 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen Ko-LLM Leaderboard2: Bridging Foundational and Practical Evaluation for Korean LLMs
Oct 16, 2024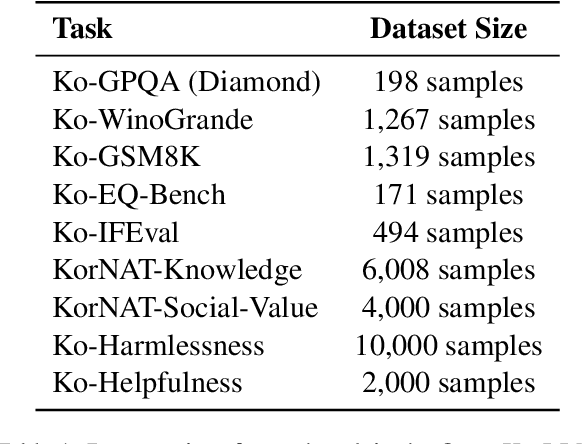
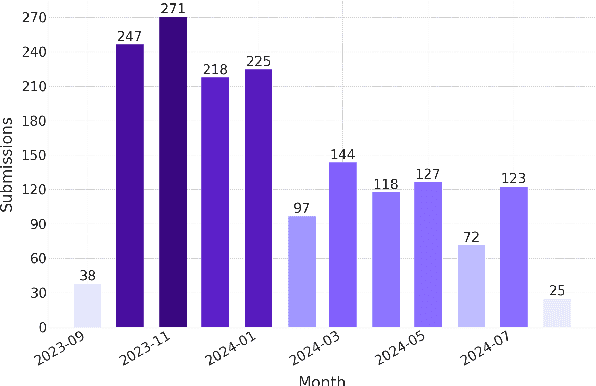
The Open Ko-LLM Leaderboard has been instrumental in benchmarking Korean Large Language Models (LLMs), yet it has certain limitations. Notably, the disconnect between quantitative improvements on the overly academic leaderboard benchmarks and the qualitative impact of the models should be addressed. Furthermore, the benchmark suite is largely composed of translated versions of their English counterparts, which may not fully capture the intricacies of the Korean language. To address these issues, we propose Open Ko-LLM Leaderboard2, an improved version of the earlier Open Ko-LLM Leaderboard. The original benchmarks are entirely replaced with new tasks that are more closely aligned with real-world capabilities. Additionally, four new native Korean benchmarks are introduced to better reflect the distinct characteristics of the Korean language. Through these refinements, Open Ko-LLM Leaderboard2 seeks to provide a more meaningful evaluation for advancing Korean LLMs.
Representing the Under-Represented: Cultural and Core Capability Benchmarks for Developing Thai Large Language Models
Oct 07, 2024



The rapid advancement of large language models (LLMs) has highlighted the need for robust evaluation frameworks that assess their core capabilities, such as reasoning, knowledge, and commonsense, leading to the inception of certain widely-used benchmark suites such as the H6 benchmark. However, these benchmark suites are primarily built for the English language, and there exists a lack thereof for under-represented languages, in terms of LLM development, such as Thai. On the other hand, developing LLMs for Thai should also include enhancing the cultural understanding as well as core capabilities. To address these dual challenge in Thai LLM research, we propose two key benchmarks: Thai-H6 and Thai Cultural and Linguistic Intelligence Benchmark (ThaiCLI). Through a thorough evaluation of various LLMs with multi-lingual capabilities, we provide a comprehensive analysis of the proposed benchmarks and how they contribute to Thai LLM development. Furthermore, we will make both the datasets and evaluation code publicly available to encourage further research and development for Thai LLMs.
1 Trillion Token (1TT) Platform: A Novel Framework for Efficient Data Sharing and Compensation in Large Language Models
Sep 30, 2024

In this paper, we propose the 1 Trillion Token Platform (1TT Platform), a novel framework designed to facilitate efficient data sharing with a transparent and equitable profit-sharing mechanism. The platform fosters collaboration between data contributors, who provide otherwise non-disclosed datasets, and a data consumer, who utilizes these datasets to enhance their own services. Data contributors are compensated in monetary terms, receiving a share of the revenue generated by the services of the data consumer. The data consumer is committed to sharing a portion of the revenue with contributors, according to predefined profit-sharing arrangements. By incorporating a transparent profit-sharing paradigm to incentivize large-scale data sharing, the 1TT Platform creates a collaborative environment to drive the advancement of NLP and LLM technologies.
Open Ko-LLM Leaderboard: Evaluating Large Language Models in Korean with Ko-H5 Benchmark
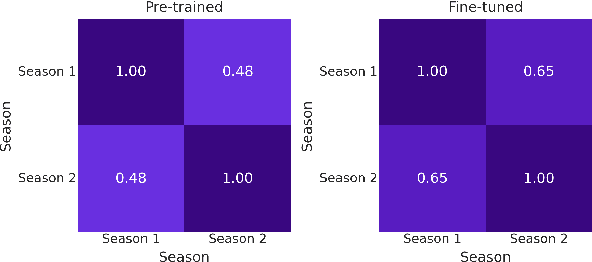
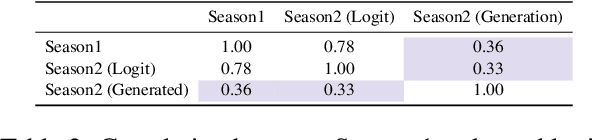
May 31, 2024This paper introduces the Open Ko-LLM Leaderboard and the Ko-H5 Benchmark as vital tools for evaluating Large Language Models (LLMs) in Korean. Incorporating private test sets while mirroring the English Open LLM Leaderboard, we establish a robust evaluation framework that has been well integrated in the Korean LLM community. We perform data leakage analysis that shows the benefit of private test sets along with a correlation study within the Ko-H5 benchmark and temporal analyses of the Ko-H5 score. Moreover, we present empirical support for the need to expand beyond set benchmarks. We hope the Open Ko-LLM Leaderboard sets precedent for expanding LLM evaluation to foster more linguistic diversity.
Evalverse: Unified and Accessible Library for Large Language Model Evaluation
Apr 01, 2024
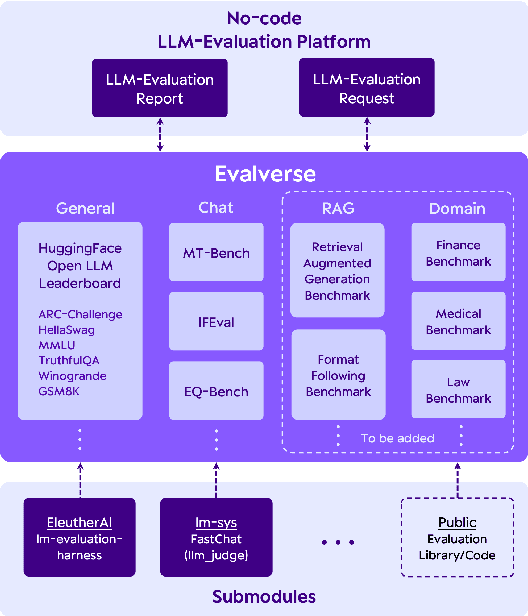
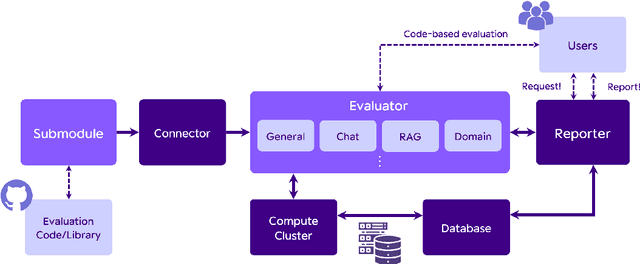
This paper introduces Evalverse, a novel library that streamlines the evaluation of Large Language Models (LLMs) by unifying disparate evaluation tools into a single, user-friendly framework. Evalverse enables individuals with limited knowledge of artificial intelligence to easily request LLM evaluations and receive detailed reports, facilitated by an integration with communication platforms like Slack. Thus, Evalverse serves as a powerful tool for the comprehensive assessment of LLMs, offering both researchers and practitioners a centralized and easily accessible evaluation framework. Finally, we also provide a demo video for Evalverse, showcasing its capabilities and implementation in a two-minute format.
Long-Tailed Recognition on Binary Networks by Calibrating A Pre-trained Model
Mar 30, 2024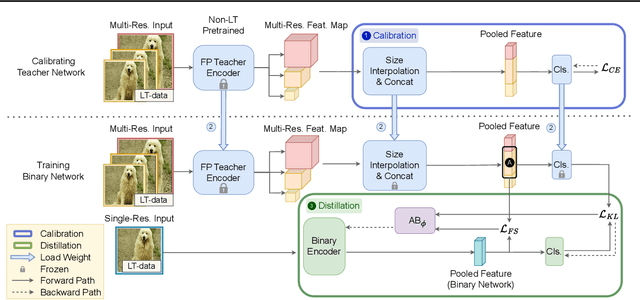
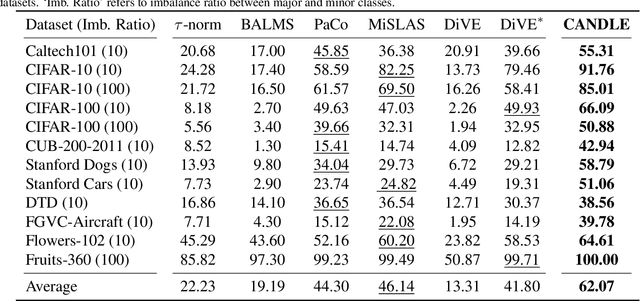
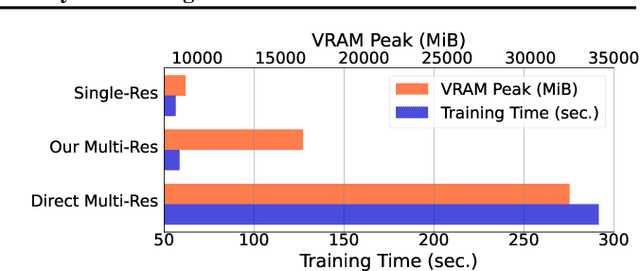

Deploying deep models in real-world scenarios entails a number of challenges, including computational efficiency and real-world (e.g., long-tailed) data distributions. We address the combined challenge of learning long-tailed distributions using highly resource-efficient binary neural networks as backbones. Specifically, we propose a calibrate-and-distill framework that uses off-the-shelf pretrained full-precision models trained on balanced datasets to use as teachers for distillation when learning binary networks on long-tailed datasets. To better generalize to various datasets, we further propose a novel adversarial balancing among the terms in the objective function and an efficient multiresolution learning scheme. We conducted the largest empirical study in the literature using 15 datasets, including newly derived long-tailed datasets from existing balanced datasets, and show that our proposed method outperforms prior art by large margins (>14.33% on average).
Dataverse: Open-Source ETL Pipeline for Large Language Models
Mar 28, 2024To address the challenges associated with data processing at scale, we propose Dataverse, a unified open-source Extract-Transform-Load (ETL) pipeline for large language models (LLMs) with a user-friendly design at its core. Easy addition of custom processors with block-based interface in Dataverse allows users to readily and efficiently use Dataverse to build their own ETL pipeline. We hope that Dataverse will serve as a vital tool for LLM development and open source the entire library to welcome community contribution. Additionally, we provide a concise, two-minute video demonstration of our system, illustrating its capabilities and implementation.
sDPO: Don't Use Your Data All at Once
Mar 28, 2024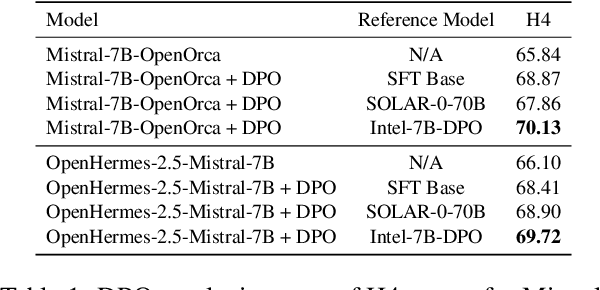
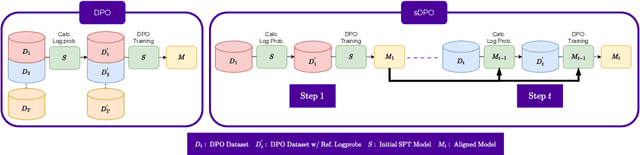
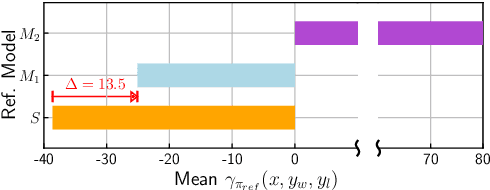
As development of large language models (LLM) progresses, aligning them with human preferences has become increasingly important. We propose stepwise DPO (sDPO), an extension of the recently popularized direct preference optimization (DPO) for alignment tuning. This approach involves dividing the available preference datasets and utilizing them in a stepwise manner, rather than employing it all at once. We demonstrate that this method facilitates the use of more precisely aligned reference models within the DPO training framework. Furthermore, sDPO trains the final model to be more performant, even outperforming other popular LLMs with more parameters.
Model-Based Data-Centric AI: Bridging the Divide Between Academic Ideals and Industrial Pragmatism
Mar 04, 2024This paper delves into the contrasting roles of data within academic and industrial spheres, highlighting the divergence between Data-Centric AI and Model-Agnostic AI approaches. We argue that while Data-Centric AI focuses on the primacy of high-quality data for model performance, Model-Agnostic AI prioritizes algorithmic flexibility, often at the expense of data quality considerations. This distinction reveals that academic standards for data quality frequently do not meet the rigorous demands of industrial applications, leading to potential pitfalls in deploying academic models in real-world settings. Through a comprehensive analysis, we address these disparities, presenting both the challenges they pose and strategies for bridging the gap. Furthermore, we propose a novel paradigm: Model-Based Data-Centric AI, which aims to reconcile these differences by integrating model considerations into data optimization processes. This approach underscores the necessity for evolving data requirements that are sensitive to the nuances of both academic research and industrial deployment. By exploring these discrepancies, we aim to foster a more nuanced understanding of data's role in AI development and encourage a convergence of academic and industrial standards to enhance AI's real-world applicability.
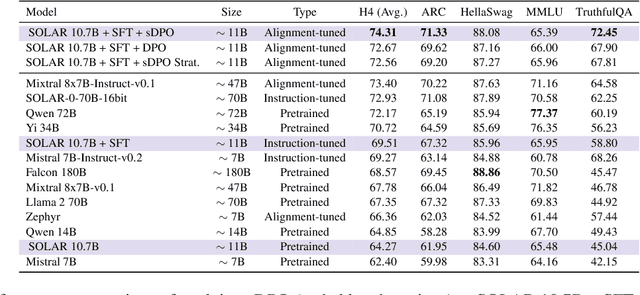
SOLAR 10.7B: Scaling Large Language Models with Simple yet Effective Depth Up-Scaling
Dec 29, 2023



We introduce SOLAR 10.7B, a large language model (LLM) with 10.7 billion parameters, demonstrating superior performance in various natural language processing (NLP) tasks. Inspired by recent efforts to efficiently up-scale LLMs, we present a method for scaling LLMs called depth up-scaling (DUS), which encompasses depthwise scaling and continued pretraining. In contrast to other LLM up-scaling methods that use mixture-of-experts, DUS does not require complex changes to train and inference efficiently. We show experimentally that DUS is simple yet effective in scaling up high-performance LLMs from small ones. Building on the DUS model, we additionally present SOLAR 10.7B-Instruct, a variant fine-tuned for instruction-following capabilities, surpassing Mixtral-8x7B-Instruct. SOLAR 10.7B is publicly available under the Apache 2.0 license, promoting broad access and application in the LLM field.