 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Semantic Localization in Highly Dynamic Wireless Networks Using Deep Homoscedastic Domain Adaptation
Oct 11, 2023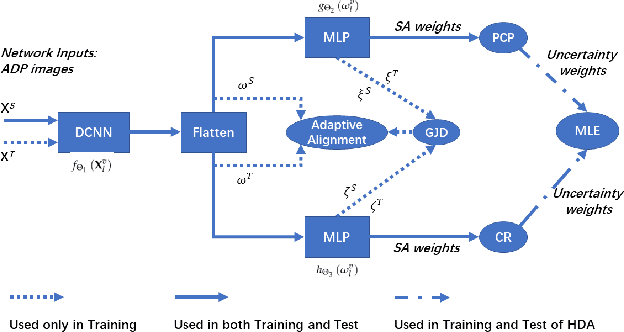
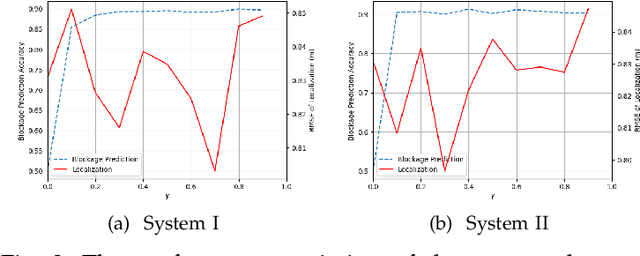
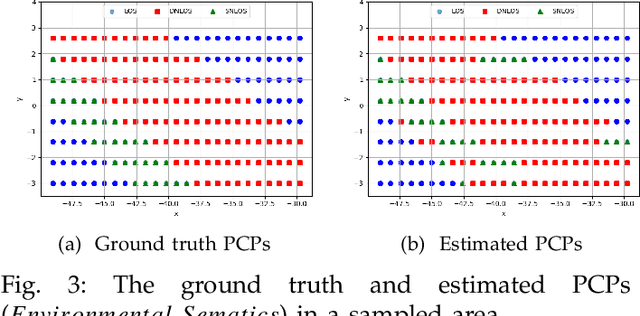
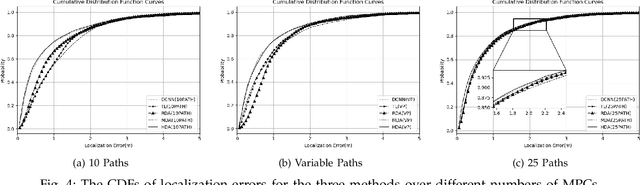
Localization in GPS-denied outdoor locations, such as street canyons in an urban or metropolitan environment, has many applications. Machine Learning (ML) is widely used to tackle this critical problem. One challenge lies in the mixture of line-of-sight (LOS), obstructed LOS (OLOS), and non-LOS (NLOS) conditions. In this paper, we consider a semantic localization that treats these three propagation conditions as the ''semantic objects", and aims to determine them together with the actual localization, and show that this increases accuracy and robustness. Furthermore, the propagation conditions are highly dynamic, since obstruction by cars or trucks can change the channel state information (CSI) at a fixed location over time. We therefore consider the blockage by such dynamic objects as another semantic state. Based on these considerations, we formulate the semantic localization with a joint task (coordinates regression and semantics classification) learning problem. Another problem created by the dynamics is the fact that each location may be characterized by a number of different CSIs. To avoid the need for excessive amount of labeled training data, we propose a multi-task deep domain adaptation (DA) based localization technique, training neural networks with a limited number of labeled samples and numerous unlabeled ones. Besides, we introduce novel scenario adaptive learning strategies to ensure efficient representation learning and successful knowledge transfer. Finally, we use Bayesian theory for uncertainty modeling of the importance weights in each task, reducing the need for time-consuming parameter finetuning; furthermore, with some mild assumptions, we derive the related log-likelihood for the joint task and present the deep homoscedastic DA based localization method.
Partially Detected Intelligent Traffic Signal Control: Environmental Adaptation
Oct 23, 2019
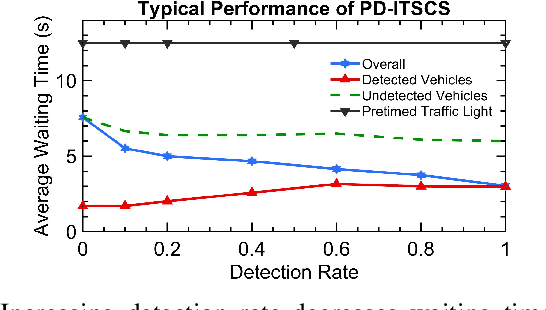


Partially Detected Intelligent Traffic Signal Control (PD-ITSC) systems that can optimize traffic signals based on limited detected information could be a cost-efficient solution for mitigating traffic congestion in the future. In this paper, we focus on a particular problem in PD-ITSC - adaptation to changing environments. To this end, we investigate different reinforcement learning algorithms, including Q-learning, Proximal Policy Optimization (PPO), Advantage Actor-Critic (A2C), and Actor-Critic with Kronecker-Factored Trust Region (ACKTR). Our findings suggest that RL algorithms can find optimal strategies under partial vehicle detection; however, policy-based algorithms can adapt to changing environments more efficiently than value-based algorithms. We use these findings to draw conclusions about the value of different models for PD-ITSC systems.