 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning 3D Object Spatial Relationships from Pre-trained 2D Diffusion Models
Mar 25, 2025



We present a method for learning 3D spatial relationships between object pairs, referred to as object-object spatial relationships (OOR), by leveraging synthetically generated 3D samples from pre-trained 2D diffusion models. We hypothesize that images synthesized by 2D diffusion models inherently capture plausible and realistic OOR cues, enabling efficient ways to collect a 3D dataset to learn OOR for various unbounded object categories. Our approach begins by synthesizing diverse images that capture plausible OOR cues, which we then uplift into 3D samples. Leveraging our diverse collection of plausible 3D samples for the object pairs, we train a score-based OOR diffusion model to learn the distribution of their relative spatial relationships. Additionally, we extend our pairwise OOR to multi-object OOR by enforcing consistency across pairwise relations and preventing object collisions. Extensive experiments demonstrate the robustness of our method across various object-object spatial relationships, along with its applicability to real-world 3D scene arrangement tasks using the OOR diffusion model.
DAViD: Modeling Dynamic Affordance of 3D Objects using Pre-trained Video Diffusion Models
Jan 14, 2025



Understanding the ability of humans to use objects is crucial for AI to improve daily life. Existing studies for learning such ability focus on human-object patterns (e.g., contact, spatial relation, orientation) in static situations, and learning Human-Object Interaction (HOI) patterns over time (i.e., movement of human and object) is relatively less explored. In this paper, we introduce a novel type of affordance named Dynamic Affordance. For a given input 3D object mesh, we learn dynamic affordance which models the distribution of both (1) human motion and (2) human-guided object pose during interactions. As a core idea, we present a method to learn the 3D dynamic affordance from synthetically generated 2D videos, leveraging a pre-trained video diffusion model. Specifically, we propose a pipeline that first generates 2D HOI videos from the 3D object and then lifts them into 3D to generate 4D HOI samples. Once we generate diverse 4D HOI samples on various target objects, we train our DAViD, where we present a method based on the Low-Rank Adaptation (LoRA) module for pre-trained human motion diffusion model (MDM) and an object pose diffusion model with human pose guidance. Our motion diffusion model is extended for multi-object interactions, demonstrating the advantage of our pipeline with LoRA for combining the concepts of object usage. Through extensive experiments, we demonstrate our DAViD outperforms the baselines in generating human motion with HOIs.
Open Ko-LLM Leaderboard2: Bridging Foundational and Practical Evaluation for Korean LLMs
Oct 16, 2024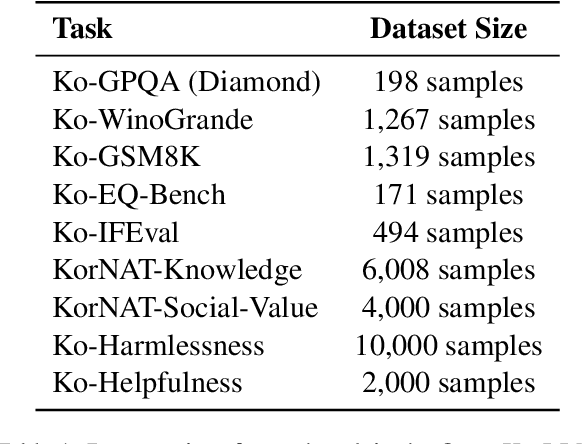
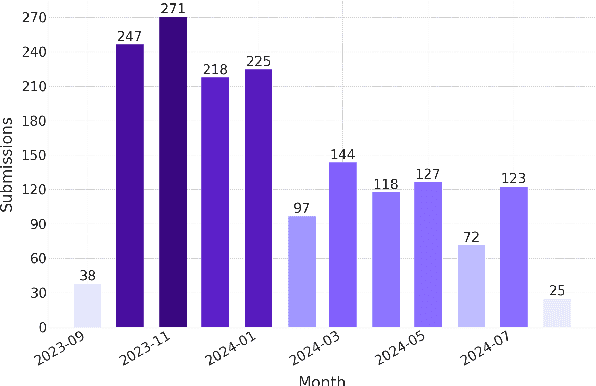
The Open Ko-LLM Leaderboard has been instrumental in benchmarking Korean Large Language Models (LLMs), yet it has certain limitations. Notably, the disconnect between quantitative improvements on the overly academic leaderboard benchmarks and the qualitative impact of the models should be addressed. Furthermore, the benchmark suite is largely composed of translated versions of their English counterparts, which may not fully capture the intricacies of the Korean language. To address these issues, we propose Open Ko-LLM Leaderboard2, an improved version of the earlier Open Ko-LLM Leaderboard. The original benchmarks are entirely replaced with new tasks that are more closely aligned with real-world capabilities. Additionally, four new native Korean benchmarks are introduced to better reflect the distinct characteristics of the Korean language. Through these refinements, Open Ko-LLM Leaderboard2 seeks to provide a more meaningful evaluation for advancing Korean LLMs.
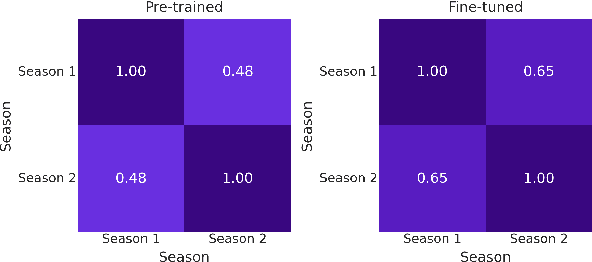
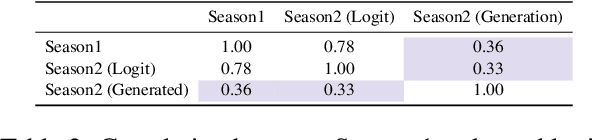
Understanding LLM Development Through Longitudinal Study: Insights from the Open Ko-LLM Leaderboard
Sep 05, 2024This paper conducts a longitudinal study over eleven months to address the limitations of prior research on the Open Ko-LLM Leaderboard, which have relied on empirical studies with restricted observation periods of only five months. By extending the analysis duration, we aim to provide a more comprehensive understanding of the progression in developing Korean large language models (LLMs). Our study is guided by three primary research questions: (1) What are the specific challenges in improving LLM performance across diverse tasks on the Open Ko-LLM Leaderboard over time? (2) How does model size impact task performance correlations across various benchmarks? (3) How have the patterns in leaderboard rankings shifted over time on the Open Ko-LLM Leaderboard?. By analyzing 1,769 models over this period, our research offers a comprehensive examination of the ongoing advancements in LLMs and the evolving nature of evaluation frameworks.
Open Ko-LLM Leaderboard: Evaluating Large Language Models in Korean with Ko-H5 Benchmark
May 31, 2024This paper introduces the Open Ko-LLM Leaderboard and the Ko-H5 Benchmark as vital tools for evaluating Large Language Models (LLMs) in Korean. Incorporating private test sets while mirroring the English Open LLM Leaderboard, we establish a robust evaluation framework that has been well integrated in the Korean LLM community. We perform data leakage analysis that shows the benefit of private test sets along with a correlation study within the Ko-H5 benchmark and temporal analyses of the Ko-H5 score. Moreover, we present empirical support for the need to expand beyond set benchmarks. We hope the Open Ko-LLM Leaderboard sets precedent for expanding LLM evaluation to foster more linguistic diversity.
SAAS: Solving Ability Amplification Strategy for Enhanced Mathematical Reasoning in Large Language Models
Apr 08, 2024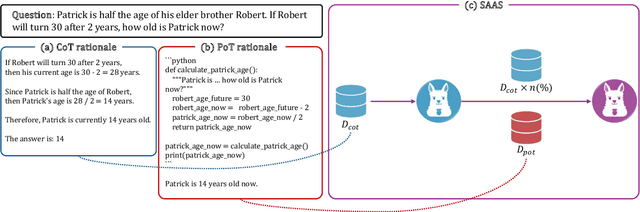

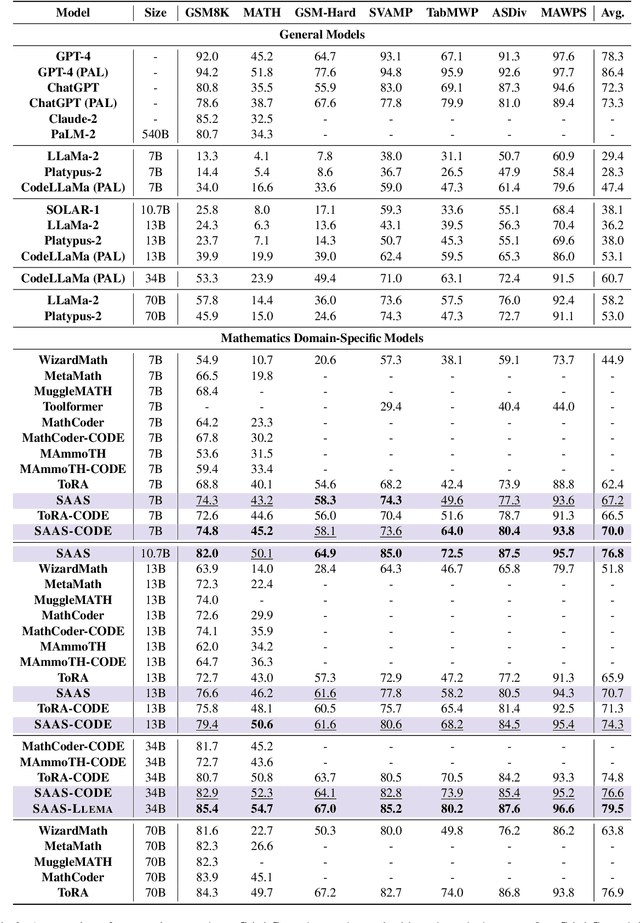
This study presents a novel learning approach designed to enhance both mathematical reasoning and problem-solving abilities of Large Language Models (LLMs). We focus on integrating the Chain-of-Thought (CoT) and the Program-of-Thought (PoT) learning, hypothesizing that prioritizing the learning of mathematical reasoning ability is helpful for the amplification of problem-solving ability. Thus, the initial learning with CoT is essential for solving challenging mathematical problems. To this end, we propose a sequential learning approach, named SAAS (Solving Ability Amplification Strategy), which strategically transitions from CoT learning to PoT learning. Our empirical study, involving an extensive performance comparison using several benchmarks, demonstrates that our SAAS achieves state-of-the-art (SOTA) performance. The results underscore the effectiveness of our sequential learning approach, marking a significant advancement in the field of mathematical reasoning in LLMs.
sDPO: Don't Use Your Data All at Once
Mar 28, 2024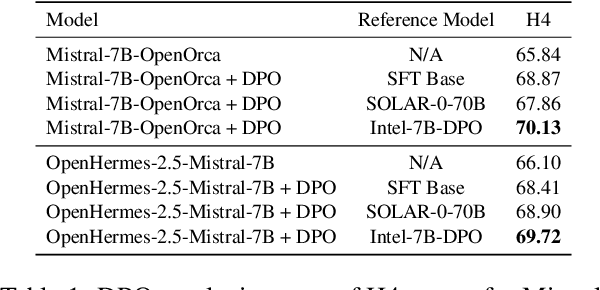
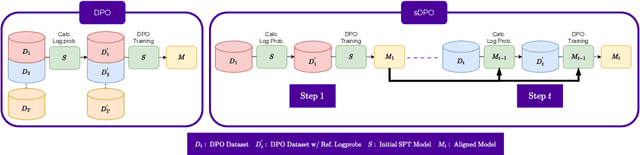
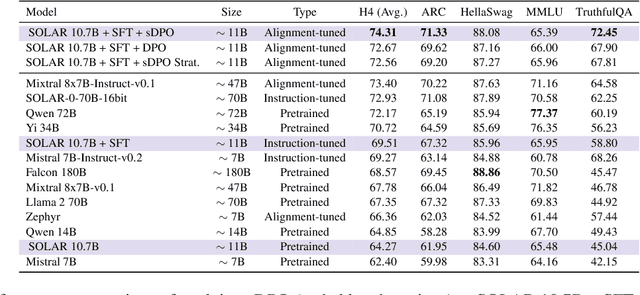
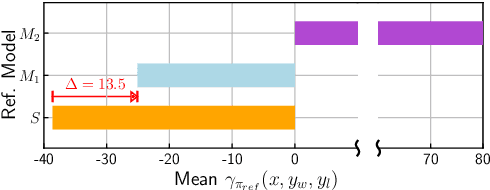
As development of large language models (LLM) progresses, aligning them with human preferences has become increasingly important. We propose stepwise DPO (sDPO), an extension of the recently popularized direct preference optimization (DPO) for alignment tuning. This approach involves dividing the available preference datasets and utilizing them in a stepwise manner, rather than employing it all at once. We demonstrate that this method facilitates the use of more precisely aligned reference models within the DPO training framework. Furthermore, sDPO trains the final model to be more performant, even outperforming other popular LLMs with more parameters.
Zero-Shot Learning for the Primitives of 3D Affordance in General Objects
Jan 24, 2024



One of the major challenges in AI is teaching machines to precisely respond and utilize environmental functionalities, thereby achieving the affordance awareness that humans possess. Despite its importance, the field has been lagging in terms of learning, especially in 3D, as annotating affordance accompanies a laborious process due to the numerous variations of human-object interaction. The low availability of affordance data limits the learning in terms of generalization for object categories, and also simplifies the representation of affordance, capturing only a fraction of the affordance. To overcome these challenges, we propose a novel, self-supervised method to generate the 3D affordance examples given only a 3D object, without any manual annotations. The method starts by capturing the 3D object into images and creating 2D affordance images by inserting humans into the image via inpainting diffusion models, where we present the Adaptive Mask algorithm to enable human insertion without altering the original details of the object. The method consequently lifts inserted humans back to 3D to create 3D human-object pairs, where the depth ambiguity is resolved within a depth optimization framework that utilizes pre-generated human postures from multiple viewpoints. We also provide a novel affordance representation defined on relative orientations and proximity between dense human and object points, that can be easily aggregated from any 3D HOI datasets. The proposed representation serves as a primitive that can be manifested to conventional affordance representations via simple transformations, ranging from physically exerted affordances to nonphysical ones. We demonstrate the efficacy of our method and representation by generating the 3D affordance samples and deriving high-quality affordance examples from the representation, including contact, orientation, and spatial occupancies.
SOLAR 10.7B: Scaling Large Language Models with Simple yet Effective Depth Up-Scaling
Dec 29, 2023



We introduce SOLAR 10.7B, a large language model (LLM) with 10.7 billion parameters, demonstrating superior performance in various natural language processing (NLP) tasks. Inspired by recent efforts to efficiently up-scale LLMs, we present a method for scaling LLMs called depth up-scaling (DUS), which encompasses depthwise scaling and continued pretraining. In contrast to other LLM up-scaling methods that use mixture-of-experts, DUS does not require complex changes to train and inference efficiently. We show experimentally that DUS is simple yet effective in scaling up high-performance LLMs from small ones. Building on the DUS model, we additionally present SOLAR 10.7B-Instruct, a variant fine-tuned for instruction-following capabilities, surpassing Mixtral-8x7B-Instruct. SOLAR 10.7B is publicly available under the Apache 2.0 license, promoting broad access and application in the LLM field.
Lightweight Boosting Models for User Response Prediction Using Adversarial Validation
Oct 05, 2023The ACM RecSys Challenge 2023, organized by ShareChat, aims to predict the probability of the app being installed. This paper describes the lightweight solution to this challenge. We formulate the task as a user response prediction task. For rapid prototyping for the task, we propose a lightweight solution including the following steps: 1) using adversarial validation, we effectively eliminate uninformative features from a dataset; 2) to address noisy continuous features and categorical features with a large number of unique values, we employ feature engineering techniques.; 3) we leverage Gradient Boosted Decision Trees (GBDT) for their exceptional performance and scalability. The experiments show that a single LightGBM model, without additional ensembling, performs quite well. Our team achieved ninth place in the challenge with the final leaderboard score of 6.059065. Code for our approach can be found here: https://github.com/choco9966/recsys-challenge-2023.