 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeESPADA: Execution Speedup via Semantics Aware Demonstration Data Downsampling for Imitation Learning
Dec 15, 2025Behavior-cloning based visuomotor policies enable precise manipulation but often inherit the slow, cautious tempo of human demonstrations, limiting practical deployment. However, prior studies on acceleration methods mainly rely on statistical or heuristic cues that ignore task semantics and can fail across diverse manipulation settings. We present ESPADA, a semantic and spatially aware framework that segments demonstrations using a VLM-LLM pipeline with 3D gripper-object relations, enabling aggressive downsampling only in non-critical segments while preserving precision-critical phases, without requiring extra data or architectural modifications, or any form of retraining. To scale from a single annotated episode to the full dataset, ESPADA propagates segment labels via Dynamic Time Warping (DTW) on dynamics-only features. Across both simulation and real-world experiments with ACT and DP baselines, ESPADA achieves approximately a 2x speed-up while maintaining success rates, narrowing the gap between human demonstrations and efficient robot control.
Expanding Search Space with Diverse Prompting Agents: An Efficient Sampling Approach for LLM Mathematical Reasoning
Oct 13, 2024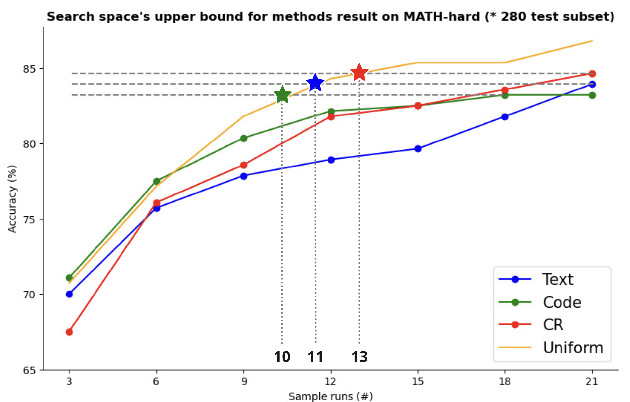
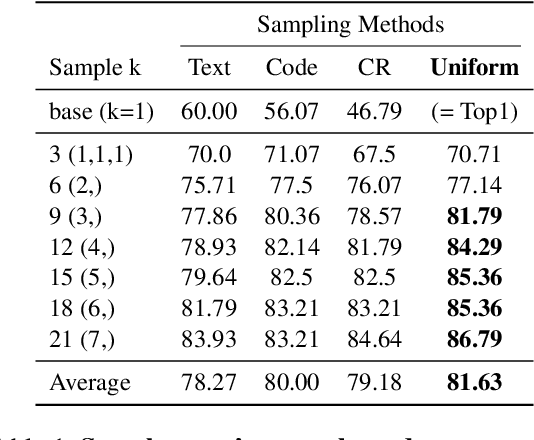
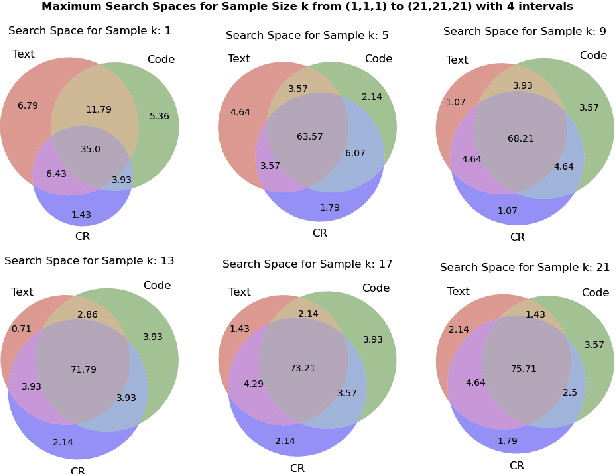
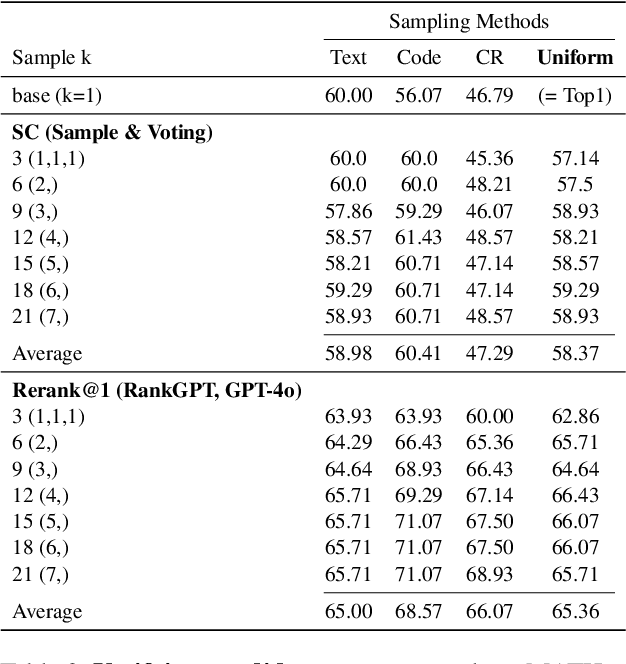
Large Language Models (LLMs) have exhibited remarkable capabilities in many complex tasks including mathematical reasoning. However, traditional approaches heavily rely on ensuring self-consistency within single prompting method, which limits the exploration of diverse problem-solving strategies. This study addresses these limitations by performing an experimental analysis of distinct prompting methods within the domain of mathematical reasoning. Our findings demonstrate that each method explores a distinct search space, and this differentiation becomes more evident with increasing problem complexity. To leverage this phenomenon, we applied efficient sampling process that uniformly combines samples from these diverse methods, which not only expands the maximum search space but achieves higher performance with fewer runs compared to single methods. Especially, within the subset of difficult questions of MATH dataset named MATH-hard, The maximum search space was achieved while utilizing approximately 43% fewer runs than single methods on average. These findings highlight the importance of integrating diverse problem-solving strategies to enhance the reasoning abilities of LLMs.
SAAS: Solving Ability Amplification Strategy for Enhanced Mathematical Reasoning in Large Language Models
Apr 08, 2024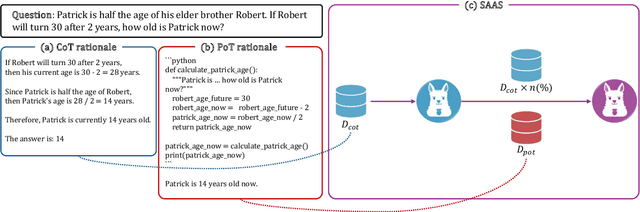
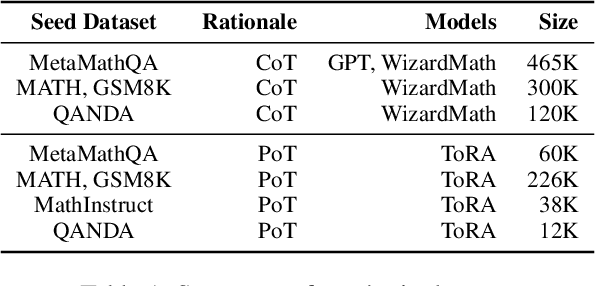

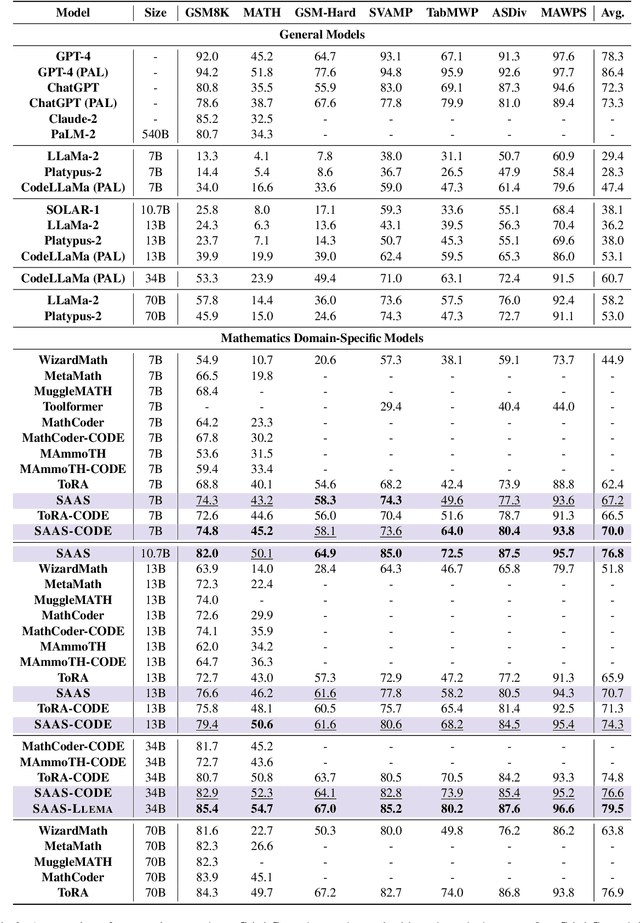
This study presents a novel learning approach designed to enhance both mathematical reasoning and problem-solving abilities of Large Language Models (LLMs). We focus on integrating the Chain-of-Thought (CoT) and the Program-of-Thought (PoT) learning, hypothesizing that prioritizing the learning of mathematical reasoning ability is helpful for the amplification of problem-solving ability. Thus, the initial learning with CoT is essential for solving challenging mathematical problems. To this end, we propose a sequential learning approach, named SAAS (Solving Ability Amplification Strategy), which strategically transitions from CoT learning to PoT learning. Our empirical study, involving an extensive performance comparison using several benchmarks, demonstrates that our SAAS achieves state-of-the-art (SOTA) performance. The results underscore the effectiveness of our sequential learning approach, marking a significant advancement in the field of mathematical reasoning in LLMs.
Highway Driving Dataset for Semantic Video Segmentation
Nov 02, 2020
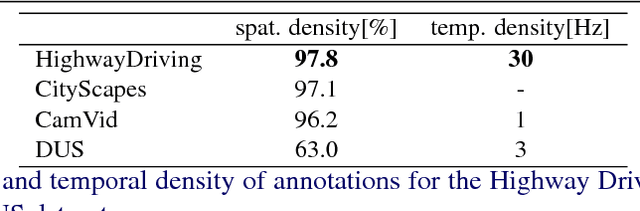
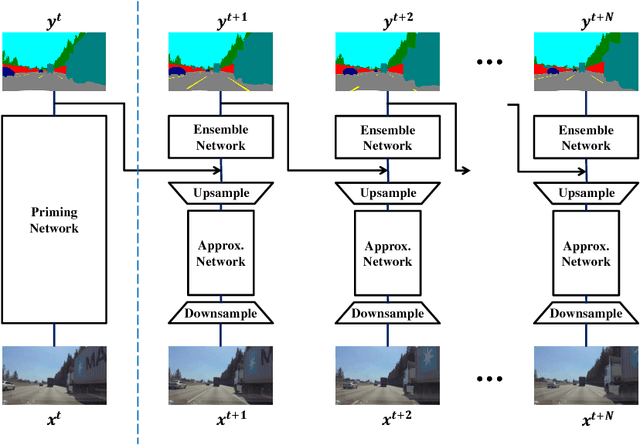
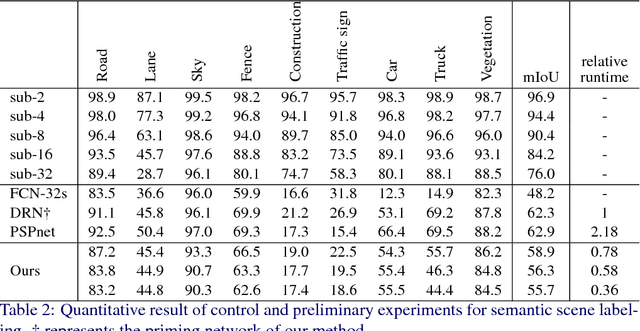
Scene understanding is an essential technique in semantic segmentation. Although there exist several datasets that can be used for semantic segmentation, they are mainly focused on semantic image segmentation with large deep neural networks. Therefore, these networks are not useful for real time applications, especially in autonomous driving systems. In order to solve this problem, we make two contributions to semantic segmentation task. The first contribution is that we introduce the semantic video dataset, the Highway Driving dataset, which is a densely annotated benchmark for a semantic video segmentation task. The Highway Driving dataset consists of 20 video sequences having a 30Hz frame rate, and every frame is densely annotated. Secondly, we propose a baseline algorithm that utilizes a temporal correlation. Together with our attempt to analyze the temporal correlation, we expect the Highway Driving dataset to encourage research on semantic video segmentation.
Collaborative Method for Incremental Learning on Classification and Generation
Oct 29, 2020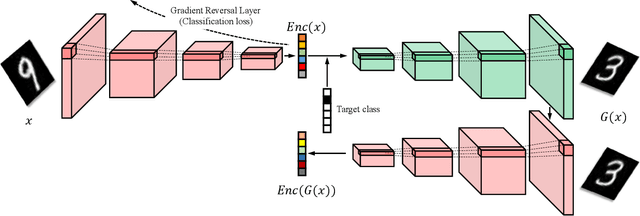

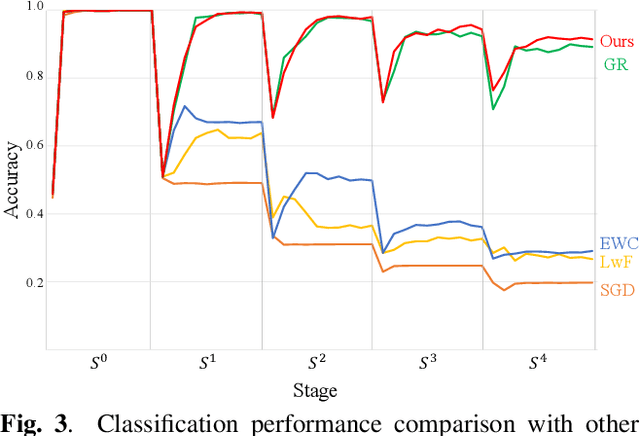
Although well-trained deep neural networks have shown remarkable performance on numerous tasks, they rapidly forget what they have learned as soon as they begin to learn with additional data with the previous data stop being provided. In this paper, we introduce a novel algorithm, Incremental Class Learning with Attribute Sharing (ICLAS), for incremental class learning with deep neural networks. As one of its component, we also introduce a generative model, incGAN, which can generate images with increased variety compared with the training data. Under challenging environment of data deficiency, ICLAS incrementally trains classification and the generation networks. Since ICLAS trains both networks, our algorithm can perform multiple times of incremental class learning. The experiments on MNIST dataset demonstrate the advantages of our algorithm.
Adjusting Decision Boundary for Class Imbalanced Learning
Dec 04, 2019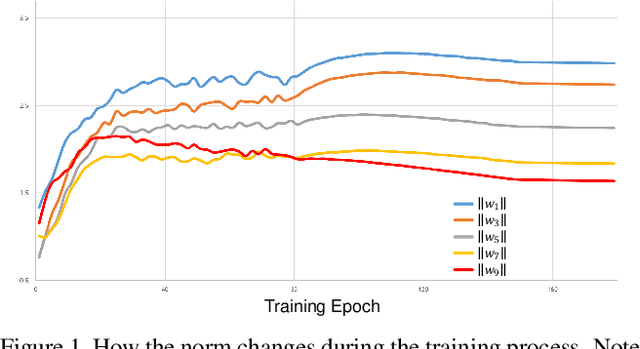
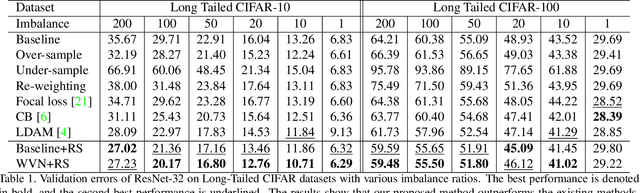
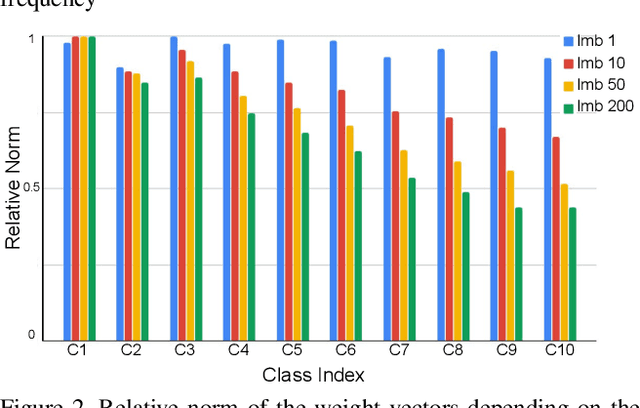
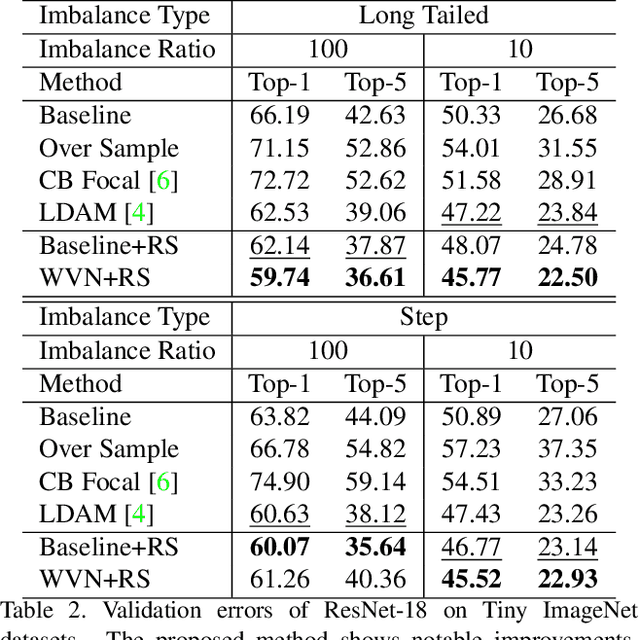
Training of deep neural networks heavily depends on the data distribution. In particular, the networks easily suffer from class imbalance. The trained networks would recognize the frequent classes better than the infrequent classes. To resolve this problem, existing approaches typically propose novel loss functions to obtain better feature embedding. In this paper, we argue that drawing a better decision boundary is as important as learning better features. Inspired by observations, we investigate how the class imbalance affects the decision boundary and deteriorates the performance. We also investigate the feature distributional discrepancy between training and test time. As a result, we propose a novel, yet simple method for class imbalanced learning. Despite its simplicity, our method shows outstanding performance. In particular, the experimental results show that we can significantly improve the network by scaling the weight vectors, even without additional training process.
Learning Not to Learn: Training Deep Neural Networks with Biased Data
Dec 26, 2018
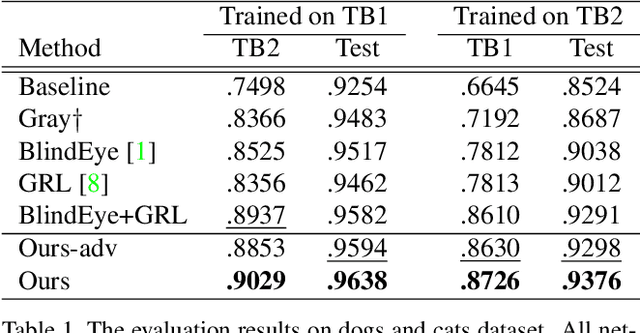
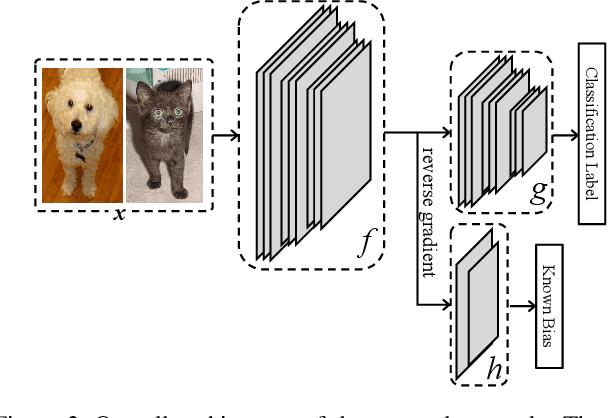
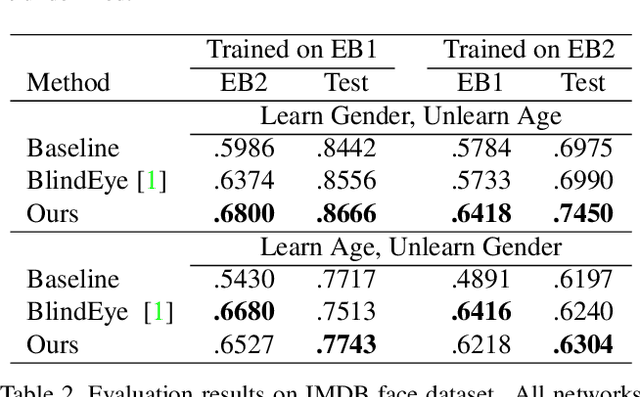
We propose a novel regularization algorithm to train deep neural networks, in which data at training time is severely biased. Since a neural network efficiently learns data distribution, a network is likely to learn the bias information to categorize input data. It leads to poor performance at test time, if the bias is, in fact, irrelevant to the categorization. In this paper, we formulate a regularization loss based on mutual information between feature embedding and bias. Based on the idea of minimizing this mutual information, we propose an iterative algorithm to unlearn the bias information. We employ an additional network to predict the bias distribution and train the network adversarially against the feature embedding network. At the end of learning, the bias prediction network is not able to predict the bias not because it is poorly trained, but because the feature embedding network successfully unlearns the bias information. We also demonstrate quantitative and qualitative experimental results which show that our algorithm effectively removes the bias information from feature embedding.
Mimicking Ensemble Learning with Deep Branched Networks
Feb 21, 2017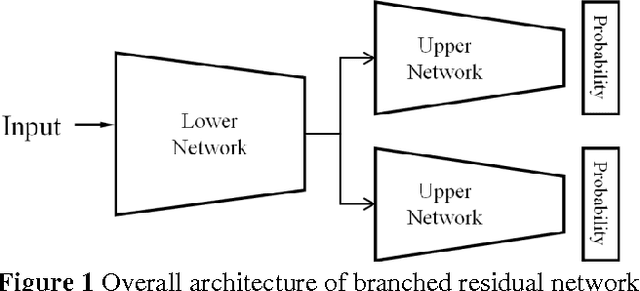

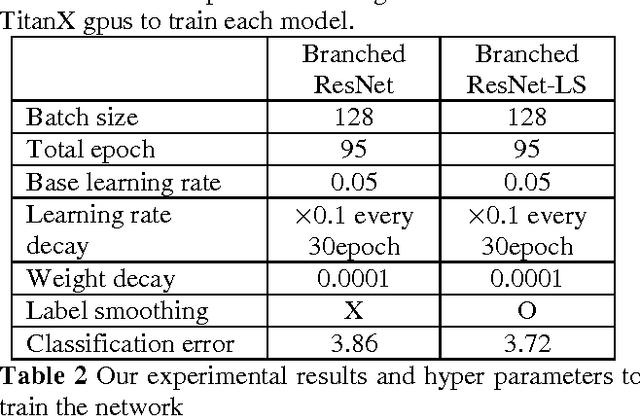
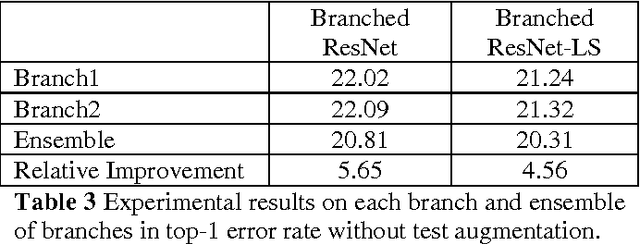
This paper proposes a branched residual network for image classification. It is known that high-level features of deep neural network are more representative than lower-level features. By sharing the low-level features, the network can allocate more memory to high-level features. The upper layers of our proposed network are branched, so that it mimics the ensemble learning. By mimicking ensemble learning with single network, we have achieved better performance on ImageNet classification task.