 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSOLAR 10.7B: Scaling Large Language Models with Simple yet Effective Depth Up-Scaling
Dec 29, 2023



We introduce SOLAR 10.7B, a large language model (LLM) with 10.7 billion parameters, demonstrating superior performance in various natural language processing (NLP) tasks. Inspired by recent efforts to efficiently up-scale LLMs, we present a method for scaling LLMs called depth up-scaling (DUS), which encompasses depthwise scaling and continued pretraining. In contrast to other LLM up-scaling methods that use mixture-of-experts, DUS does not require complex changes to train and inference efficiently. We show experimentally that DUS is simple yet effective in scaling up high-performance LLMs from small ones. Building on the DUS model, we additionally present SOLAR 10.7B-Instruct, a variant fine-tuned for instruction-following capabilities, surpassing Mixtral-8x7B-Instruct. SOLAR 10.7B is publicly available under the Apache 2.0 license, promoting broad access and application in the LLM field.
Lightweight Boosting Models for User Response Prediction Using Adversarial Validation
Oct 05, 2023The ACM RecSys Challenge 2023, organized by ShareChat, aims to predict the probability of the app being installed. This paper describes the lightweight solution to this challenge. We formulate the task as a user response prediction task. For rapid prototyping for the task, we propose a lightweight solution including the following steps: 1) using adversarial validation, we effectively eliminate uninformative features from a dataset; 2) to address noisy continuous features and categorical features with a large number of unique values, we employ feature engineering techniques.; 3) we leverage Gradient Boosted Decision Trees (GBDT) for their exceptional performance and scalability. The experiments show that a single LightGBM model, without additional ensembling, performs quite well. Our team achieved ninth place in the challenge with the final leaderboard score of 6.059065. Code for our approach can be found here: https://github.com/choco9966/recsys-challenge-2023.
Neural Ideal Point Estimation Network
Apr 26, 2019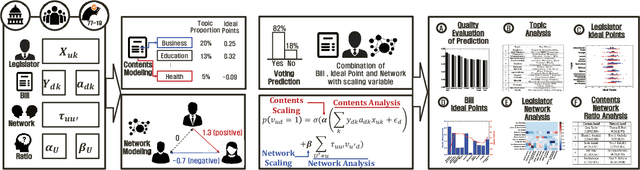

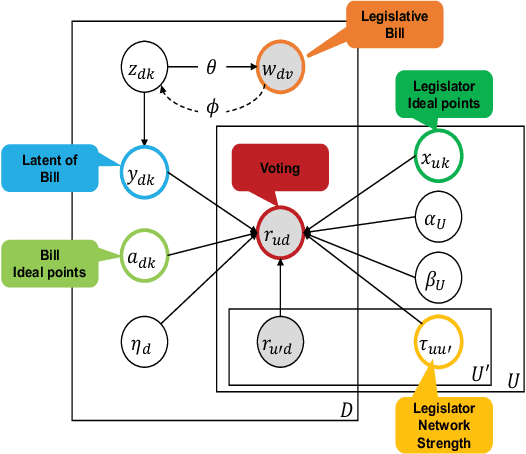
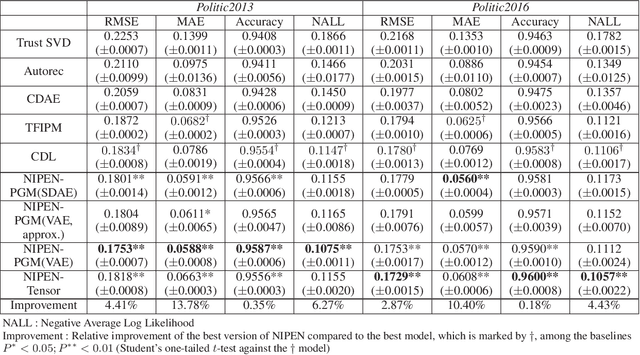
Understanding politics is challenging because the politics take the influence from everything. Even we limit ourselves to the political context in the legislative processes; we need a better understanding of latent factors, such as legislators, bills, their ideal points, and their relations. From the modeling perspective, this is difficult 1) because these observations lie in a high dimension that requires learning on low dimensional representations, and 2) because these observations require complex probabilistic modeling with latent variables to reflect the causalities. This paper presents a new model to reflect and understand this political setting, NIPEN, including factors mentioned above in the legislation. We propose two versions of NIPEN: one is a hybrid model of deep learning and probabilistic graphical model, and the other model is a neural tensor model. Our result indicates that NIPEN successfully learns the manifold of the legislative bill texts, and NIPEN utilizes the learned low-dimensional latent variables to increase the prediction performance of legislators' votings. Additionally, by virtue of being a domain-rich probabilistic model, NIPEN shows the hidden strength of the legislators' trust network and their various characteristics on casting votes.
Adversarial Dropout for Recurrent Neural Networks
Apr 22, 2019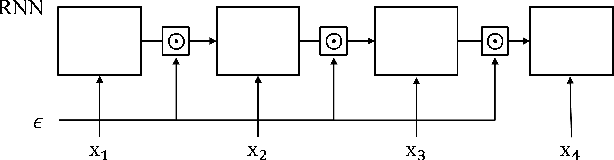

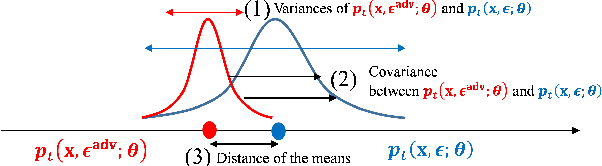

Successful application processing sequential data, such as text and speech, requires an improved generalization performance of recurrent neural networks (RNNs). Dropout techniques for RNNs were introduced to respond to these demands, but we conjecture that the dropout on RNNs could have been improved by adopting the adversarial concept. This paper investigates ways to improve the dropout for RNNs by utilizing intentionally generated dropout masks. Specifically, the guided dropout used in this research is called as adversarial dropout, which adversarially disconnects neurons that are dominantly used to predict correct targets over time. Our analysis showed that our regularizer, which consists of a gap between the original and the reconfigured RNNs, was the upper bound of the gap between the training and the inference phases of the random dropout. We demonstrated that minimizing our regularizer improved the effectiveness of the dropout for RNNs on sequential MNIST tasks, semi-supervised text classification tasks, and language modeling tasks.
Dirichlet Variational Autoencoder
Jan 09, 2019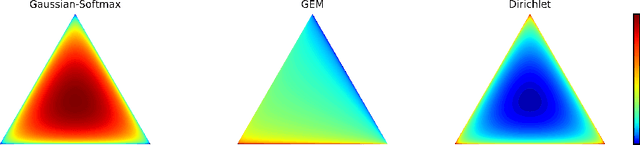
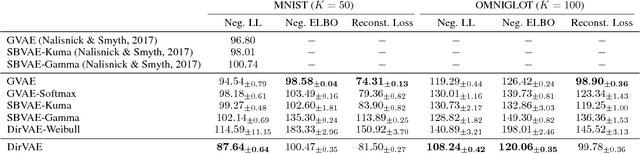
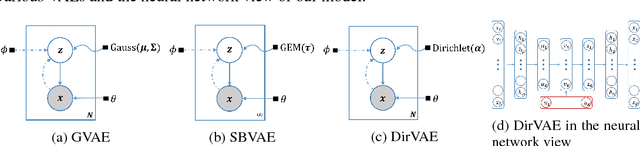

This paper proposes Dirichlet Variational Autoencoder (DirVAE) using a Dirichlet prior for a continuous latent variable that exhibits the characteristic of the categorical probabilities. To infer the parameters of DirVAE, we utilize the stochastic gradient method by approximating the Gamma distribution, which is a component of the Dirichlet distribution, with the inverse Gamma CDF approximation. Additionally, we reshape the component collapsing issue by investigating two problem sources, which are decoder weight collapsing and latent value collapsing, and we show that DirVAE has no component collapsing; while Gaussian VAE exhibits the decoder weight collapsing and Stick-Breaking VAE shows the latent value collapsing. The experimental results show that 1) DirVAE models the latent representation result with the best log-likelihood compared to the baselines; and 2) DirVAE produces more interpretable latent values with no collapsing issues which the baseline models suffer from. Also, we show that the learned latent representation from the DirVAE achieves the best classification accuracy in the semi-supervised and the supervised classification tasks on MNIST, OMNIGLOT, and SVHN compared to the baseline VAEs. Finally, we demonstrated that the DirVAE augmented topic models show better performances in most cases.