 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCanonCGT: Reference-Based Color Grading via Canonical Pivot Representation
Jun 01, 2026Reference-based color grading aims to reproduce the tonal mood and lighting of a reference while preserving color harmony and scene structure. Existing photorealistic and filter-based methods often produce unstable tone mappings -- over-shifting or inconsistently retaining colors -- leading to unnatural results. We propose CanonCGT, a two-stage framework built on a canonical pivot -- a style-neutral intermediate representation for stable color mapping. The first stage canonicalizes the input by removing intrinsic tonal bias, and the second color-grades it to match the reference style. A dual-phase training scheme, DP-CGT, combines supervised preset learning with self-supervised refinement on unpaired photographs. CanonCGT delivers photorealistic and tonally consistent results across diverse datasets, surpassing state-of-the-art methods in stability and visual fidelity. Our codes are available at \href{https://github.com/Jinwon-Ko/CanonCGT}{https://github.com/Jinwon-Ko/CanonCGT}
Perfecting Depth: Uncertainty-Aware Enhancement of Metric Depth
Jun 05, 2025



We propose a novel two-stage framework for sensor depth enhancement, called Perfecting Depth. This framework leverages the stochastic nature of diffusion models to automatically detect unreliable depth regions while preserving geometric cues. In the first stage (stochastic estimation), the method identifies unreliable measurements and infers geometric structure by leveraging a training-inference domain gap. In the second stage (deterministic refinement), it enforces structural consistency and pixel-level accuracy using the uncertainty map derived from the first stage. By combining stochastic uncertainty modeling with deterministic refinement, our method yields dense, artifact-free depth maps with improved reliability. Experimental results demonstrate its effectiveness across diverse real-world scenarios. Furthermore, theoretical analysis, various experiments, and qualitative visualizations validate its robustness and scalability. Our framework sets a new baseline for sensor depth enhancement, with potential applications in autonomous driving, robotics, and immersive technologies.
Patch Stitching Data Augmentation for Cancer Classification in Pathology Images
Feb 22, 2025Computational pathology, integrating computational methods and digital imaging, has shown to be effective in advancing disease diagnosis and prognosis. In recent years, the development of machine learning and deep learning has greatly bolstered the power of computational pathology. However, there still remains the issue of data scarcity and data imbalance, which can have an adversarial effect on any computational method. In this paper, we introduce an efficient and effective data augmentation strategy to generate new pathology images from the existing pathology images and thus enrich datasets without additional data collection or annotation costs. To evaluate the proposed method, we employed two sets of colorectal cancer datasets and obtained improved classification results, suggesting that the proposed simple approach holds the potential for alleviating the data scarcity and imbalance in computational pathology.
OMR: Occlusion-Aware Memory-Based Refinement for Video Lane Detection
Aug 14, 2024
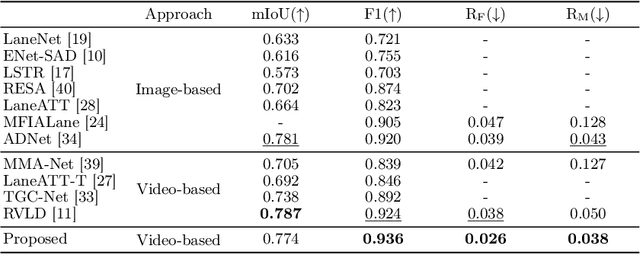
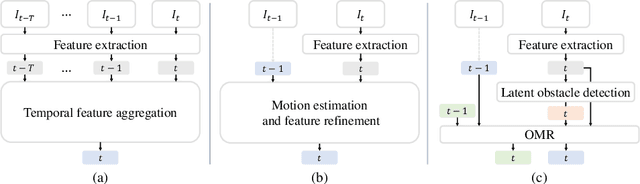

A novel algorithm for video lane detection is proposed in this paper. First, we extract a feature map for a current frame and detect a latent mask for obstacles occluding lanes. Then, we enhance the feature map by developing an occlusion-aware memory-based refinement (OMR) module. It takes the obstacle mask and feature map from the current frame, previous output, and memory information as input, and processes them recursively in a video. Moreover, we apply a novel data augmentation scheme for training the OMR module effectively. Experimental results show that the proposed algorithm outperforms existing techniques on video lane datasets. Our codes are available at https://github.com/dongkwonjin/OMR.
Forbes: Face Obfuscation Rendering via Backpropagation Refinement Scheme
Jul 19, 2024



A novel algorithm for face obfuscation, called Forbes, which aims to obfuscate facial appearance recognizable by humans but preserve the identity and attributes decipherable by machines, is proposed in this paper. Forbes first applies multiple obfuscating transformations with random parameters to an image to remove the identity information distinguishable by humans. Then, it optimizes the parameters to make the transformed image decipherable by machines based on the backpropagation refinement scheme. Finally, it renders an obfuscated image by applying the transformations with the optimized parameters. Experimental results on various datasets demonstrate that Forbes achieves both human indecipherability and machine decipherability excellently. The source codes are available at https://github.com/mcljtkim/Forbes.
Semantic Line Combination Detector
May 01, 2024A novel algorithm, called semantic line combination detector (SLCD), to find an optimal combination of semantic lines is proposed in this paper. It processes all lines in each line combination at once to assess the overall harmony of the lines. First, we generate various line combinations from reliable lines. Second, we estimate the score of each line combination and determine the best one. Experimental results demonstrate that the proposed SLCD outperforms existing semantic line detectors on various datasets. Moreover, it is shown that SLCD can be applied effectively to three vision tasks of vanishing point detection, symmetry axis detection, and composition-based image retrieval. Our codes are available at https://github.com/Jinwon-Ko/SLCD.
Masked Spatial Propagation Network for Sparsity-Adaptive Depth Refinement
Apr 30, 2024The main function of depth completion is to compensate for an insufficient and unpredictable number of sparse depth measurements of hardware sensors. However, existing research on depth completion assumes that the sparsity -- the number of points or LiDAR lines -- is fixed for training and testing. Hence, the completion performance drops severely when the number of sparse depths changes significantly. To address this issue, we propose the sparsity-adaptive depth refinement (SDR) framework, which refines monocular depth estimates using sparse depth points. For SDR, we propose the masked spatial propagation network (MSPN) to perform SDR with a varying number of sparse depths effectively by gradually propagating sparse depth information throughout the entire depth map. Experimental results demonstrate that MPSN achieves state-of-the-art performance on both SDR and conventional depth completion scenarios.
Clicks2Line: Using Lines for Interactive Image Segmentation
Apr 29, 2024For click-based interactive segmentation methods, reducing the number of clicks required to obtain a desired segmentation result is essential. Although recent click-based methods yield decent segmentation results, we observe that substantial amount of clicks are required to segment elongated regions. To reduce the amount of user-effort required, we propose using lines instead of clicks for such cases. In this paper, an interactive segmentation algorithm which adaptively adopts either clicks or lines as input is proposed. Experimental results demonstrate that using lines can generate better segmentation results than clicks for several cases.
MFP: Making Full Use of Probability Maps for Interactive Image Segmentation
Apr 29, 2024In recent interactive segmentation algorithms, previous probability maps are used as network input to help predictions in the current segmentation round. However, despite the utilization of previous masks, useful information contained in the probability maps is not well propagated to the current predictions. In this paper, to overcome this limitation, we propose a novel and effective algorithm for click-based interactive image segmentation, called MFP, which attempts to make full use of probability maps. We first modulate previous probability maps to enhance their representations of user-specified objects. Then, we feed the modulated probability maps as additional input to the segmentation network. We implement the proposed MFP algorithm based on the ResNet-34, HRNet-18, and ViT-B backbones and assess the performance extensively on various datasets. It is demonstrated that MFP meaningfully outperforms the existing algorithms using identical backbones. The source codes are available at \href{https://github.com/cwlee00/MFP}{https://github.com/cwlee00/MFP}.
Recursive Video Lane Detection
Aug 22, 2023A novel algorithm to detect road lanes in videos, called recursive video lane detector (RVLD), is proposed in this paper, which propagates the state of a current frame recursively to the next frame. RVLD consists of an intra-frame lane detector (ILD) and a predictive lane detector (PLD). First, we design ILD to localize lanes in a still frame. Second, we develop PLD to exploit the information of the previous frame for lane detection in a current frame. To this end, we estimate a motion field and warp the previous output to the current frame. Using the warped information, we refine the feature map of the current frame to detect lanes more reliably. Experimental results show that RVLD outperforms existing detectors on video lane datasets. Our codes are available at https://github.com/dongkwonjin/RVLD.