 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Initialization for Attention in Vision Transformers
Paper and Code
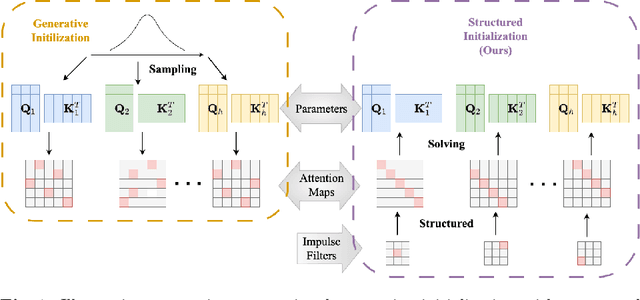

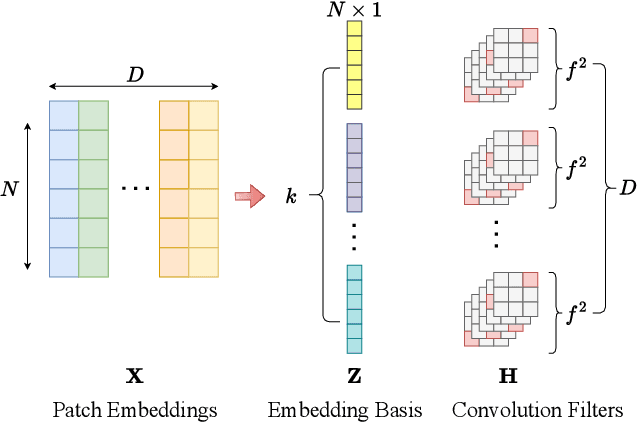
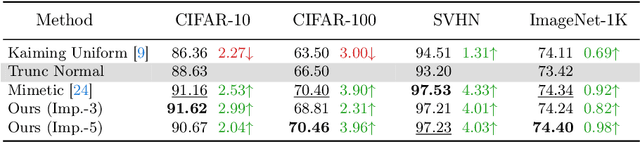
The training of vision transformer (ViT) networks on small-scale datasets poses a significant challenge. By contrast, convolutional neural networks (CNNs) have an architectural inductive bias enabling them to perform well on such problems. In this paper, we argue that the architectural bias inherent to CNNs can be reinterpreted as an initialization bias within ViT. This insight is significant as it empowers ViTs to perform equally well on small-scale problems while maintaining their flexibility for large-scale applications. Our inspiration for this ``structured'' initialization stems from our empirical observation that random impulse filters can achieve comparable performance to learned filters within CNNs. Our approach achieves state-of-the-art performance for data-efficient ViT learning across numerous benchmarks including CIFAR-10, CIFAR-100, and SVHN.