 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAOI: Turning Failed Trajectories into Training Signals for Autonomous Cloud Diagnosis
Mar 05, 2026Large language model (LLM) agents offer a promising data-driven approach to automating Site Reliability Engineering (SRE), yet their enterprise deployment is constrained by three challenges: restricted access to proprietary data, unsafe action execution under permission-governed environments, and the inability of closed systems to improve from failures. We present AOI (Autonomous Operations Intelligence), a trainable multi-agent framework formulating automated operations as a structured trajectory learning problem under security constraints. Our approach integrates three key components. First, a trainable diagnostic system applies Group Relative Policy Optimization (GRPO) to distill expert-level knowledge into locally deployed open-source models, enabling preference-based learning without exposing sensitive data. Second, a read-write separated execution architecture decomposes operational trajectories into observation, reasoning, and action phases, allowing safe learning while preventing unauthorized state mutation. Third, a Failure Trajectory Closed-Loop Evolver mines unsuccessful trajectories and converts them into corrective supervision signals, enabling continual data augmentation. Evaluated on the AIOpsLab benchmark, our contributions yield cumulative gains. (1) The AOI runtime alone achieves 66.3% best@5 success on all 86 tasks, outperforming the prior state-of-the-art (41.9%) by 24.4 points. (2) Adding Observer GRPO training, a locally deployed 14B model reaches 42.9% avg@1 on 63 held-out tasks with unseen fault types, surpassing Claude Sonnet 4.5. (3) The Evolver converts 37 failed trajectories into diagnostic guidance, improving end-to-end avg@5 by 4.8 points while reducing variance by 35%.
CVBench: Evaluating Cross-Video Synergies for Complex Multimodal Understanding and Reasoning
Aug 28, 2025While multimodal large language models (MLLMs) exhibit strong performance on single-video tasks (e.g., video question answering), their ability across multiple videos remains critically underexplored. However, this capability is essential for real-world applications, including multi-camera surveillance and cross-video procedural learning. To bridge this gap, we present CVBench, the first comprehensive benchmark designed to assess cross-video relational reasoning rigorously. CVBench comprises 1,000 question-answer pairs spanning three hierarchical tiers: cross-video object association (identifying shared entities), cross-video event association (linking temporal or causal event chains), and cross-video complex reasoning (integrating commonsense and domain knowledge). Built from five domain-diverse video clusters (e.g., sports, life records), the benchmark challenges models to synthesise information across dynamic visual contexts. Extensive evaluation of 10+ leading MLLMs (including GPT-4o, Gemini-2.0-flash, Qwen2.5-VL) under zero-shot or chain-of-thought prompting paradigms. Key findings reveal stark performance gaps: even top models, such as GPT-4o, achieve only 60% accuracy on causal reasoning tasks, compared to the 91% accuracy of human performance. Crucially, our analysis reveals fundamental bottlenecks inherent in current MLLM architectures, notably deficient inter-video context retention and poor disambiguation of overlapping entities. CVBench establishes a rigorous framework for diagnosing and advancing multi-video reasoning, offering architectural insights for next-generation MLLMs. The data and evaluation code are available at https://github.com/Hokhim2/CVBench.
Structured Initialization for Vision Transformers
May 26, 2025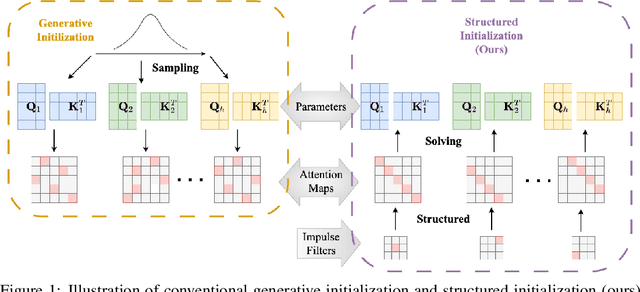

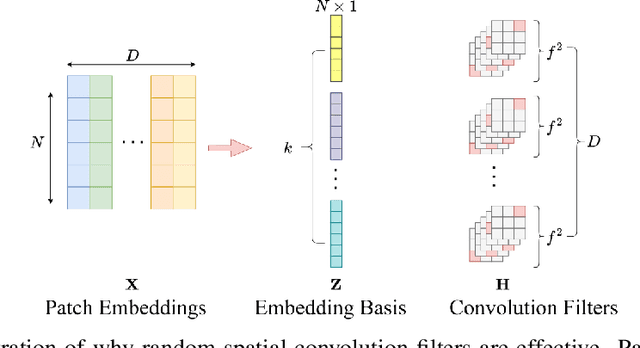

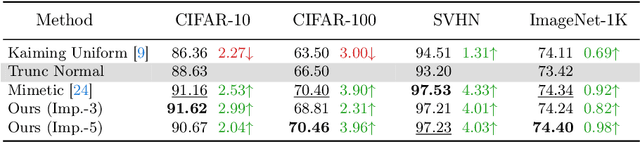
Convolutional Neural Networks (CNNs) inherently encode strong inductive biases, enabling effective generalization on small-scale datasets. In this paper, we propose integrating this inductive bias into ViTs, not through an architectural intervention but solely through initialization. The motivation here is to have a ViT that can enjoy strong CNN-like performance when data assets are small, but can still scale to ViT-like performance as the data expands. Our approach is motivated by our empirical results that random impulse filters can achieve commensurate performance to learned filters within a CNN. We improve upon current ViT initialization strategies, which typically rely on empirical heuristics such as using attention weights from pretrained models or focusing on the distribution of attention weights without enforcing structures. Empirical results demonstrate that our method significantly outperforms standard ViT initialization across numerous small and medium-scale benchmarks, including Food-101, CIFAR-10, CIFAR-100, STL-10, Flowers, and Pets, while maintaining comparative performance on large-scale datasets such as ImageNet-1K. Moreover, our initialization strategy can be easily integrated into various transformer-based architectures such as Swin Transformer and MLP-Mixer with consistent improvements in performance.
Beyond Idle Channels: Unlocking Idle Space with Signal Alignment in Massive MIMO Cognitive Radio Networks
Dec 09, 2024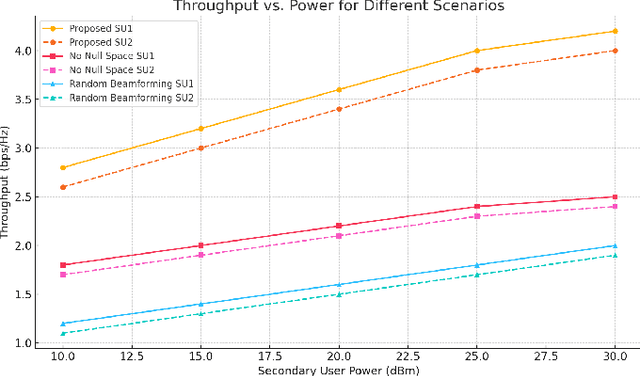
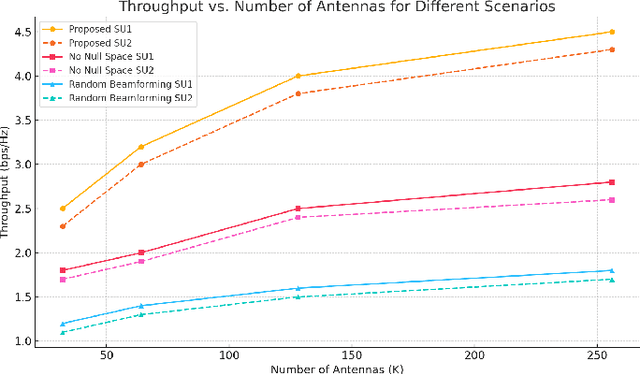
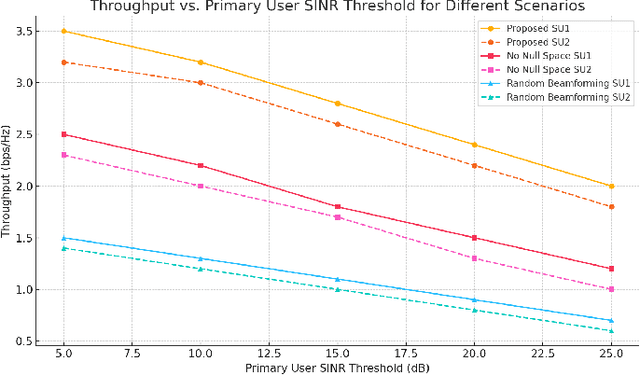
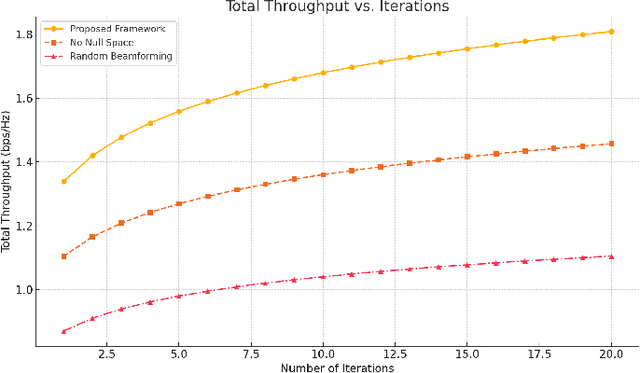
Cognitive radio networks (CRNs) have traditionally focused on utilizing idle channels to enhance spectrum efficiency. However, as wireless networks grow denser, channel-centric strategies face increasing limitations. This paper introduces a paradigm shift by exploring the underutilized potential of idle spatial dimensions, termed idle space, in co-channel transmissions. By integrating massive multiple-input multiple-output (MIMO) systems with signal alignment techniques, we enable secondary users to transmit without causing interference to primary users by aligning their signals within the null spaces of primary receivers. We propose a comprehensive framework that synergizes spatial spectrum sensing, signal alignment, and resource allocation, specifically designed for secondary users in CRNs. Theoretical analyses and extensive simulations validate the framework, demonstrating substantial gains in spectrum efficiency, throughput, and interference mitigation. The results show that the proposed approach not only ensures interference-free coexistence with primary users but also unlocks untapped spatial resources for secondary transmissions.
Dense Cross-Connected Ensemble Convolutional Neural Networks for Enhanced Model Robustness
Dec 09, 2024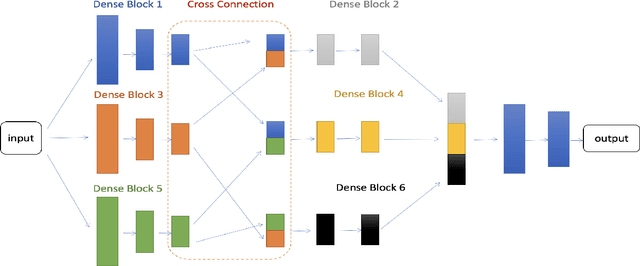
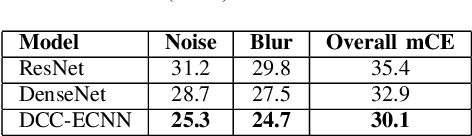
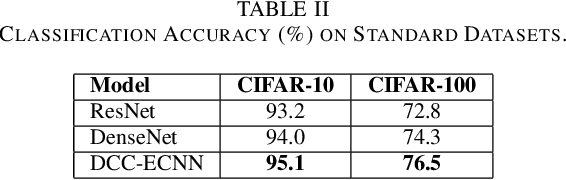
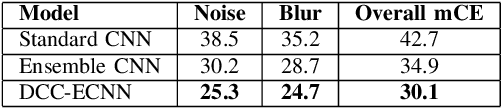
The resilience of convolutional neural networks against input variations and adversarial attacks remains a significant challenge in image recognition tasks. Motivated by the need for more robust and reliable image recognition systems, we propose the Dense Cross-Connected Ensemble Convolutional Neural Network (DCC-ECNN). This novel architecture integrates the dense connectivity principle of DenseNet with the ensemble learning strategy, incorporating intermediate cross-connections between different DenseNet paths to facilitate extensive feature sharing and integration. The DCC-ECNN architecture leverages DenseNet's efficient parameter usage and depth while benefiting from the robustness of ensemble learning, ensuring a richer and more resilient feature representation.
Structured Initialization for Attention in Vision Transformers
Apr 01, 2024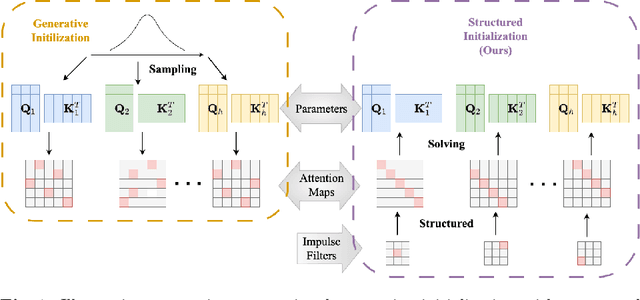

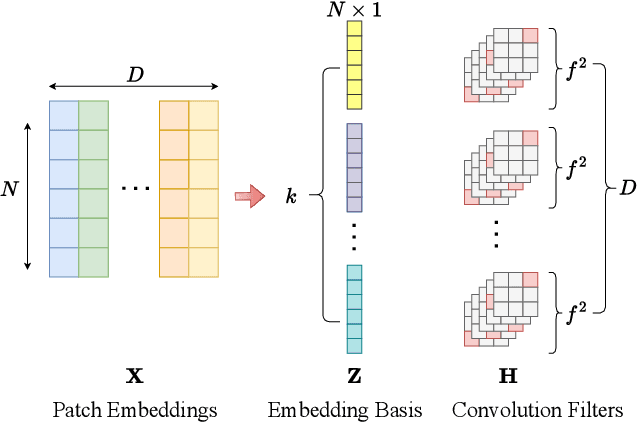
The training of vision transformer (ViT) networks on small-scale datasets poses a significant challenge. By contrast, convolutional neural networks (CNNs) have an architectural inductive bias enabling them to perform well on such problems. In this paper, we argue that the architectural bias inherent to CNNs can be reinterpreted as an initialization bias within ViT. This insight is significant as it empowers ViTs to perform equally well on small-scale problems while maintaining their flexibility for large-scale applications. Our inspiration for this ``structured'' initialization stems from our empirical observation that random impulse filters can achieve comparable performance to learned filters within CNNs. Our approach achieves state-of-the-art performance for data-efficient ViT learning across numerous benchmarks including CIFAR-10, CIFAR-100, and SVHN.
Self-Supervised Multi-Frame Neural Scene Flow
Mar 24, 2024



Neural Scene Flow Prior (NSFP) and Fast Neural Scene Flow (FNSF) have shown remarkable adaptability in the context of large out-of-distribution autonomous driving. Despite their success, the underlying reasons for their astonishing generalization capabilities remain unclear. Our research addresses this gap by examining the generalization capabilities of NSFP through the lens of uniform stability, revealing that its performance is inversely proportional to the number of input point clouds. This finding sheds light on NSFP's effectiveness in handling large-scale point cloud scene flow estimation tasks. Motivated by such theoretical insights, we further explore the improvement of scene flow estimation by leveraging historical point clouds across multiple frames, which inherently increases the number of point clouds. Consequently, we propose a simple and effective method for multi-frame point cloud scene flow estimation, along with a theoretical evaluation of its generalization abilities. Our analysis confirms that the proposed method maintains a limited generalization error, suggesting that adding multiple frames to the scene flow optimization process does not detract from its generalizability. Extensive experimental results on large-scale autonomous driving Waymo Open and Argoverse lidar datasets demonstrate that the proposed method achieves state-of-the-art performance.
Fast Kernel Scene Flow
Mar 09, 2024In contrast to current state-of-the-art methods, such as NSFP [25], which employ deep implicit neural functions for modeling scene flow, we present a novel approach that utilizes classical kernel representations. This representation enables our approach to effectively handle dense lidar points while demonstrating exceptional computational efficiency -- compared to recent deep approaches -- achieved through the solution of a linear system. As a runtime optimization-based method, our model exhibits impressive generalizability across various out-of-distribution scenarios, achieving competitive performance on large-scale lidar datasets. We propose a new positional encoding-based kernel that demonstrates state-of-the-art performance in efficient lidar scene flow estimation on large-scale point clouds. An important highlight of our method is its near real-time performance (~150-170 ms) with dense lidar data (~8k-144k points), enabling a variety of practical applications in robotics and autonomous driving scenarios.
Convolutional Initialization for Data-Efficient Vision Transformers
Jan 23, 2024Training vision transformer networks on small datasets poses challenges. In contrast, convolutional neural networks (CNNs) can achieve state-of-the-art performance by leveraging their architectural inductive bias. In this paper, we investigate whether this inductive bias can be reinterpreted as an initialization bias within a vision transformer network. Our approach is motivated by the finding that random impulse filters can achieve almost comparable performance to learned filters in CNNs. We introduce a novel initialization strategy for transformer networks that can achieve comparable performance to CNNs on small datasets while preserving its architectural flexibility.
Multi-Body Neural Scene Flow
Oct 16, 2023



The test-time optimization of scene flow - using a coordinate network as a neural prior - has gained popularity due to its simplicity, lack of dataset bias, and state-of-the-art performance. We observe, however, that although coordinate networks capture general motions by implicitly regularizing the scene flow predictions to be spatially smooth, the neural prior by itself is unable to identify the underlying multi-body rigid motions present in real-world data. To address this, we show that multi-body rigidity can be achieved without the cumbersome and brittle strategy of constraining the $SE(3)$ parameters of each rigid body as done in previous works. This is achieved by regularizing the scene flow optimization to encourage isometry in flow predictions for rigid bodies. This strategy enables multi-body rigidity in scene flow while maintaining a continuous flow field, hence allowing dense long-term scene flow integration across a sequence of point clouds. We conduct extensive experiments on real-world datasets and demonstrate that our approach outperforms the state-of-the-art in 3D scene flow and long-term point-wise 4D trajectory prediction. The code is available at: \href{https://github.com/kavisha725/MBNSF}{https://github.com/kavisha725/MBNSF}.