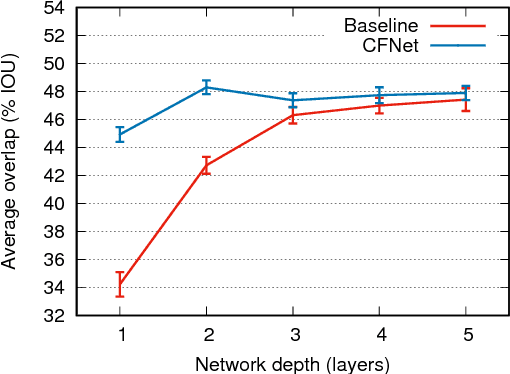
The Correlation Filter is an algorithm that trains a linear template to discriminate between images and their translations. It is well suited to object tracking because its formulation in the Fourier domain provides a fast solution, enabling the detector to be re-trained once per frame. Previous works that use the Correlation Filter, however, have adopted features that were either manually designed or trained for a different task. This work is the first to overcome this limitation by interpreting the Correlation Filter learner, which has a closed-form solution, as a differentiable layer in a deep neural network. This enables learning deep features that are tightly coupled to the Correlation Filter. Experiments illustrate that our method has the important practical benefit of allowing lightweight architectures to achieve state-of-the-art performance at high framerates.