 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerfecting Depth: Uncertainty-Aware Enhancement of Metric Depth
Jun 05, 2025



We propose a novel two-stage framework for sensor depth enhancement, called Perfecting Depth. This framework leverages the stochastic nature of diffusion models to automatically detect unreliable depth regions while preserving geometric cues. In the first stage (stochastic estimation), the method identifies unreliable measurements and infers geometric structure by leveraging a training-inference domain gap. In the second stage (deterministic refinement), it enforces structural consistency and pixel-level accuracy using the uncertainty map derived from the first stage. By combining stochastic uncertainty modeling with deterministic refinement, our method yields dense, artifact-free depth maps with improved reliability. Experimental results demonstrate its effectiveness across diverse real-world scenarios. Furthermore, theoretical analysis, various experiments, and qualitative visualizations validate its robustness and scalability. Our framework sets a new baseline for sensor depth enhancement, with potential applications in autonomous driving, robotics, and immersive technologies.
LTM3D: Bridging Token Spaces for Conditional 3D Generation with Auto-Regressive Diffusion Framework
May 30, 2025We present LTM3D, a Latent Token space Modeling framework for conditional 3D shape generation that integrates the strengths of diffusion and auto-regressive (AR) models. While diffusion-based methods effectively model continuous latent spaces and AR models excel at capturing inter-token dependencies, combining these paradigms for 3D shape generation remains a challenge. To address this, LTM3D features a Conditional Distribution Modeling backbone, leveraging a masked autoencoder and a diffusion model to enhance token dependency learning. Additionally, we introduce Prefix Learning, which aligns condition tokens with shape latent tokens during generation, improving flexibility across modalities. We further propose a Latent Token Reconstruction module with Reconstruction-Guided Sampling to reduce uncertainty and enhance structural fidelity in generated shapes. Our approach operates in token space, enabling support for multiple 3D representations, including signed distance fields, point clouds, meshes, and 3D Gaussian Splatting. Extensive experiments on image- and text-conditioned shape generation tasks demonstrate that LTM3D outperforms existing methods in prompt fidelity and structural accuracy while offering a generalizable framework for multi-modal, multi-representation 3D generation.
StreamGS: Online Generalizable Gaussian Splatting Reconstruction for Unposed Image Streams
Mar 08, 2025



The advent of 3D Gaussian Splatting (3DGS) has advanced 3D scene reconstruction and novel view synthesis. With the growing interest of interactive applications that need immediate feedback, online 3DGS reconstruction in real-time is in high demand. However, none of existing methods yet meet the demand due to three main challenges: the absence of predetermined camera parameters, the need for generalizable 3DGS optimization, and the necessity of reducing redundancy. We propose StreamGS, an online generalizable 3DGS reconstruction method for unposed image streams, which progressively transform image streams to 3D Gaussian streams by predicting and aggregating per-frame Gaussians. Our method overcomes the limitation of the initial point reconstruction \cite{dust3r} in tackling out-of-domain (OOD) issues by introducing a content adaptive refinement. The refinement enhances cross-frame consistency by establishing reliable pixel correspondences between adjacent frames. Such correspondences further aid in merging redundant Gaussians through cross-frame feature aggregation. The density of Gaussians is thereby reduced, empowering online reconstruction by significantly lowering computational and memory costs. Extensive experiments on diverse datasets have demonstrated that StreamGS achieves quality on par with optimization-based approaches but does so 150 times faster, and exhibits superior generalizability in handling OOD scenes.
EnvPoser: Environment-aware Realistic Human Motion Estimation from Sparse Observations with Uncertainty Modeling
Dec 13, 2024



Estimating full-body motion using the tracking signals of head and hands from VR devices holds great potential for various applications. However, the sparsity and unique distribution of observations present a significant challenge, resulting in an ill-posed problem with multiple feasible solutions (i.e., hypotheses). This amplifies uncertainty and ambiguity in full-body motion estimation, especially for the lower-body joints. Therefore, we propose a new method, EnvPoser, that employs a two-stage framework to perform full-body motion estimation using sparse tracking signals and pre-scanned environment from VR devices. EnvPoser models the multi-hypothesis nature of human motion through an uncertainty-aware estimation module in the first stage. In the second stage, we refine these multi-hypothesis estimates by integrating semantic and geometric environmental constraints, ensuring that the final motion estimation aligns realistically with both the environmental context and physical interactions. Qualitative and quantitative experiments on two public datasets demonstrate that our method achieves state-of-the-art performance, highlighting significant improvements in human motion estimation within motion-environment interaction scenarios.
Context-Conditioned Spatio-Temporal Predictive Learning for Reliable V2V Channel Prediction
Sep 16, 2024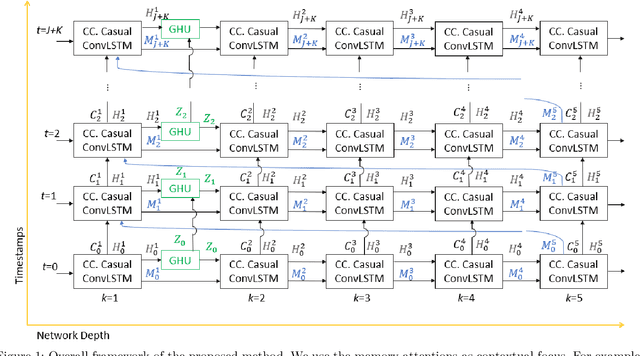
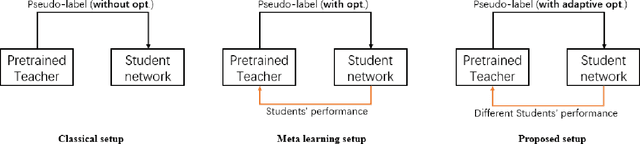
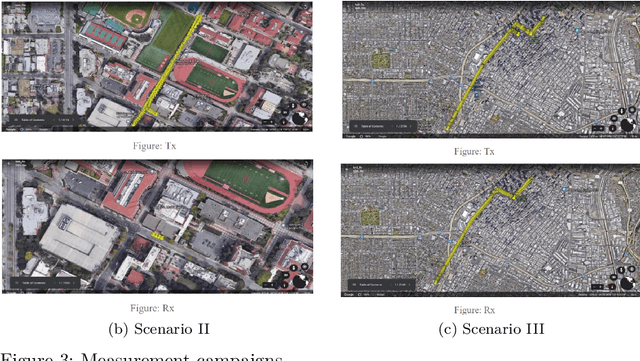
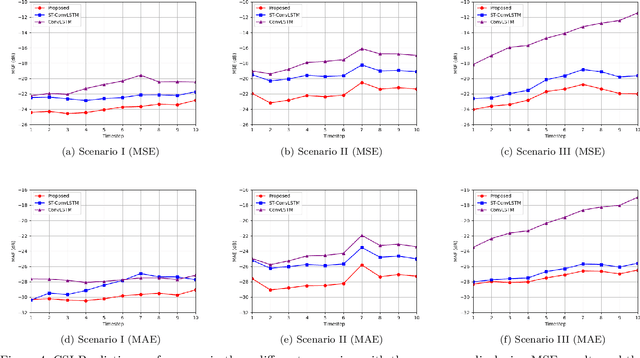
Achieving reliable multidimensional Vehicle-to-Vehicle (V2V) channel state information (CSI) prediction is both challenging and crucial for optimizing downstream tasks that depend on instantaneous CSI. This work extends traditional prediction approaches by focusing on four-dimensional (4D) CSI, which includes predictions over time, bandwidth, and antenna (TX and RX) space. Such a comprehensive framework is essential for addressing the dynamic nature of mobility environments within intelligent transportation systems, necessitating the capture of both temporal and spatial dependencies across diverse domains. To address this complexity, we propose a novel context-conditioned spatiotemporal predictive learning method. This method leverages causal convolutional long short-term memory (CA-ConvLSTM) to effectively capture dependencies within 4D CSI data, and incorporates context-conditioned attention mechanisms to enhance the efficiency of spatiotemporal memory updates. Additionally, we introduce an adaptive meta-learning scheme tailored for recurrent networks to mitigate the issue of accumulative prediction errors. We validate the proposed method through empirical studies conducted across three different geometric configurations and mobility scenarios. Our results demonstrate that the proposed approach outperforms existing state-of-the-art predictive models, achieving superior performance across various geometries. Moreover, we show that the meta-learning framework significantly enhances the performance of recurrent-based predictive models in highly challenging cross-geometry settings, thus highlighting its robustness and adaptability.
Self-Supervised Multi-Frame Neural Scene Flow
Mar 24, 2024



Neural Scene Flow Prior (NSFP) and Fast Neural Scene Flow (FNSF) have shown remarkable adaptability in the context of large out-of-distribution autonomous driving. Despite their success, the underlying reasons for their astonishing generalization capabilities remain unclear. Our research addresses this gap by examining the generalization capabilities of NSFP through the lens of uniform stability, revealing that its performance is inversely proportional to the number of input point clouds. This finding sheds light on NSFP's effectiveness in handling large-scale point cloud scene flow estimation tasks. Motivated by such theoretical insights, we further explore the improvement of scene flow estimation by leveraging historical point clouds across multiple frames, which inherently increases the number of point clouds. Consequently, we propose a simple and effective method for multi-frame point cloud scene flow estimation, along with a theoretical evaluation of its generalization abilities. Our analysis confirms that the proposed method maintains a limited generalization error, suggesting that adding multiple frames to the scene flow optimization process does not detract from its generalizability. Extensive experimental results on large-scale autonomous driving Waymo Open and Argoverse lidar datasets demonstrate that the proposed method achieves state-of-the-art performance.
Correlation-Embedded Transformer Tracking: A Single-Branch Framework
Jan 23, 2024Developing robust and discriminative appearance models has been a long-standing research challenge in visual object tracking. In the prevalent Siamese-based paradigm, the features extracted by the Siamese-like networks are often insufficient to model the tracked targets and distractor objects, thereby hindering them from being robust and discriminative simultaneously. While most Siamese trackers focus on designing robust correlation operations, we propose a novel single-branch tracking framework inspired by the transformer. Unlike the Siamese-like feature extraction, our tracker deeply embeds cross-image feature correlation in multiple layers of the feature network. By extensively matching the features of the two images through multiple layers, it can suppress non-target features, resulting in target-aware feature extraction. The output features can be directly used for predicting target locations without additional correlation steps. Thus, we reformulate the two-branch Siamese tracking as a conceptually simple, fully transformer-based Single-Branch Tracking pipeline, dubbed SBT. After conducting an in-depth analysis of the SBT baseline, we summarize many effective design principles and propose an improved tracker dubbed SuperSBT. SuperSBT adopts a hierarchical architecture with a local modeling layer to enhance shallow-level features. A unified relation modeling is proposed to remove complex handcrafted layer pattern designs. SuperSBT is further improved by masked image modeling pre-training, integrating temporal modeling, and equipping with dedicated prediction heads. Thus, SuperSBT outperforms the SBT baseline by 4.7%,3.0%, and 4.5% AUC scores in LaSOT, TrackingNet, and GOT-10K. Notably, SuperSBT greatly raises the speed of SBT from 37 FPS to 81 FPS. Extensive experiments show that our method achieves superior results on eight VOT benchmarks.
Dynamic Inertial Poser (DynaIP): Part-Based Motion Dynamics Learning for Enhanced Human Pose Estimation with Sparse Inertial Sensors
Dec 02, 2023This paper introduces a novel human pose estimation approach using sparse inertial sensors, addressing the shortcomings of previous methods reliant on synthetic data. It leverages a diverse array of real inertial motion capture data from different skeleton formats to improve motion diversity and model generalization. This method features two innovative components: a pseudo-velocity regression model for dynamic motion capture with inertial sensors, and a part-based model dividing the body and sensor data into three regions, each focusing on their unique characteristics. The approach demonstrates superior performance over state-of-the-art models across five public datasets, notably reducing pose error by 19\% on the DIP-IMU dataset, thus representing a significant improvement in inertial sensor-based human pose estimation. We will make the implementation of our model available for public use.
Timestamp-supervised Wearable-based Activity Segmentation and Recognition with Contrastive Learning and Order-Preserving Optimal Transport
Oct 13, 2023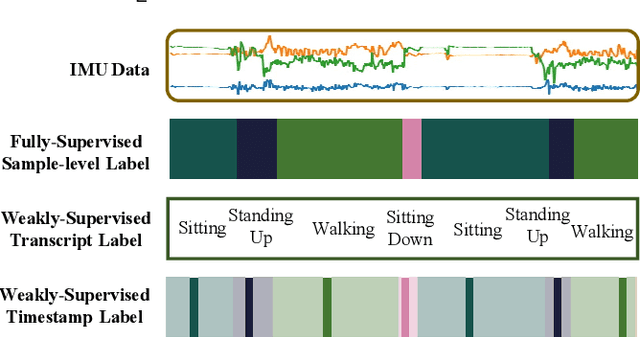

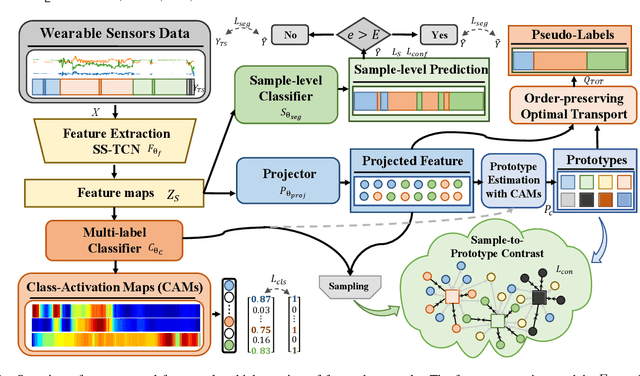
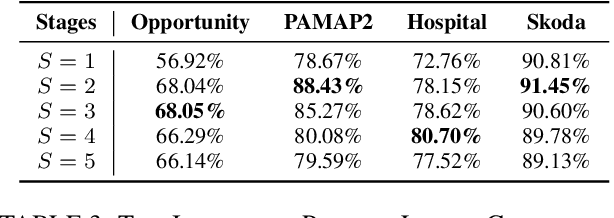
Human activity recognition (HAR) with wearables is one of the serviceable technologies in ubiquitous and mobile computing applications. The sliding-window scheme is widely adopted while suffering from the multi-class windows problem. As a result, there is a growing focus on joint segmentation and recognition with deep-learning methods, aiming at simultaneously dealing with HAR and time-series segmentation issues. However, obtaining the full activity annotations of wearable data sequences is resource-intensive or time-consuming, while unsupervised methods yield poor performance. To address these challenges, we propose a novel method for joint activity segmentation and recognition with timestamp supervision, in which only a single annotated sample is needed in each activity segment. However, the limited information of sparse annotations exacerbates the gap between recognition and segmentation tasks, leading to sub-optimal model performance. Therefore, the prototypes are estimated by class-activation maps to form a sample-to-prototype contrast module for well-structured embeddings. Moreover, with the optimal transport theory, our approach generates the sample-level pseudo-labels that take advantage of unlabeled data between timestamp annotations for further performance improvement. Comprehensive experiments on four public HAR datasets demonstrate that our model trained with timestamp supervision is superior to the state-of-the-art weakly-supervised methods and achieves comparable performance to the fully-supervised approaches.
Exploiting Semantic Localization in Highly Dynamic Wireless Networks Using Deep Homoscedastic Domain Adaptation
Oct 11, 2023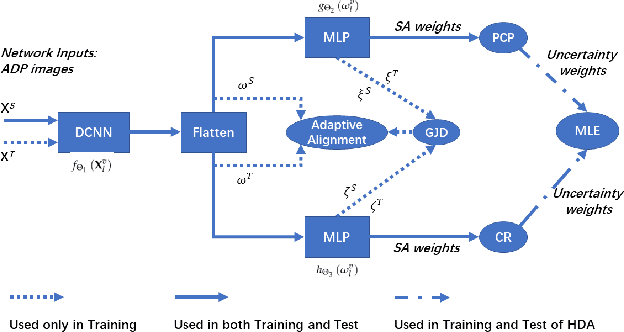
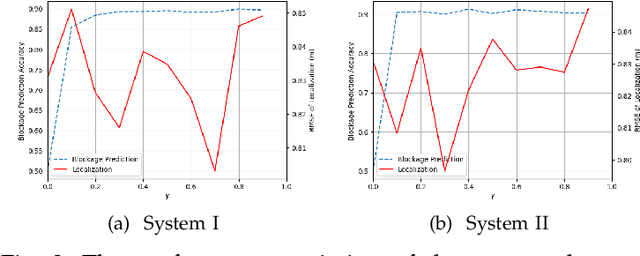
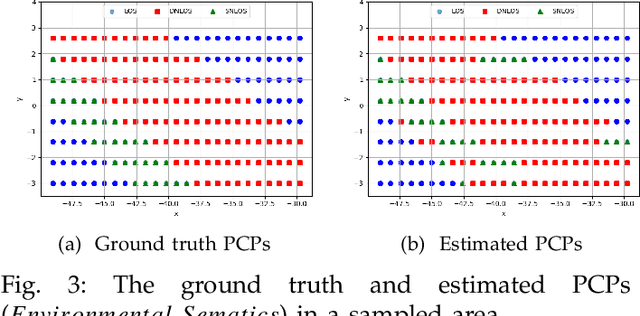
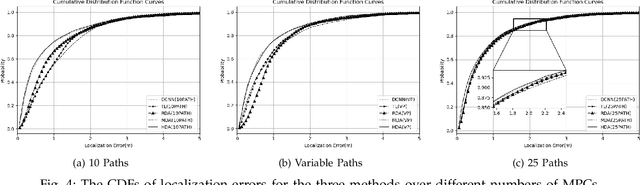
Localization in GPS-denied outdoor locations, such as street canyons in an urban or metropolitan environment, has many applications. Machine Learning (ML) is widely used to tackle this critical problem. One challenge lies in the mixture of line-of-sight (LOS), obstructed LOS (OLOS), and non-LOS (NLOS) conditions. In this paper, we consider a semantic localization that treats these three propagation conditions as the ''semantic objects", and aims to determine them together with the actual localization, and show that this increases accuracy and robustness. Furthermore, the propagation conditions are highly dynamic, since obstruction by cars or trucks can change the channel state information (CSI) at a fixed location over time. We therefore consider the blockage by such dynamic objects as another semantic state. Based on these considerations, we formulate the semantic localization with a joint task (coordinates regression and semantics classification) learning problem. Another problem created by the dynamics is the fact that each location may be characterized by a number of different CSIs. To avoid the need for excessive amount of labeled training data, we propose a multi-task deep domain adaptation (DA) based localization technique, training neural networks with a limited number of labeled samples and numerous unlabeled ones. Besides, we introduce novel scenario adaptive learning strategies to ensure efficient representation learning and successful knowledge transfer. Finally, we use Bayesian theory for uncertainty modeling of the importance weights in each task, reducing the need for time-consuming parameter finetuning; furthermore, with some mild assumptions, we derive the related log-likelihood for the joint task and present the deep homoscedastic DA based localization method.