 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompressing Sine-Activated Low-Rank Adapters through Post-Training Quantization
May 28, 2025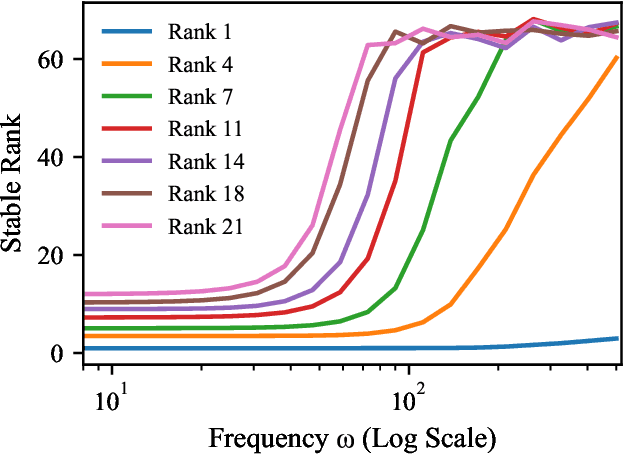
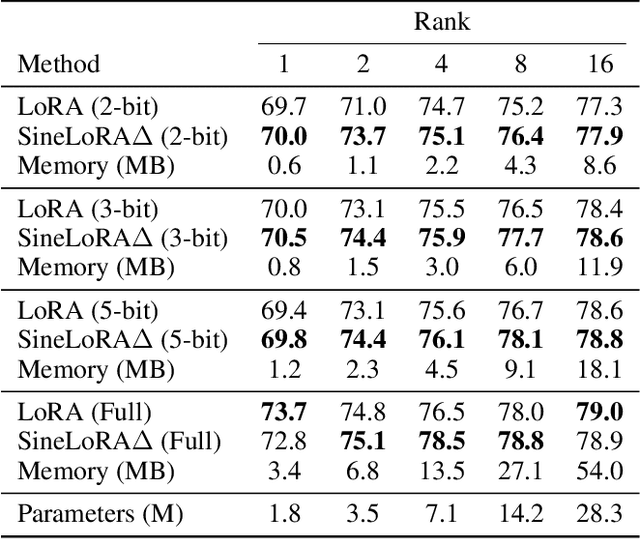
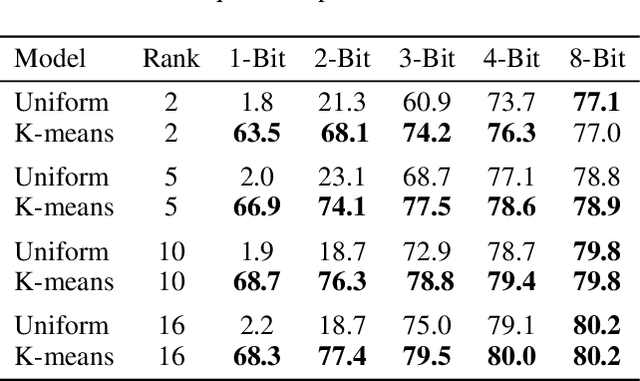

Low-Rank Adaptation (LoRA) has become a standard approach for parameter-efficient fine-tuning, offering substantial reductions in trainable parameters by modeling updates as the product of two low-rank matrices. While effective, the low-rank constraint inherently limits representational capacity, often resulting in reduced performance compared to full-rank fine-tuning. Recent work by Ji et al. (2025) has addressed this limitation by applying a fixed-frequency sinusoidal transformation to low-rank adapters, increasing their stable rank without introducing additional parameters. This raises a crucial question: can the same sine-activated technique be successfully applied within the context of Post-Training Quantization to retain benefits even after model compression? In this paper, we investigate this question by extending the sinusoidal transformation framework to quantized LoRA adapters. We develop a theoretical analysis showing that the stable rank of a quantized adapter is tightly linked to that of its full-precision counterpart, motivating the use of such rank-enhancing functions even under quantization. Our results demonstrate that the expressivity gains from a sinusoidal non-linearity persist after quantization, yielding highly compressed adapters with negligible loss in performance. We validate our approach across a range of fine-tuning tasks for language, vision and text-to-image generation achieving significant memory savings while maintaining competitive accuracy.
Always Skip Attention
May 04, 2025We highlight a curious empirical result within modern Vision Transformers (ViTs). Specifically, self-attention catastrophically fails to train unless it is used in conjunction with a skip connection. This is in contrast to other elements of a ViT that continue to exhibit good performance (albeit suboptimal) when skip connections are removed. Further, we show that this critical dependence on skip connections is a relatively new phenomenon, with previous deep architectures (\eg, CNNs) exhibiting good performance in their absence. In this paper, we theoretically characterize that the self-attention mechanism is fundamentally ill-conditioned and is, therefore, uniquely dependent on skip connections for regularization. Additionally, we propose Token Graying -- a simple yet effective complement (to skip connections) that further improves the condition of input tokens. We validate our approach in both supervised and self-supervised training methods.
Rethinking Softmax: Self-Attention with Polynomial Activations
Oct 24, 2024This paper challenges the conventional belief that softmax attention in transformers is effective primarily because it generates a probability distribution for attention allocation. Instead, we theoretically show that its success lies in its ability to implicitly regularize the Frobenius norm of the attention matrix during training. We then explore alternative activations that regularize the Frobenius norm of the attention matrix, demonstrating that certain polynomial activations can achieve this effect, making them suitable for attention-based architectures. Empirical results indicate these activations perform comparably or better than softmax across various computer vision and language tasks, suggesting new possibilities for attention mechanisms beyond softmax.
Sine Activated Low-Rank Matrices for Parameter Efficient Learning
Mar 28, 2024Low-rank decomposition has emerged as a vital tool for enhancing parameter efficiency in neural network architectures, gaining traction across diverse applications in machine learning. These techniques significantly lower the number of parameters, striking a balance between compactness and performance. However, a common challenge has been the compromise between parameter efficiency and the accuracy of the model, where reduced parameters often lead to diminished accuracy compared to their full-rank counterparts. In this work, we propose a novel theoretical framework that integrates a sinusoidal function within the low-rank decomposition process. This approach not only preserves the benefits of the parameter efficiency characteristic of low-rank methods but also increases the decomposition's rank, thereby enhancing model accuracy. Our method proves to be an adaptable enhancement for existing low-rank models, as evidenced by its successful application in Vision Transformers (ViT), Large Language Models (LLMs), Neural Radiance Fields (NeRF), and 3D shape modeling. This demonstrates the wide-ranging potential and efficiency of our proposed technique.