 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputational Synthesis of Wearable Robot Mechanisms: Application to Hip-Joint Mechanisms
Aug 21, 2023



Since wearable linkage mechanisms could control the moment transmission from actuator(s) to wearers, they can help ensure that even low-cost wearable systems provide advanced functionality tailored to users' needs. For example, if a hip mechanism transforms an input torque into a spatially-varying moment, a wearer can get effective assistance both in the sagittal and frontal planes during walking, even with an affordable single-actuator system. However, due to the combinatorial nature of the linkage mechanism design space, the topologies of such nonlinear-moment-generating mechanisms are challenging to determine, even with significant computational resources and numerical data. Furthermore, on-premise production development and interactive design are nearly impossible in conventional synthesis approaches. Here, we propose an innovative autonomous computational approach for synthesizing such wearable robot mechanisms, eliminating the need for exhaustive searches or numerous data sets. Our method transforms the synthesis problem into a gradient-based optimization problem with sophisticated objective and constraint functions while ensuring the desired degree of freedom, range of motion, and force transmission characteristics. To generate arbitrary mechanism topologies and dimensions, we employed a unified ground model. By applying the proposed method for the design of hip joint mechanisms, the topologies and dimensions of non-series-type hip joint mechanisms were obtained. Biomechanical simulations validated its multi-moment assistance capability, and its wearability was verified via prototype fabrication. The proposed design strategy can open a new way to design various wearable robot mechanisms, such as shoulders, knees, and ankles.
Rethinking Efficacy of Softmax for Lightweight Non-Local Neural Networks
Jul 27, 2022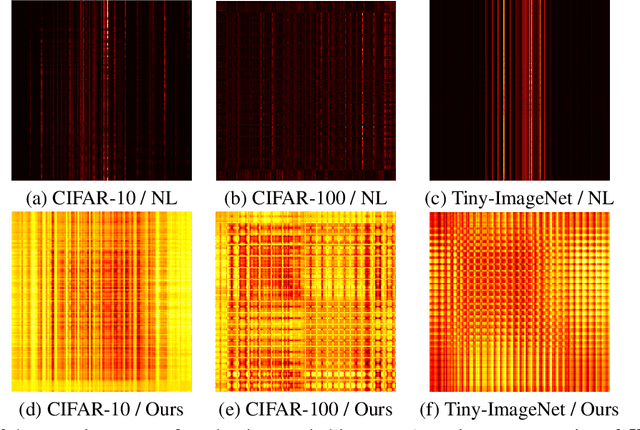
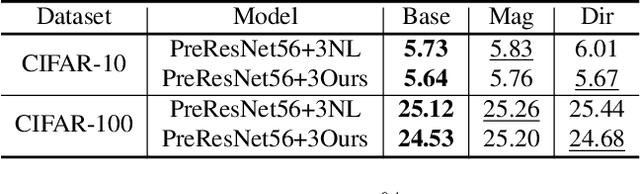
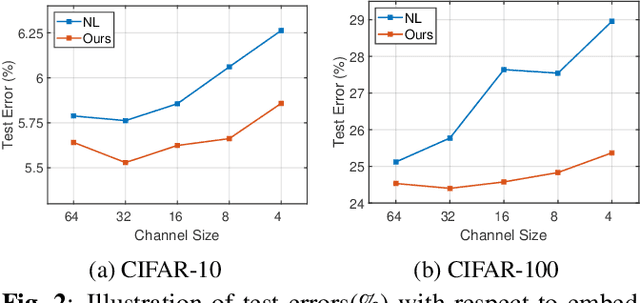
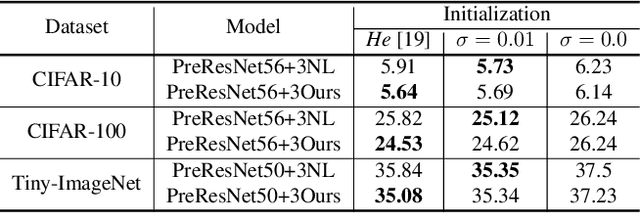
Non-local (NL) block is a popular module that demonstrates the capability to model global contexts. However, NL block generally has heavy computation and memory costs, so it is impractical to apply the block to high-resolution feature maps. In this paper, to investigate the efficacy of NL block, we empirically analyze if the magnitude and direction of input feature vectors properly affect the attention between vectors. The results show the inefficacy of softmax operation which is generally used to normalize the attention map of the NL block. Attention maps normalized with softmax operation highly rely upon magnitude of key vectors, and performance is degenerated if the magnitude information is removed. By replacing softmax operation with the scaling factor, we demonstrate improved performance on CIFAR-10, CIFAR-100, and Tiny-ImageNet. In Addition, our method shows robustness to embedding channel reduction and embedding weight initialization. Notably, our method makes multi-head attention employable without additional computational cost.
Improving Generalization of Batch Whitening by Convolutional Unit Optimization
Aug 24, 2021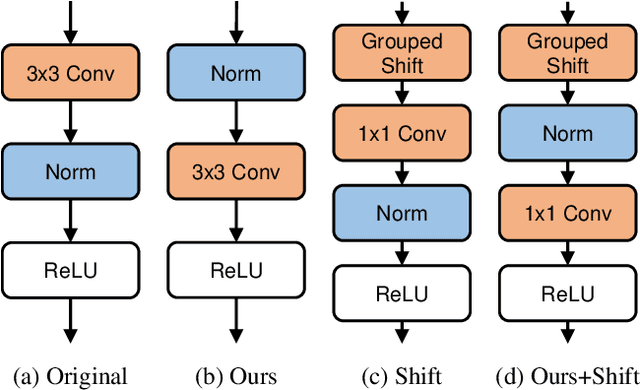
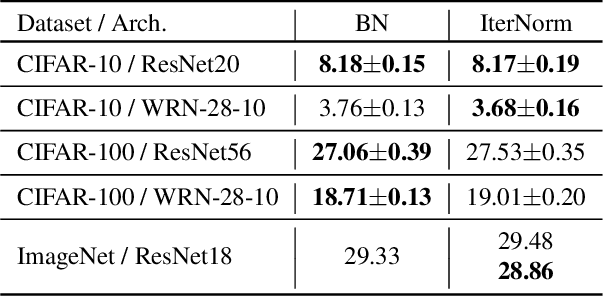
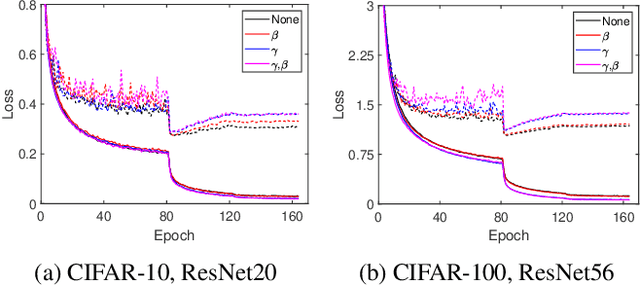
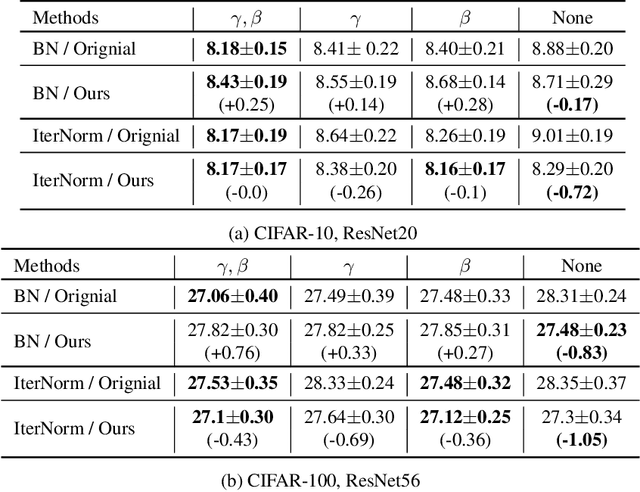
Batch Whitening is a technique that accelerates and stabilizes training by transforming input features to have a zero mean (Centering) and a unit variance (Scaling), and by removing linear correlation between channels (Decorrelation). In commonly used structures, which are empirically optimized with Batch Normalization, the normalization layer appears between convolution and activation function. Following Batch Whitening studies have employed the same structure without further analysis; even Batch Whitening was analyzed on the premise that the input of a linear layer is whitened. To bridge the gap, we propose a new Convolutional Unit that is in line with the theory, and our method generally improves the performance of Batch Whitening. Moreover, we show the inefficacy of the original Convolutional Unit by investigating rank and correlation of features. As our method is employable off-the-shelf whitening modules, we use Iterative Normalization (IterNorm), the state-of-the-art whitening module, and obtain significantly improved performance on five image classification datasets: CIFAR-10, CIFAR-100, CUB-200-2011, Stanford Dogs, and ImageNet. Notably, we verify that our method improves stability and performance of whitening when using large learning rate, group size, and iteration number.
An Ensemble Approach toward Automated Variable Selection for Network Anomaly Detection
Oct 28, 2019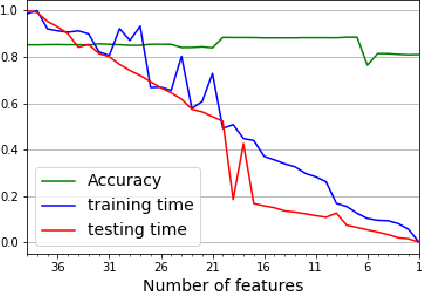
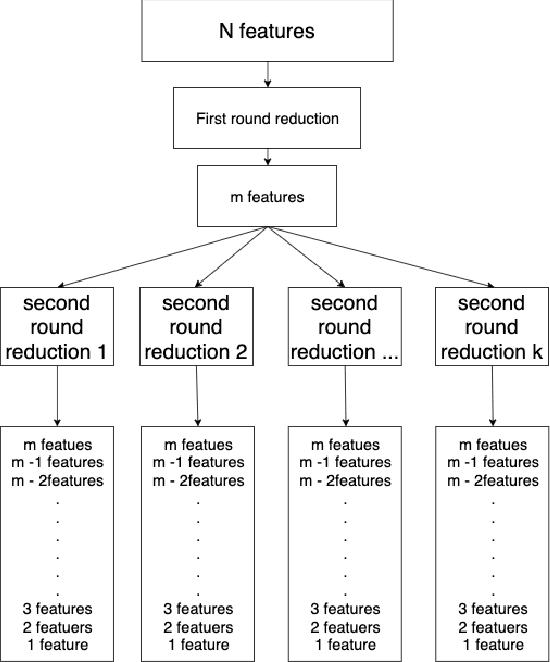
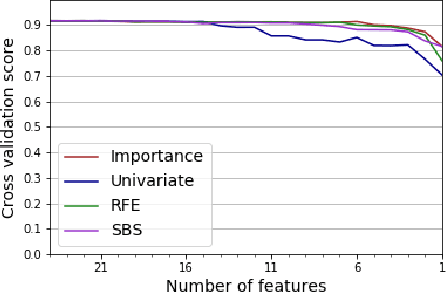
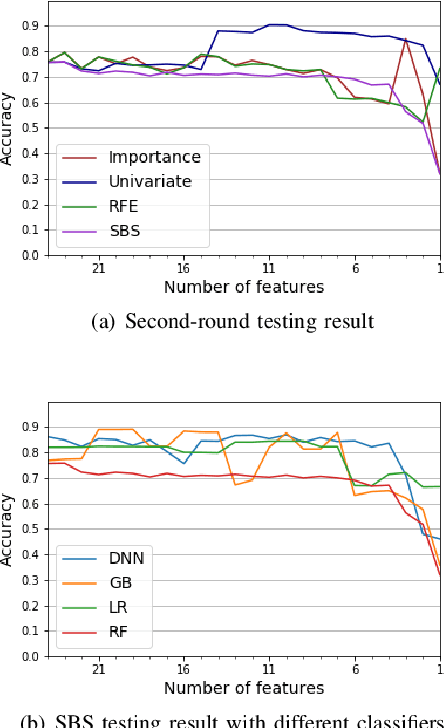
While variable selection is essential to optimize the learning complexity by prioritizing features, automating the selection process is preferred since it requires laborious efforts with intensive analysis otherwise. However, it is not an easy task to enable the automation due to several reasons. First, selection techniques often need a condition to terminate the reduction process, for example, by using a threshold or the number of features to stop, and searching an adequate stopping condition is highly challenging. Second, it is uncertain that the reduced variable set would work well; our preliminary experimental result shows that well-known selection techniques produce different sets of variables as a result of reduction (even with the same termination condition), and it is hard to estimate which of them would work the best in future testing. In this paper, we demonstrate the potential power of our approach to the automation of selection process that incorporates well-known selection methods identifying important variables. Our experimental results with two public network traffic data (UNSW-NB15 and IDS2017) show that our proposed method identifies a small number of core variables, with which it is possible to approximate the performance to the one with the entire variables.
Mimicking Ensemble Learning with Deep Branched Networks
Feb 21, 2017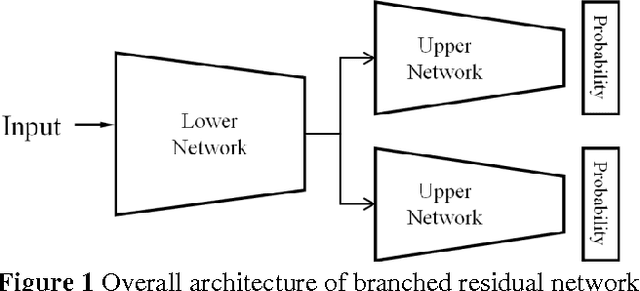

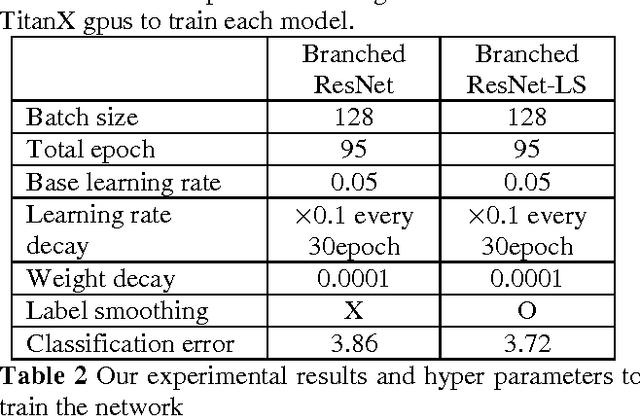
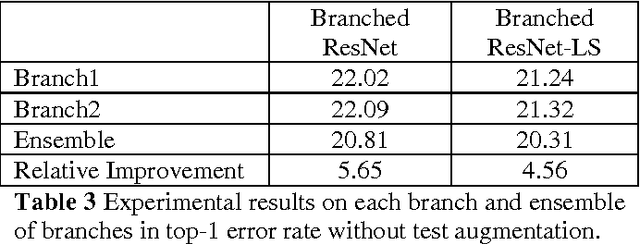
This paper proposes a branched residual network for image classification. It is known that high-level features of deep neural network are more representative than lower-level features. By sharing the low-level features, the network can allocate more memory to high-level features. The upper layers of our proposed network are branched, so that it mimics the ensemble learning. By mimicking ensemble learning with single network, we have achieved better performance on ImageNet classification task.