 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs your noise correction noisy? PLS: Robustness to label noise with two stage detection
Paper and Code
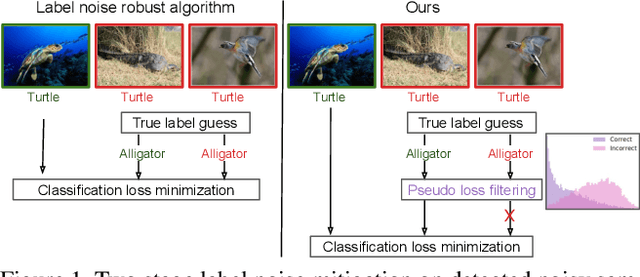

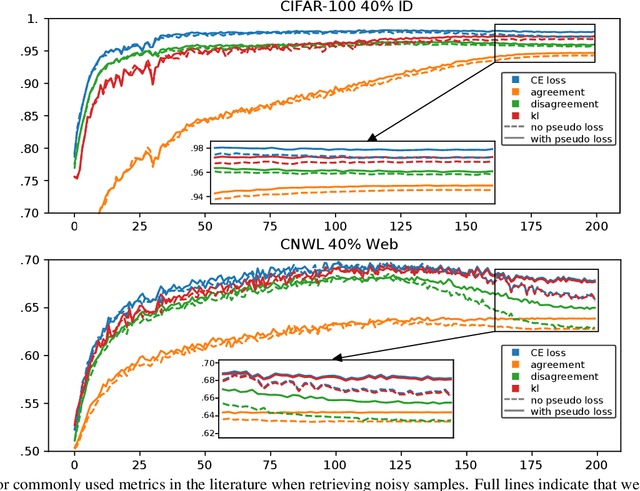
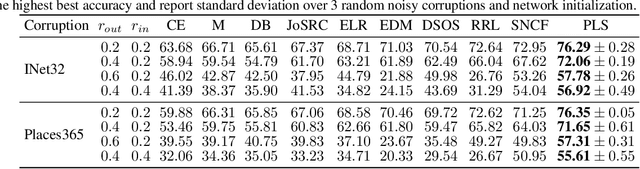
Designing robust algorithms capable of training accurate neural networks on uncurated datasets from the web has been the subject of much research as it reduces the need for time consuming human labor. The focus of many previous research contributions has been on the detection of different types of label noise; however, this paper proposes to improve the correction accuracy of noisy samples once they have been detected. In many state-of-the-art contributions, a two phase approach is adopted where the noisy samples are detected before guessing a corrected pseudo-label in a semi-supervised fashion. The guessed pseudo-labels are then used in the supervised objective without ensuring that the label guess is likely to be correct. This can lead to confirmation bias, which reduces the noise robustness. Here we propose the pseudo-loss, a simple metric that we find to be strongly correlated with pseudo-label correctness on noisy samples. Using the pseudo-loss, we dynamically down weight under-confident pseudo-labels throughout training to avoid confirmation bias and improve the network accuracy. We additionally propose to use a confidence guided contrastive objective that learns robust representation on an interpolated objective between class bound (supervised) for confidently corrected samples and unsupervised representation for under-confident label corrections. Experiments demonstrate the state-of-the-art performance of our Pseudo-Loss Selection (PLS) algorithm on a variety of benchmark datasets including curated data synthetically corrupted with in-distribution and out-of-distribution noise, and two real world web noise datasets. Our experiments are fully reproducible [github coming soon]