 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Inlet Rank Collapse in Implicit Neural Representations: Diagnosis and Unified Remedy
Feb 02, 2026Implicit Neural Representations (INRs) have revolutionized continuous signal modeling, yet they struggle to recover fine-grained details within finite training budgets. While empirical techniques, such as positional encoding (PE), sinusoidal activations (SIREN), and batch normalization (BN), effectively mitigate this, their theoretical justifications are predominantly post hoc, focusing on the global NTK spectrum only after modifications are applied. In this work, we reverse this paradigm by introducing a structural diagnostic framework. By performing a layer-wise decomposition of the NTK, we mathematically identify the ``Inlet Rank Collapse'': a phenomenon where the low-dimensional input coordinates fail to span the high-dimensional embedding space, creating a fundamental rank deficiency at the first layer that acts as an expressive bottleneck for the entire network. This framework provides a unified perspective to re-interpret PE, SIREN, and BN as different forms of rank restoration. Guided by this diagnosis, we derive a Rank-Expanding Initialization, a minimalist remedy that ensures the representation rank scales with the layer width without architectural modifications or computational overhead. Our results demonstrate that this principled remedy enables standard MLPs to achieve high-fidelity reconstructions, proving that the key to empowering INRs lies in the structural optimization of the initial rank propagation to effectively populate the latent space.
Structured Initialization for Vision Transformers
May 26, 2025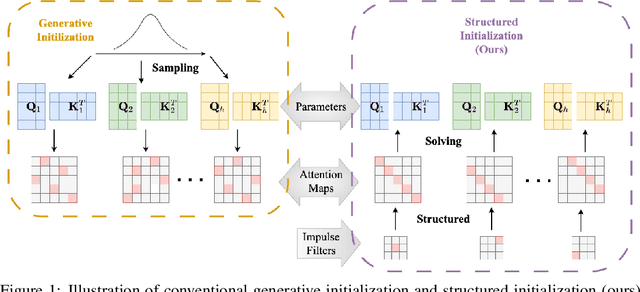

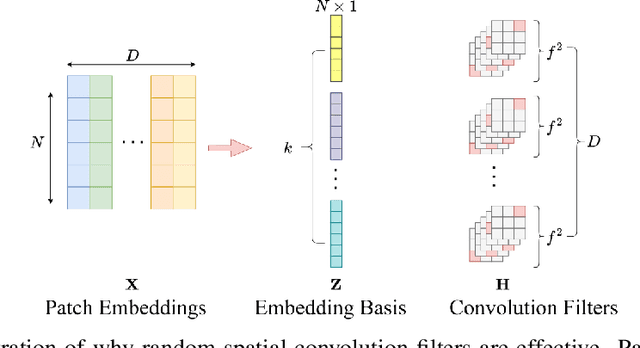

Convolutional Neural Networks (CNNs) inherently encode strong inductive biases, enabling effective generalization on small-scale datasets. In this paper, we propose integrating this inductive bias into ViTs, not through an architectural intervention but solely through initialization. The motivation here is to have a ViT that can enjoy strong CNN-like performance when data assets are small, but can still scale to ViT-like performance as the data expands. Our approach is motivated by our empirical results that random impulse filters can achieve commensurate performance to learned filters within a CNN. We improve upon current ViT initialization strategies, which typically rely on empirical heuristics such as using attention weights from pretrained models or focusing on the distribution of attention weights without enforcing structures. Empirical results demonstrate that our method significantly outperforms standard ViT initialization across numerous small and medium-scale benchmarks, including Food-101, CIFAR-10, CIFAR-100, STL-10, Flowers, and Pets, while maintaining comparative performance on large-scale datasets such as ImageNet-1K. Moreover, our initialization strategy can be easily integrated into various transformer-based architectures such as Swin Transformer and MLP-Mixer with consistent improvements in performance.
Rethinking Softmax: Self-Attention with Polynomial Activations
Oct 24, 2024This paper challenges the conventional belief that softmax attention in transformers is effective primarily because it generates a probability distribution for attention allocation. Instead, we theoretically show that its success lies in its ability to implicitly regularize the Frobenius norm of the attention matrix during training. We then explore alternative activations that regularize the Frobenius norm of the attention matrix, demonstrating that certain polynomial activations can achieve this effect, making them suitable for attention-based architectures. Empirical results indicate these activations perform comparably or better than softmax across various computer vision and language tasks, suggesting new possibilities for attention mechanisms beyond softmax.
Structured Initialization for Attention in Vision Transformers
Apr 01, 2024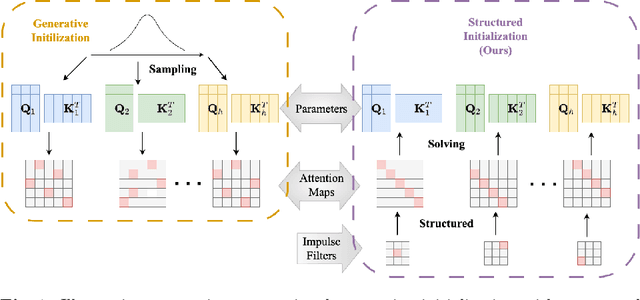

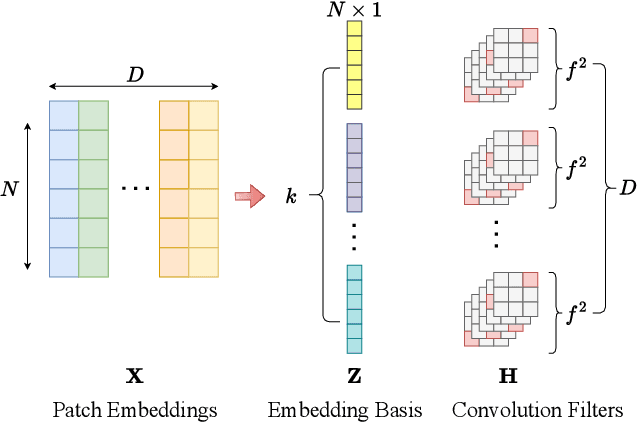
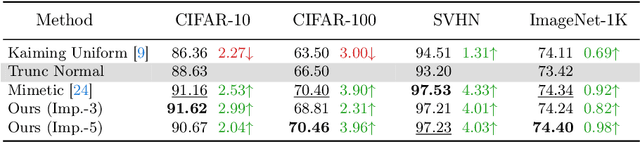
The training of vision transformer (ViT) networks on small-scale datasets poses a significant challenge. By contrast, convolutional neural networks (CNNs) have an architectural inductive bias enabling them to perform well on such problems. In this paper, we argue that the architectural bias inherent to CNNs can be reinterpreted as an initialization bias within ViT. This insight is significant as it empowers ViTs to perform equally well on small-scale problems while maintaining their flexibility for large-scale applications. Our inspiration for this ``structured'' initialization stems from our empirical observation that random impulse filters can achieve comparable performance to learned filters within CNNs. Our approach achieves state-of-the-art performance for data-efficient ViT learning across numerous benchmarks including CIFAR-10, CIFAR-100, and SVHN.
Convolutional Initialization for Data-Efficient Vision Transformers
Jan 23, 2024Training vision transformer networks on small datasets poses challenges. In contrast, convolutional neural networks (CNNs) can achieve state-of-the-art performance by leveraging their architectural inductive bias. In this paper, we investigate whether this inductive bias can be reinterpreted as an initialization bias within a vision transformer network. Our approach is motivated by the finding that random impulse filters can achieve almost comparable performance to learned filters in CNNs. We introduce a novel initialization strategy for transformer networks that can achieve comparable performance to CNNs on small datasets while preserving its architectural flexibility.
Robust Point Cloud Processing through Positional Embedding
Sep 01, 2023End-to-end trained per-point embeddings are an essential ingredient of any state-of-the-art 3D point cloud processing such as detection or alignment. Methods like PointNet, or the more recent point cloud transformer -- and its variants -- all employ learned per-point embeddings. Despite impressive performance, such approaches are sensitive to out-of-distribution (OOD) noise and outliers. In this paper, we explore the role of an analytical per-point embedding based on the criterion of bandwidth. The concept of bandwidth enables us to draw connections with an alternate per-point embedding -- positional embedding, particularly random Fourier features. We present compelling robust results across downstream tasks such as point cloud classification and registration with several categories of OOD noise.
Fast Neural Scene Flow
Apr 20, 2023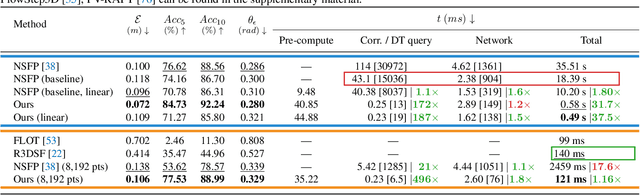



Neural Scene Flow Prior (NSFP) is of significant interest to the vision community due to its inherent robustness to out-of-distribution (OOD) effects and its ability to deal with dense lidar points. The approach utilizes a coordinate neural network to estimate scene flow at runtime, without any training. However, it is up to 100 times slower than current state-of-the-art learning methods. In other applications such as image, video, and radiance function reconstruction innovations in speeding up the runtime performance of coordinate networks have centered upon architectural changes. In this paper, we demonstrate that scene flow is different -- with the dominant computational bottleneck stemming from the loss function itself (i.e., Chamfer distance). Further, we rediscover the distance transform (DT) as an efficient, correspondence-free loss function that dramatically speeds up the runtime optimization. Our fast neural scene flow (FNSF) approach reports for the first time real-time performance comparable to learning methods, without any training or OOD bias on two of the largest open autonomous driving (AV) lidar datasets Waymo Open and Argoverse.
Trading Positional Complexity vs. Deepness in Coordinate Networks
May 18, 2022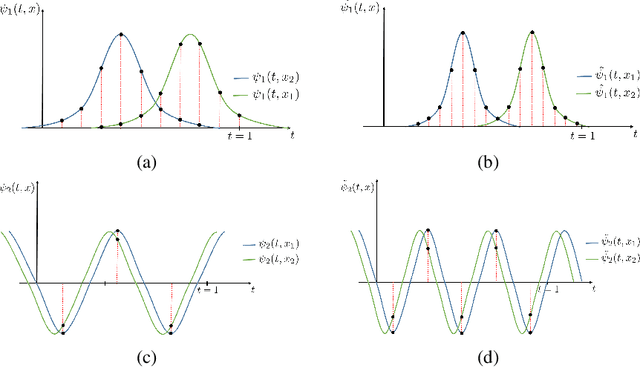
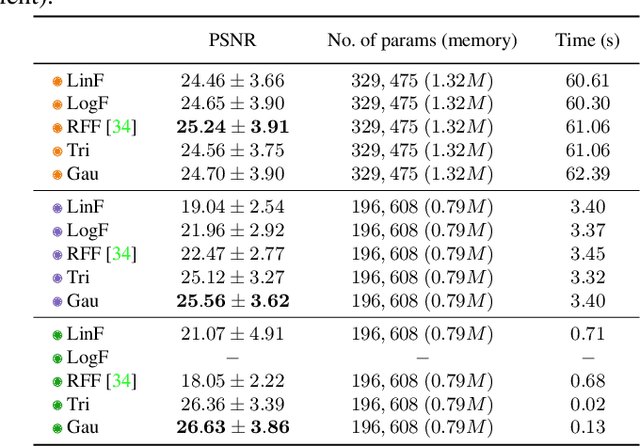
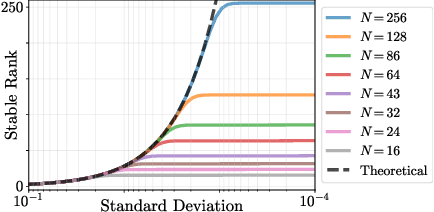
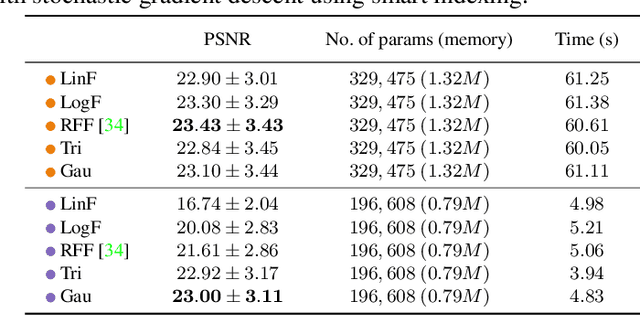
It is well noted that coordinate-based MLPs benefit -- in terms of preserving high-frequency information -- through the encoding of coordinate positions as an array of Fourier features. Hitherto, the rationale for the effectiveness of these positional encodings has been mainly studied through a Fourier lens. In this paper, we strive to broaden this understanding by showing that alternative non-Fourier embedding functions can indeed be used for positional encoding. Moreover, we show that their performance is entirely determined by a trade-off between the stable rank of the embedded matrix and the distance preservation between embedded coordinates. We further establish that the now ubiquitous Fourier feature mapping of position is a special case that fulfills these conditions. Consequently, we present a more general theory to analyze positional encoding in terms of shifted basis functions. In addition, we argue that employing a more complex positional encoding -- that scales exponentially with the number of modes -- requires only a linear (rather than deep) coordinate function to achieve comparable performance. Counter-intuitively, we demonstrate that trading positional embedding complexity for network deepness is orders of magnitude faster than current state-of-the-art; despite the additional embedding complexity. To this end, we develop the necessary theoretical formulae and empirically verify that our theoretical claims hold in practice.
Rethinking Positional Encoding
Jul 13, 2021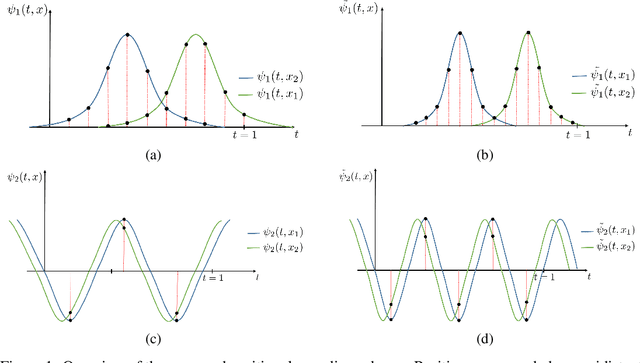
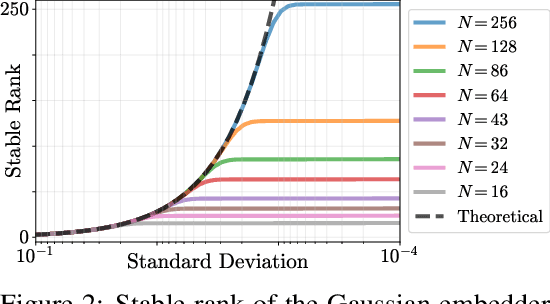
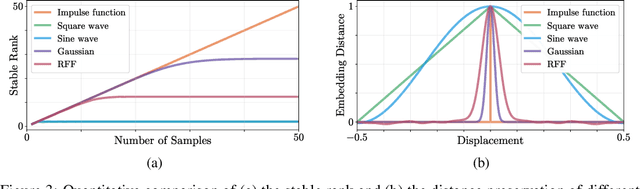
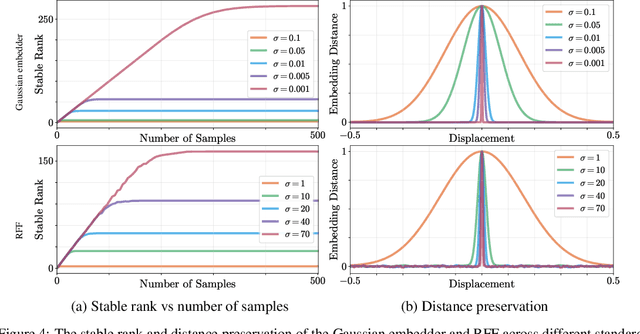
It is well noted that coordinate based MLPs benefit greatly -- in terms of preserving high-frequency information -- through the encoding of coordinate positions as an array of Fourier features. Hitherto, the rationale for the effectiveness of these positional encodings has been solely studied through a Fourier lens. In this paper, we strive to broaden this understanding by showing that alternative non-Fourier embedding functions can indeed be used for positional encoding. Moreover, we show that their performance is entirely determined by a trade-off between the stable rank of the embedded matrix and the distance preservation between embedded coordinates. We further establish that the now ubiquitous Fourier feature mapping of position is a special case that fulfills these conditions. Consequently, we present a more general theory to analyze positional encoding in terms of shifted basis functions. To this end, we develop the necessary theoretical formulae and empirically verify that our theoretical claims hold in practice. Codes available at https://github.com/osiriszjq/Rethinking-positional-encoding.