 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen Ko-LLM Leaderboard2: Bridging Foundational and Practical Evaluation for Korean LLMs
Paper and Code
Oct 16, 2024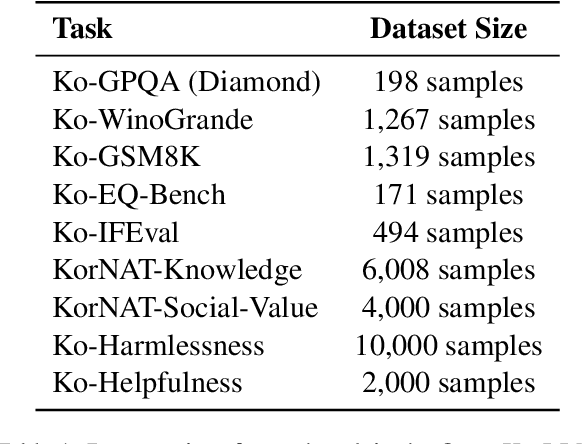
The Open Ko-LLM Leaderboard has been instrumental in benchmarking Korean Large Language Models (LLMs), yet it has certain limitations. Notably, the disconnect between quantitative improvements on the overly academic leaderboard benchmarks and the qualitative impact of the models should be addressed. Furthermore, the benchmark suite is largely composed of translated versions of their English counterparts, which may not fully capture the intricacies of the Korean language. To address these issues, we propose Open Ko-LLM Leaderboard2, an improved version of the earlier Open Ko-LLM Leaderboard. The original benchmarks are entirely replaced with new tasks that are more closely aligned with real-world capabilities. Additionally, four new native Korean benchmarks are introduced to better reflect the distinct characteristics of the Korean language. Through these refinements, Open Ko-LLM Leaderboard2 seeks to provide a more meaningful evaluation for advancing Korean LLMs.