 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompressing Sine-Activated Low-Rank Adapters through Post-Training Quantization
May 28, 2025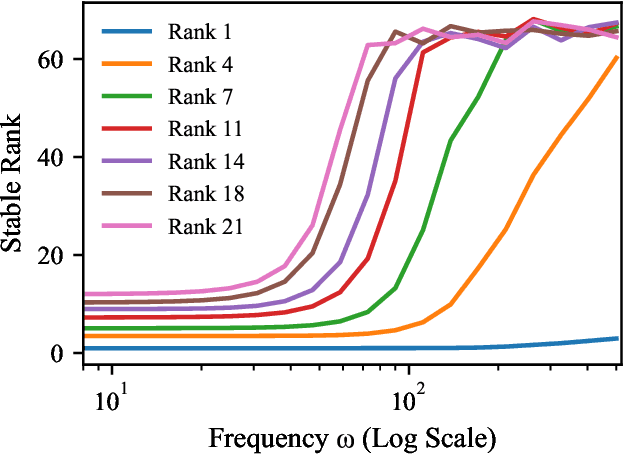
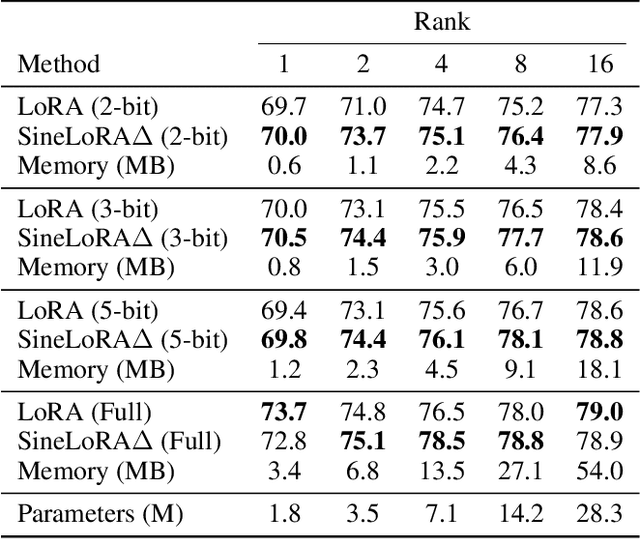
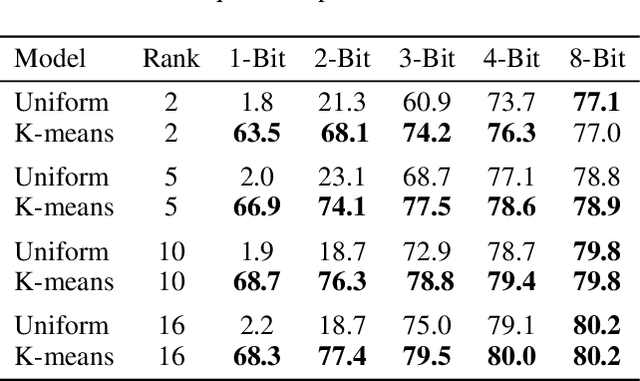

Low-Rank Adaptation (LoRA) has become a standard approach for parameter-efficient fine-tuning, offering substantial reductions in trainable parameters by modeling updates as the product of two low-rank matrices. While effective, the low-rank constraint inherently limits representational capacity, often resulting in reduced performance compared to full-rank fine-tuning. Recent work by Ji et al. (2025) has addressed this limitation by applying a fixed-frequency sinusoidal transformation to low-rank adapters, increasing their stable rank without introducing additional parameters. This raises a crucial question: can the same sine-activated technique be successfully applied within the context of Post-Training Quantization to retain benefits even after model compression? In this paper, we investigate this question by extending the sinusoidal transformation framework to quantized LoRA adapters. We develop a theoretical analysis showing that the stable rank of a quantized adapter is tightly linked to that of its full-precision counterpart, motivating the use of such rank-enhancing functions even under quantization. Our results demonstrate that the expressivity gains from a sinusoidal non-linearity persist after quantization, yielding highly compressed adapters with negligible loss in performance. We validate our approach across a range of fine-tuning tasks for language, vision and text-to-image generation achieving significant memory savings while maintaining competitive accuracy.
Sine Activated Low-Rank Matrices for Parameter Efficient Learning
Mar 28, 2024Low-rank decomposition has emerged as a vital tool for enhancing parameter efficiency in neural network architectures, gaining traction across diverse applications in machine learning. These techniques significantly lower the number of parameters, striking a balance between compactness and performance. However, a common challenge has been the compromise between parameter efficiency and the accuracy of the model, where reduced parameters often lead to diminished accuracy compared to their full-rank counterparts. In this work, we propose a novel theoretical framework that integrates a sinusoidal function within the low-rank decomposition process. This approach not only preserves the benefits of the parameter efficiency characteristic of low-rank methods but also increases the decomposition's rank, thereby enhancing model accuracy. Our method proves to be an adaptable enhancement for existing low-rank models, as evidenced by its successful application in Vision Transformers (ViT), Large Language Models (LLMs), Neural Radiance Fields (NeRF), and 3D shape modeling. This demonstrates the wide-ranging potential and efficiency of our proposed technique.
D'OH: Decoder-Only random Hypernetworks for Implicit Neural Representations
Mar 28, 2024Deep implicit functions have been found to be an effective tool for efficiently encoding all manner of natural signals. Their attractiveness stems from their ability to compactly represent signals with little to no off-line training data. Instead, they leverage the implicit bias of deep networks to decouple hidden redundancies within the signal. In this paper, we explore the hypothesis that additional compression can be achieved by leveraging the redundancies that exist between layers. We propose to use a novel run-time decoder-only hypernetwork - that uses no offline training data - to better model this cross-layer parameter redundancy. Previous applications of hyper-networks with deep implicit functions have applied feed-forward encoder/decoder frameworks that rely on large offline datasets that do not generalize beyond the signals they were trained on. We instead present a strategy for the initialization of run-time deep implicit functions for single-instance signals through a Decoder-Only randomly projected Hypernetwork (D'OH). By directly changing the dimension of a latent code to approximate a target implicit neural architecture, we provide a natural way to vary the memory footprint of neural representations without the costly need for neural architecture search on a space of alternative low-rate structures.