 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLP Data Pipeline: Lightweight, Purpose-driven Data Pipeline for Large Language Models
Nov 18, 2024Creating high-quality, large-scale datasets for large language models (LLMs) often relies on resource-intensive, GPU-accelerated models for quality filtering, making the process time-consuming and costly. This dependence on GPUs limits accessibility for organizations lacking significant computational infrastructure. To address this issue, we introduce the Lightweight, Purpose-driven (LP) Data Pipeline, a framework that operates entirely on CPUs to streamline the processes of dataset extraction, filtering, and curation. Based on our four core principles, the LP Data Pipeline significantly reduces preparation time and cost while maintaining high data quality. Importantly, our pipeline enables the creation of purpose-driven datasets tailored to specific domains and languages, enhancing the applicability of LLMs in specialized contexts. We anticipate that our pipeline will lower the barriers to LLM development, enabling a wide range of organizations to access LLMs more easily.
Open Ko-LLM Leaderboard2: Bridging Foundational and Practical Evaluation for Korean LLMs
Oct 16, 2024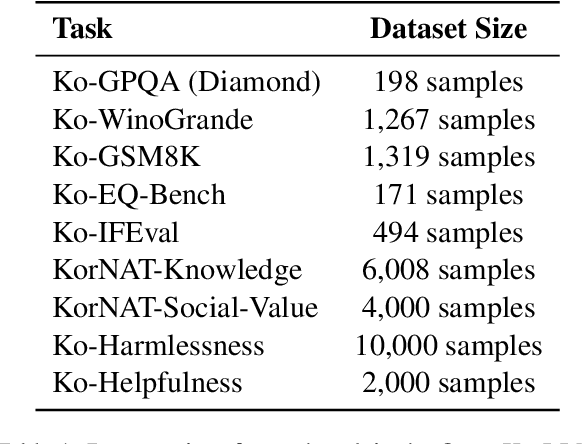
The Open Ko-LLM Leaderboard has been instrumental in benchmarking Korean Large Language Models (LLMs), yet it has certain limitations. Notably, the disconnect between quantitative improvements on the overly academic leaderboard benchmarks and the qualitative impact of the models should be addressed. Furthermore, the benchmark suite is largely composed of translated versions of their English counterparts, which may not fully capture the intricacies of the Korean language. To address these issues, we propose Open Ko-LLM Leaderboard2, an improved version of the earlier Open Ko-LLM Leaderboard. The original benchmarks are entirely replaced with new tasks that are more closely aligned with real-world capabilities. Additionally, four new native Korean benchmarks are introduced to better reflect the distinct characteristics of the Korean language. Through these refinements, Open Ko-LLM Leaderboard2 seeks to provide a more meaningful evaluation for advancing Korean LLMs.
1 Trillion Token (1TT) Platform: A Novel Framework for Efficient Data Sharing and Compensation in Large Language Models
Sep 30, 2024

In this paper, we propose the 1 Trillion Token Platform (1TT Platform), a novel framework designed to facilitate efficient data sharing with a transparent and equitable profit-sharing mechanism. The platform fosters collaboration between data contributors, who provide otherwise non-disclosed datasets, and a data consumer, who utilizes these datasets to enhance their own services. Data contributors are compensated in monetary terms, receiving a share of the revenue generated by the services of the data consumer. The data consumer is committed to sharing a portion of the revenue with contributors, according to predefined profit-sharing arrangements. By incorporating a transparent profit-sharing paradigm to incentivize large-scale data sharing, the 1TT Platform creates a collaborative environment to drive the advancement of NLP and LLM technologies.
Rethinking KenLM: Good and Bad Model Ensembles for Efficient Text Quality Filtering in Large Web Corpora
Sep 15, 2024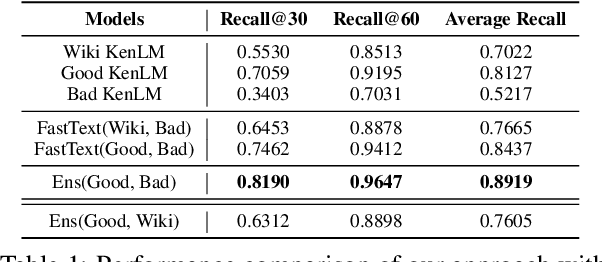
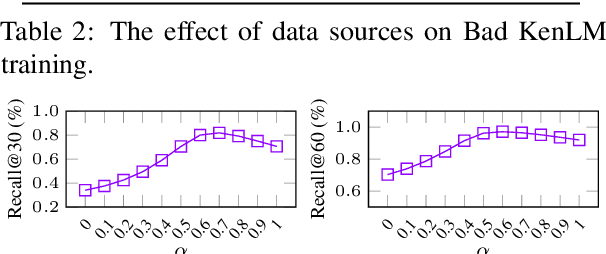
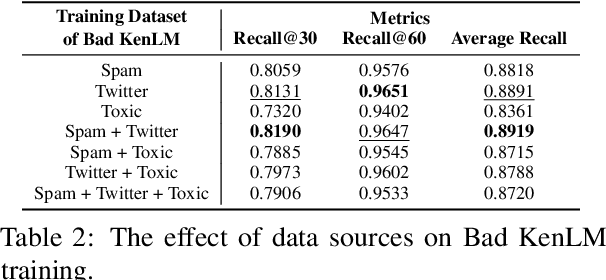

With the increasing demand for substantial amounts of high-quality data to train large language models (LLMs), efficiently filtering large web corpora has become a critical challenge. For this purpose, KenLM, a lightweight n-gram-based language model that operates on CPUs, is widely used. However, the traditional method of training KenLM utilizes only high-quality data and, consequently, does not explicitly learn the linguistic patterns of low-quality data. To address this issue, we propose an ensemble approach that leverages two contrasting KenLMs: (i) Good KenLM, trained on high-quality data; and (ii) Bad KenLM, trained on low-quality data. Experimental results demonstrate that our approach significantly reduces noisy content while preserving high-quality content compared to the traditional KenLM training method. This indicates that our method can be a practical solution with minimal computational overhead for resource-constrained environments.
Turbulence Strength $C_n^2$ Estimation from Video using Physics-based Deep Learning
Aug 29, 2024



Images captured from a long distance suffer from dynamic image distortion due to turbulent flow of air cells with random temperatures, and thus refractive indices. This phenomenon, known as image dancing, is commonly characterized by its refractive-index structure constant $C_n^2$ as a measure of the turbulence strength. For many applications such as atmospheric forecast model, long-range/astronomy imaging, and aviation safety, optical communication technology, $C_n^2$ estimation is critical for accurately sensing the turbulent environment. Previous methods for $C_n^2$ estimation include estimation from meteorological data (temperature, relative humidity, wind shear, etc.) for single-point measurements, two-ended pathlength measurements from optical scintillometer for path-averaged $C_n^2$, and more recently estimating $C_n^2$ from passive video cameras for low cost and hardware complexity. In this paper, we present a comparative analysis of classical image gradient methods for $C_n^2$ estimation and modern deep learning-based methods leveraging convolutional neural networks. To enable this, we collect a dataset of video capture along with reference scintillometer measurements for ground truth, and we release this unique dataset to the scientific community. We observe that deep learning methods can achieve higher accuracy when trained on similar data, but suffer from generalization errors to other, unseen imagery as compared to classical methods. To overcome this trade-off, we present a novel physics-based network architecture that combines learned convolutional layers with a differentiable image gradient method that maintains high accuracy while being generalizable across image datasets.
* Code Available: https://github.com/Riponcs/Cn2Estimation
SAAS: Solving Ability Amplification Strategy for Enhanced Mathematical Reasoning in Large Language Models
Apr 08, 2024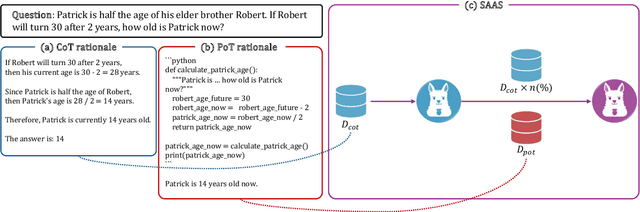
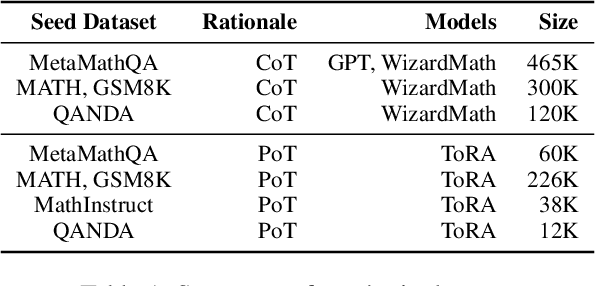

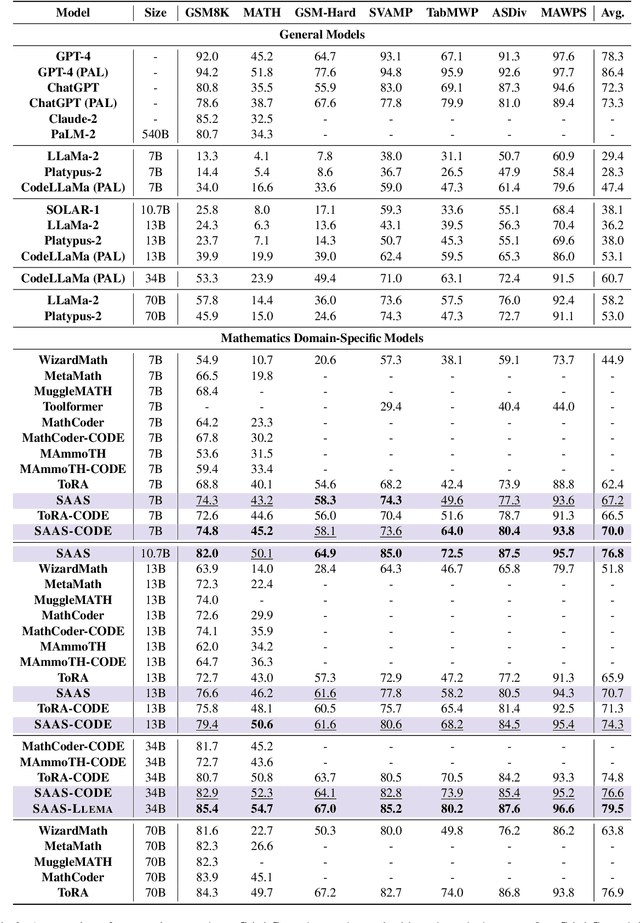
This study presents a novel learning approach designed to enhance both mathematical reasoning and problem-solving abilities of Large Language Models (LLMs). We focus on integrating the Chain-of-Thought (CoT) and the Program-of-Thought (PoT) learning, hypothesizing that prioritizing the learning of mathematical reasoning ability is helpful for the amplification of problem-solving ability. Thus, the initial learning with CoT is essential for solving challenging mathematical problems. To this end, we propose a sequential learning approach, named SAAS (Solving Ability Amplification Strategy), which strategically transitions from CoT learning to PoT learning. Our empirical study, involving an extensive performance comparison using several benchmarks, demonstrates that our SAAS achieves state-of-the-art (SOTA) performance. The results underscore the effectiveness of our sequential learning approach, marking a significant advancement in the field of mathematical reasoning in LLMs.
Evalverse: Unified and Accessible Library for Large Language Model Evaluation
Apr 01, 2024
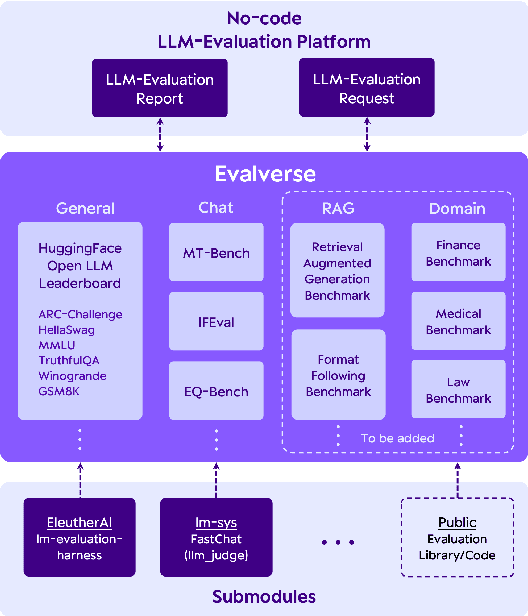
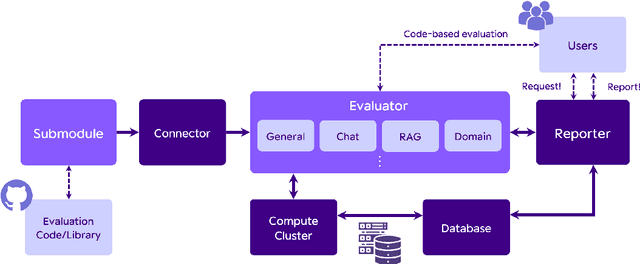
This paper introduces Evalverse, a novel library that streamlines the evaluation of Large Language Models (LLMs) by unifying disparate evaluation tools into a single, user-friendly framework. Evalverse enables individuals with limited knowledge of artificial intelligence to easily request LLM evaluations and receive detailed reports, facilitated by an integration with communication platforms like Slack. Thus, Evalverse serves as a powerful tool for the comprehensive assessment of LLMs, offering both researchers and practitioners a centralized and easily accessible evaluation framework. Finally, we also provide a demo video for Evalverse, showcasing its capabilities and implementation in a two-minute format.
SOLAR 10.7B: Scaling Large Language Models with Simple yet Effective Depth Up-Scaling
Dec 29, 2023



We introduce SOLAR 10.7B, a large language model (LLM) with 10.7 billion parameters, demonstrating superior performance in various natural language processing (NLP) tasks. Inspired by recent efforts to efficiently up-scale LLMs, we present a method for scaling LLMs called depth up-scaling (DUS), which encompasses depthwise scaling and continued pretraining. In contrast to other LLM up-scaling methods that use mixture-of-experts, DUS does not require complex changes to train and inference efficiently. We show experimentally that DUS is simple yet effective in scaling up high-performance LLMs from small ones. Building on the DUS model, we additionally present SOLAR 10.7B-Instruct, a variant fine-tuned for instruction-following capabilities, surpassing Mixtral-8x7B-Instruct. SOLAR 10.7B is publicly available under the Apache 2.0 license, promoting broad access and application in the LLM field.