 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Higher Effective Rank in Parameter-efficient Fine-tuning using Khatri--Rao Product
Aug 01, 2025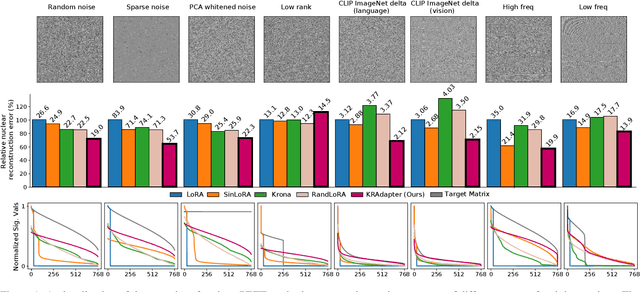
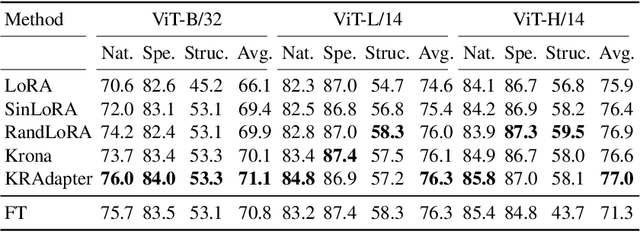
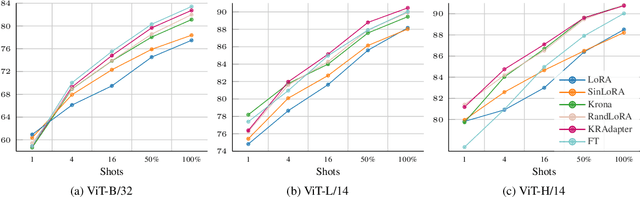
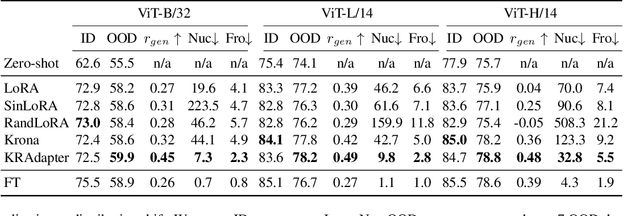
Parameter-efficient fine-tuning (PEFT) has become a standard approach for adapting large pre-trained models. Amongst PEFT methods, low-rank adaptation (LoRA) has achieved notable success. However, recent studies have highlighted its limitations compared against full-rank alternatives, particularly when applied to multimodal and large language models. In this work, we present a quantitative comparison amongst full-rank and low-rank PEFT methods using a synthetic matrix approximation benchmark with controlled spectral properties. Our results confirm that LoRA struggles to approximate matrices with relatively flat spectrums or high frequency components -- signs of high effective ranks. To this end, we introduce KRAdapter, a novel PEFT algorithm that leverages the Khatri-Rao product to produce weight updates, which, by construction, tends to produce matrix product with a high effective rank. We demonstrate performance gains with KRAdapter on vision-language models up to 1B parameters and on large language models up to 8B parameters, particularly on unseen common-sense reasoning tasks. In addition, KRAdapter maintains the memory and compute efficiency of LoRA, making it a practical and robust alternative to fine-tune billion-scale parameter models.
Compressing Sine-Activated Low-Rank Adapters through Post-Training Quantization
May 28, 2025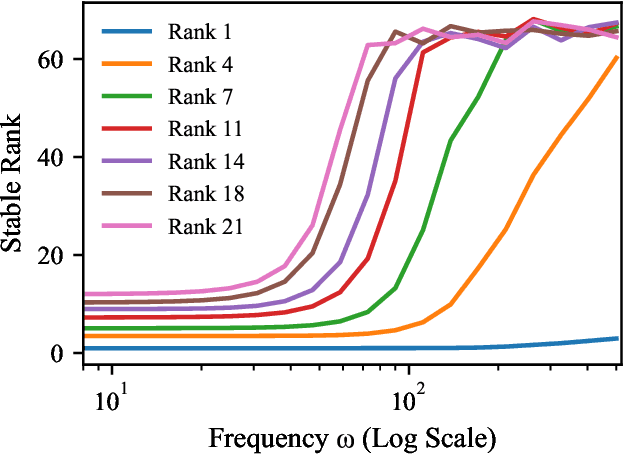
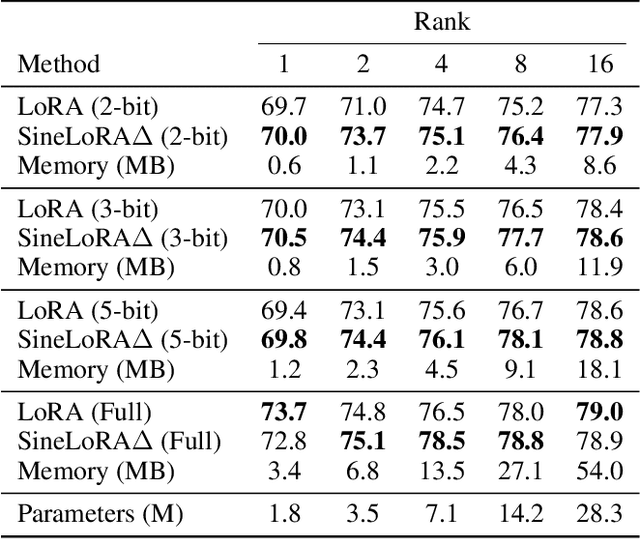
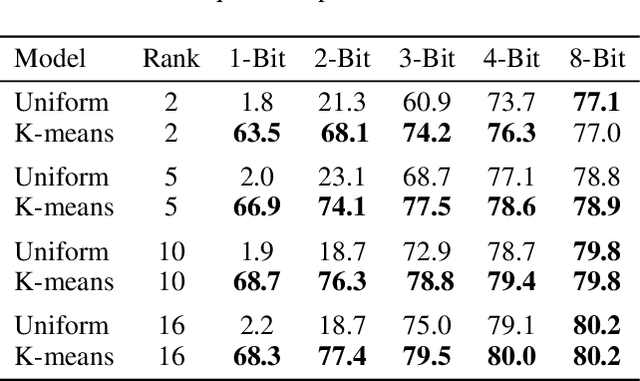

Low-Rank Adaptation (LoRA) has become a standard approach for parameter-efficient fine-tuning, offering substantial reductions in trainable parameters by modeling updates as the product of two low-rank matrices. While effective, the low-rank constraint inherently limits representational capacity, often resulting in reduced performance compared to full-rank fine-tuning. Recent work by Ji et al. (2025) has addressed this limitation by applying a fixed-frequency sinusoidal transformation to low-rank adapters, increasing their stable rank without introducing additional parameters. This raises a crucial question: can the same sine-activated technique be successfully applied within the context of Post-Training Quantization to retain benefits even after model compression? In this paper, we investigate this question by extending the sinusoidal transformation framework to quantized LoRA adapters. We develop a theoretical analysis showing that the stable rank of a quantized adapter is tightly linked to that of its full-precision counterpart, motivating the use of such rank-enhancing functions even under quantization. Our results demonstrate that the expressivity gains from a sinusoidal non-linearity persist after quantization, yielding highly compressed adapters with negligible loss in performance. We validate our approach across a range of fine-tuning tasks for language, vision and text-to-image generation achieving significant memory savings while maintaining competitive accuracy.
RandLoRA: Full-rank parameter-efficient fine-tuning of large models
Feb 03, 2025Low-Rank Adaptation (LoRA) and its variants have shown impressive results in reducing the number of trainable parameters and memory requirements of large transformer networks while maintaining fine-tuning performance. However, the low-rank nature of the weight update inherently limits the representation power of fine-tuned models, potentially compromising performance on complex tasks. This raises a critical question: when a performance gap between LoRA and standard fine-tuning is observed, is it due to the reduced number of trainable parameters or the rank deficiency? This paper aims to answer this question by introducing RandLoRA, a parameter-efficient method that performs full-rank updates using a learned linear combinations of low-rank, non-trainable random matrices. Our method limits the number of trainable parameters by restricting optimization to diagonal scaling matrices applied to the fixed random matrices. This allows us to effectively overcome the low-rank limitations while maintaining parameter and memory efficiency during training. Through extensive experimentation across vision, language, and vision-language benchmarks, we systematically evaluate the limitations of LoRA and existing random basis methods. Our findings reveal that full-rank updates are beneficial across vision and language tasks individually, and even more so for vision-language tasks, where RandLoRA significantly reduces -- and sometimes eliminates -- the performance gap between standard fine-tuning and LoRA, demonstrating its efficacy.
An accurate detection is not all you need to combat label noise in web-noisy datasets
Jul 08, 2024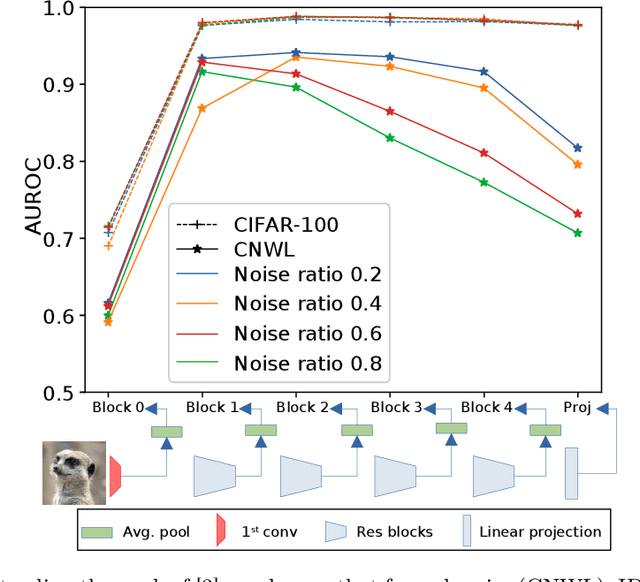
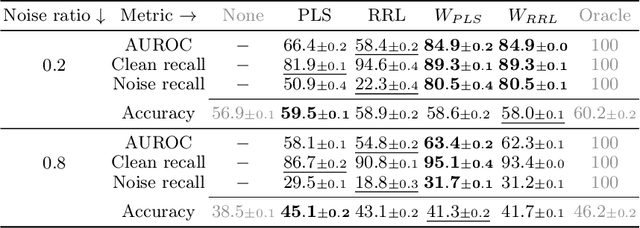

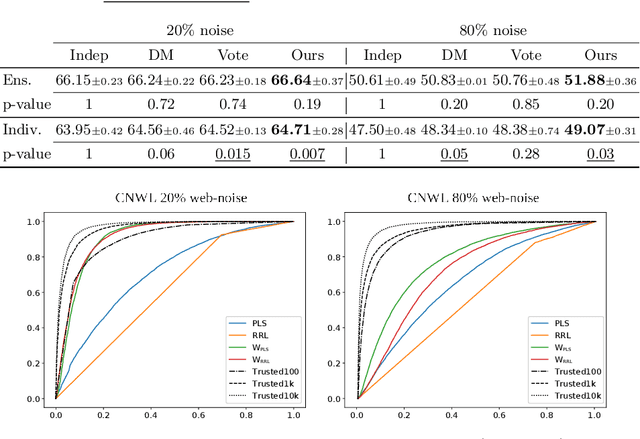
Training a classifier on web-crawled data demands learning algorithms that are robust to annotation errors and irrelevant examples. This paper builds upon the recent empirical observation that applying unsupervised contrastive learning to noisy, web-crawled datasets yields a feature representation under which the in-distribution (ID) and out-of-distribution (OOD) samples are linearly separable. We show that direct estimation of the separating hyperplane can indeed offer an accurate detection of OOD samples, and yet, surprisingly, this detection does not translate into gains in classification accuracy. Digging deeper into this phenomenon, we discover that the near-perfect detection misses a type of clean examples that are valuable for supervised learning. These examples often represent visually simple images, which are relatively easy to identify as clean examples using standard loss- or distance-based methods despite being poorly separated from the OOD distribution using unsupervised learning. Because we further observe a low correlation with SOTA metrics, this urges us to propose a hybrid solution that alternates between noise detection using linear separation and a state-of-the-art (SOTA) small-loss approach. When combined with the SOTA algorithm PLS, we substantially improve SOTA results for real-world image classification in the presence of web noise github.com/PaulAlbert31/LSA
Knowledge Composition using Task Vectors with Learned Anisotropic Scaling
Jul 03, 2024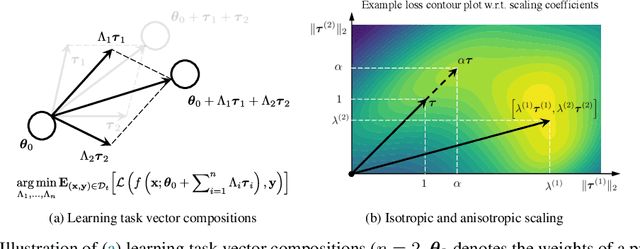
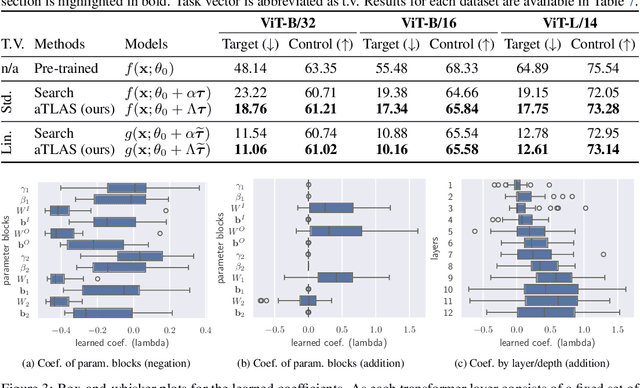
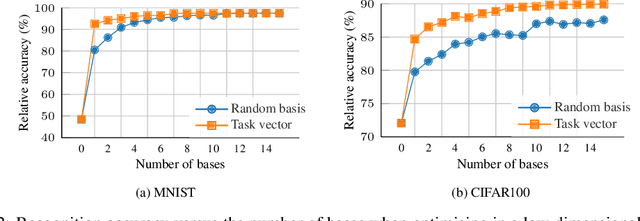
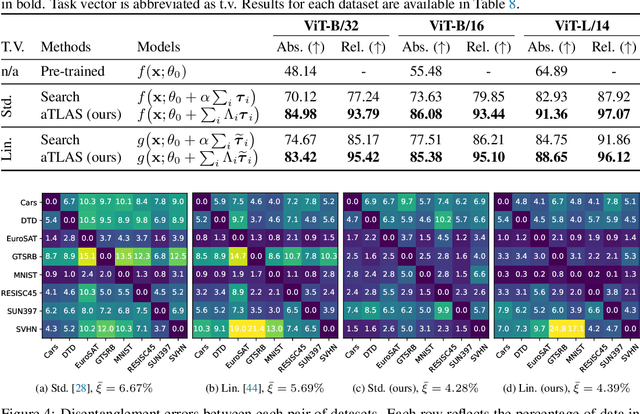
Pre-trained models produce strong generic representations that can be adapted via fine-tuning. The learned weight difference relative to the pre-trained model, known as a task vector, characterises the direction and stride of fine-tuning. The significance of task vectors is such that simple arithmetic operations on them can be used to combine diverse representations from different domains. This paper builds on these properties of task vectors and aims to answer (1) whether components of task vectors, particularly parameter blocks, exhibit similar characteristics, and (2) how such blocks can be used to enhance knowledge composition and transfer. To this end, we introduce aTLAS, an algorithm that linearly combines parameter blocks with different learned coefficients, resulting in anisotropic scaling at the task vector level. We show that such linear combinations explicitly exploit the low intrinsic dimensionality of pre-trained models, with only a few coefficients being the learnable parameters. Furthermore, composition of parameter blocks leverages the already learned representations, thereby reducing the dependency on large amounts of data. We demonstrate the effectiveness of our method in task arithmetic, few-shot recognition and test-time adaptation, with supervised or unsupervised objectives. In particular, we show that (1) learned anisotropic scaling allows task vectors to be more disentangled, causing less interference in composition; (2) task vector composition excels with scarce or no labeled data and is less prone to domain shift, thus leading to better generalisability; (3) mixing the most informative parameter blocks across different task vectors prior to training can reduce the memory footprint and improve the flexibility of knowledge transfer. Moreover, we show the potential of aTLAS as a PEFT method, particularly with less data, and demonstrate that its scalibility.
Energy-Efficient Uncertainty-Aware Biomass Composition Prediction at the Edge
Apr 17, 2024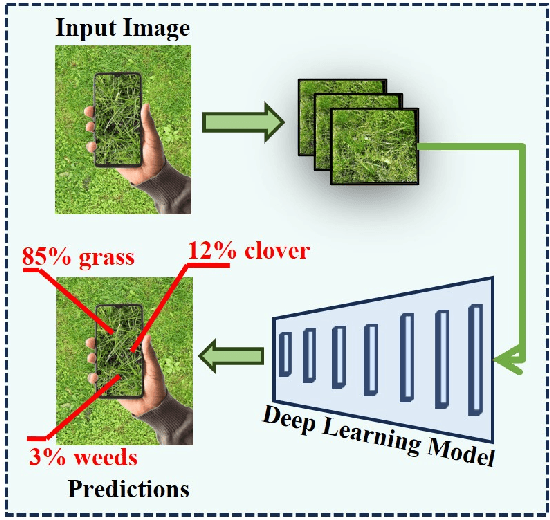

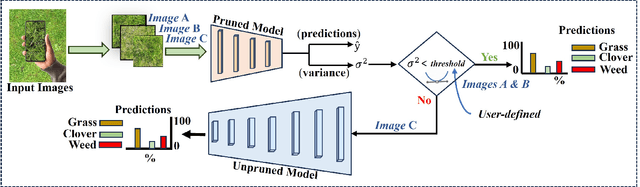

Clover fixates nitrogen from the atmosphere to the ground, making grass-clover mixtures highly desirable to reduce external nitrogen fertilization. Herbage containing clover additionally promotes higher food intake, resulting in higher milk production. Herbage probing however remains largely unused as it requires a time-intensive manual laboratory analysis. Without this information, farmers are unable to perform localized clover sowing or take targeted fertilization decisions. Deep learning algorithms have been proposed with the goal to estimate the dry biomass composition from images of the grass directly in the fields. The energy-intensive nature of deep learning however limits deployment to practical edge devices such as smartphones. This paper proposes to fill this gap by applying filter pruning to reduce the energy requirement of existing deep learning solutions. We report that although pruned networks are accurate on controlled, high-quality images of the grass, they struggle to generalize to real-world smartphone images that are blurry or taken from challenging angles. We address this challenge by training filter-pruned models using a variance attenuation loss so they can predict the uncertainty of their predictions. When the uncertainty exceeds a threshold, we re-infer using a more accurate unpruned model. This hybrid approach allows us to reduce energy consumption while retaining a high accuracy. We evaluate our algorithm on two datasets: the GrassClover and the Irish clover using an NVIDIA Jetson Nano edge device. We find that we reduce energy reduction with respect to state-of-the-art solutions by 50% on average with only 4% accuracy loss.
Is your noise correction noisy? PLS: Robustness to label noise with two stage detection
Oct 10, 2022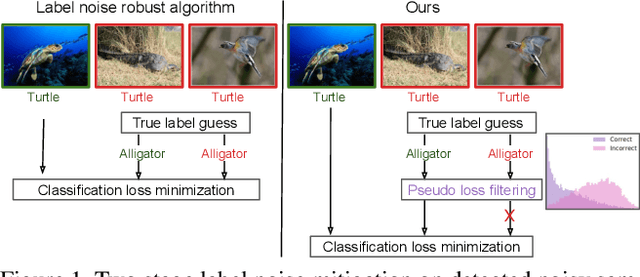

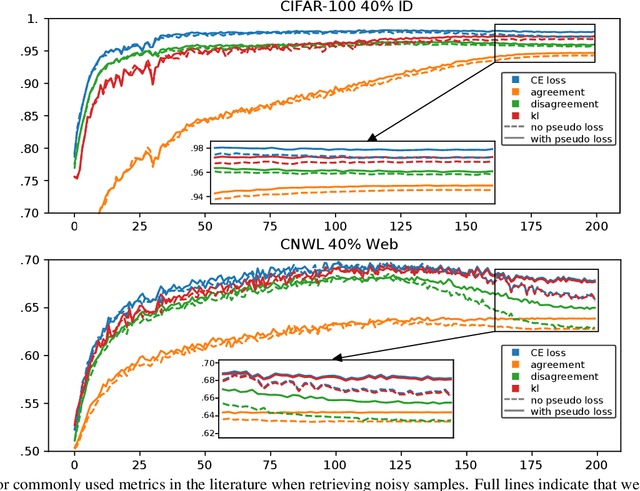
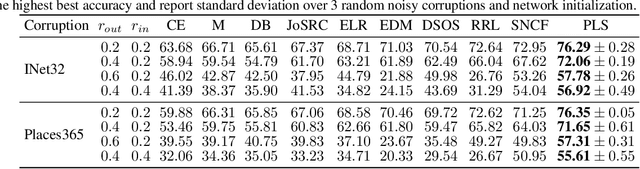
Designing robust algorithms capable of training accurate neural networks on uncurated datasets from the web has been the subject of much research as it reduces the need for time consuming human labor. The focus of many previous research contributions has been on the detection of different types of label noise; however, this paper proposes to improve the correction accuracy of noisy samples once they have been detected. In many state-of-the-art contributions, a two phase approach is adopted where the noisy samples are detected before guessing a corrected pseudo-label in a semi-supervised fashion. The guessed pseudo-labels are then used in the supervised objective without ensuring that the label guess is likely to be correct. This can lead to confirmation bias, which reduces the noise robustness. Here we propose the pseudo-loss, a simple metric that we find to be strongly correlated with pseudo-label correctness on noisy samples. Using the pseudo-loss, we dynamically down weight under-confident pseudo-labels throughout training to avoid confirmation bias and improve the network accuracy. We additionally propose to use a confidence guided contrastive objective that learns robust representation on an interpolated objective between class bound (supervised) for confidently corrected samples and unsupervised representation for under-confident label corrections. Experiments demonstrate the state-of-the-art performance of our Pseudo-Loss Selection (PLS) algorithm on a variety of benchmark datasets including curated data synthetically corrupted with in-distribution and out-of-distribution noise, and two real world web noise datasets. Our experiments are fully reproducible [github coming soon]
Embedding contrastive unsupervised features to cluster in- and out-of-distribution noise in corrupted image datasets
Jul 18, 2022
Using search engines for web image retrieval is a tempting alternative to manual curation when creating an image dataset, but their main drawback remains the proportion of incorrect (noisy) samples retrieved. These noisy samples have been evidenced by previous works to be a mixture of in-distribution (ID) samples, assigned to the incorrect category but presenting similar visual semantics to other classes in the dataset, and out-of-distribution (OOD) images, which share no semantic correlation with any category from the dataset. The latter are, in practice, the dominant type of noisy images retrieved. To tackle this noise duality, we propose a two stage algorithm starting with a detection step where we use unsupervised contrastive feature learning to represent images in a feature space. We find that the alignment and uniformity principles of contrastive learning allow OOD samples to be linearly separated from ID samples on the unit hypersphere. We then spectrally embed the unsupervised representations using a fixed neighborhood size and apply an outlier sensitive clustering at the class level to detect the clean and OOD clusters as well as ID noisy outliers. We finally train a noise robust neural network that corrects ID noise to the correct category and utilizes OOD samples in a guided contrastive objective, clustering them to improve low-level features. Our algorithm improves the state-of-the-art results on synthetic noise image datasets as well as real-world web-crawled data. Our work is fully reproducible github.com/PaulAlbert31/SNCF.
Utilizing unsupervised learning to improve sward content prediction and herbage mass estimation
Apr 20, 2022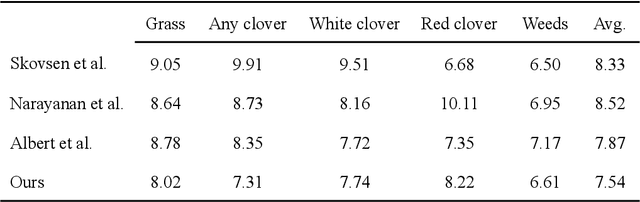
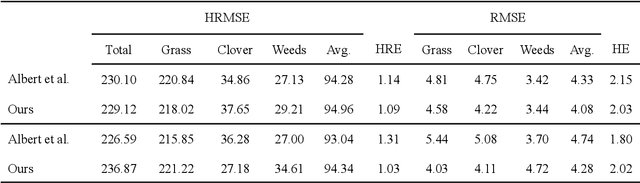
Sward species composition estimation is a tedious one. Herbage must be collected in the field, manually separated into components, dried and weighed to estimate species composition. Deep learning approaches using neural networks have been used in previous work to propose faster and more cost efficient alternatives to this process by estimating the biomass information from a picture of an area of pasture alone. Deep learning approaches have, however, struggled to generalize to distant geographical locations and necessitated further data collection to retrain and perform optimally in different climates. In this work, we enhance the deep learning solution by reducing the need for ground-truthed (GT) images when training the neural network. We demonstrate how unsupervised contrastive learning can be used in the sward composition prediction problem and compare with the state-of-the-art on the publicly available GrassClover dataset collected in Denmark as well as a more recent dataset from Ireland where we tackle herbage mass and height estimation.
Unsupervised domain adaptation and super resolution on drone images for autonomous dry herbage biomass estimation
Apr 18, 2022
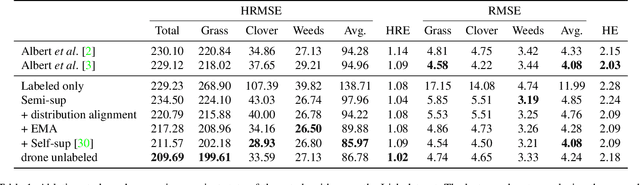


Herbage mass yield and composition estimation is an important tool for dairy farmers to ensure an adequate supply of high quality herbage for grazing and subsequently milk production. By accurately estimating herbage mass and composition, targeted nitrogen fertiliser application strategies can be deployed to improve localised regions in a herbage field, effectively reducing the negative impacts of over-fertilization on biodiversity and the environment. In this context, deep learning algorithms offer a tempting alternative to the usual means of sward composition estimation, which involves the destructive process of cutting a sample from the herbage field and sorting by hand all plant species in the herbage. The process is labour intensive and time consuming and so not utilised by farmers. Deep learning has been successfully applied in this context on images collected by high-resolution cameras on the ground. Moving the deep learning solution to drone imaging, however, has the potential to further improve the herbage mass yield and composition estimation task by extending the ground-level estimation to the large surfaces occupied by fields/paddocks. Drone images come at the cost of lower resolution views of the fields taken from a high altitude and requires further herbage ground-truth collection from the large surfaces covered by drone images. This paper proposes to transfer knowledge learned on ground-level images to raw drone images in an unsupervised manner. To do so, we use unpaired image style translation to enhance the resolution of drone images by a factor of eight and modify them to appear closer to their ground-level counterparts. We then ... ~\url{www.github.com/PaulAlbert31/Clover_SSL}.