 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMINT: Molecularly Informed Training with Spatial Transcriptomics Supervision for Pathology Foundation Models
Mar 09, 2026Pathology foundation models learn morphological representations through self-supervised pretraining on large-scale whole-slide images, yet they do not explicitly capture the underlying molecular state of the tissue. Spatial transcriptomics technologies bridge this gap by measuring gene expression in situ, offering a natural cross-modal supervisory signal. We propose MINT (Molecularly Informed Training), a fine-tuning framework that incorporates spatial transcriptomics supervision into pretrained pathology Vision Transformers. MINT appends a learnable ST token to the ViT input to encode transcriptomic information separately from the morphological CLS token, preventing catastrophic forgetting through DINO self-distillation and explicit feature anchoring to the frozen pretrained encoder. Gene expression regression at both spot-level (Visium) and patch-level (Xenium) resolutions provides complementary supervision across spatial scales. Trained on 577 publicly available HEST samples, MINT achieves the best overall performance on both HEST-Bench for gene expression prediction (mean Pearson r = 0.440) and EVA for general pathology tasks (0.803), demonstrating that spatial transcriptomics supervision complements morphology-centric self-supervised pretraining.
EXAONE Path 2.5: Pathology Foundation Model with Multi-Omics Alignment
Dec 16, 2025Cancer progression arises from interactions across multiple biological layers, especially beyond morphological and across molecular layers that remain invisible to image-only models. To capture this broader biological landscape, we present EXAONE Path 2.5, a pathology foundation model that jointly models histologic, genomic, epigenetic and transcriptomic modalities, producing an integrated patient representation that reflects tumor biology more comprehensively. Our approach incorporates three key components: (1) multimodal SigLIP loss enabling all-pairwise contrastive learning across heterogeneous modalities, (2) a fragment-aware rotary positional encoding (F-RoPE) module that preserves spatial structure and tissue-fragment topology in WSI, and (3) domain-specialized internal foundation models for both WSI and RNA-seq to provide biologically grounded embeddings for robust multimodal alignment. We evaluate EXAONE Path 2.5 against six leading pathology foundation models across two complementary benchmarks: an internal real-world clinical dataset and the Patho-Bench benchmark covering 80 tasks. Our framework demonstrates high data and parameter efficiency, achieving on-par performance with state-of-the-art foundation models on Patho-Bench while exhibiting the highest adaptability in the internal clinical setting. These results highlight the value of biologically informed multimodal design and underscore the potential of integrated genotype-to-phenotype modeling for next-generation precision oncology.
EXAONE Path 2.0: Pathology Foundation Model with End-to-End Supervision
Jul 09, 2025In digital pathology, whole-slide images (WSIs) are often difficult to handle due to their gigapixel scale, so most approaches train patch encoders via self-supervised learning (SSL) and then aggregate the patch-level embeddings via multiple instance learning (MIL) or slide encoders for downstream tasks. However, patch-level SSL may overlook complex domain-specific features that are essential for biomarker prediction, such as mutation status and molecular characteristics, as SSL methods rely only on basic augmentations selected for natural image domains on small patch-level area. Moreover, SSL methods remain less data efficient than fully supervised approaches, requiring extensive computational resources and datasets to achieve competitive performance. To address these limitations, we present EXAONE Path 2.0, a pathology foundation model that learns patch-level representations under direct slide-level supervision. Using only 37k WSIs for training, EXAONE Path 2.0 achieves state-of-the-art average performance across 10 biomarker prediction tasks, demonstrating remarkable data efficiency.
Large Étendue 3D Holographic Display with Content-adpative Dynamic Fourier Modulation
Sep 05, 2024Emerging holographic display technology offers unique capabilities for next-generation virtual reality systems. Current holographic near-eye displays, however, only support a small \'etendue, which results in a direct tradeoff between achievable field of view and eyebox size. \'Etendue expansion has recently been explored, but existing approaches are either fundamentally limited in the image quality that can be achieved or they require extremely high-speed spatial light modulators. We describe a new \'etendue expansion approach that combines multiple coherent sources with content-adaptive amplitude modulation of the hologram spectrum in the Fourier plane. To generate time-multiplexed phase and amplitude patterns for our spatial light modulators, we devise a pupil-aware gradient-descent-based computer-generated holography algorithm that is supervised by a large-baseline target light field. Compared with relevant baseline approaches, our method demonstrates significant improvements in image quality and \'etendue in simulation and with an experimental holographic display prototype.
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
Mesh Represented Recycle Learning for 3D Hand Pose and Mesh Estimation
Oct 18, 2023



In general, hand pose estimation aims to improve the robustness of model performance in the real-world scenes. However, it is difficult to enhance the robustness since existing datasets are obtained in restricted environments to annotate 3D information. Although neural networks quantitatively achieve a high estimation accuracy, unsatisfied results can be observed in visual quality. This discrepancy between quantitative results and their visual qualities remains an open issue in the hand pose representation. To this end, we propose a mesh represented recycle learning strategy for 3D hand pose and mesh estimation which reinforces synthesized hand mesh representation in a training phase. To be specific, a hand pose and mesh estimation model first predicts parametric 3D hand annotations (i.e., 3D keypoint positions and vertices for hand mesh) with real-world hand images in the training phase. Second, synthetic hand images are generated with self-estimated hand mesh representations. After that, the synthetic hand images are fed into the same model again. Thus, the proposed learning strategy simultaneously improves quantitative results and visual qualities by reinforcing synthetic mesh representation. To encourage consistency between original model output and its recycled one, we propose self-correlation loss which maximizes the accuracy and reliability of our learning strategy. Consequently, the model effectively conducts self-refinement on hand pose estimation by learning mesh representation from its own output. To demonstrate the effectiveness of our learning strategy, we provide extensive experiments on FreiHAND dataset. Notably, our learning strategy improves the performance on hand pose and mesh estimation without any extra computational burden during the inference.
Referenceless User Controllable Semantic Image Synthesis
Jun 18, 2023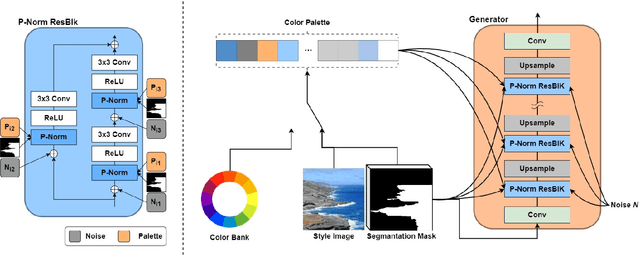
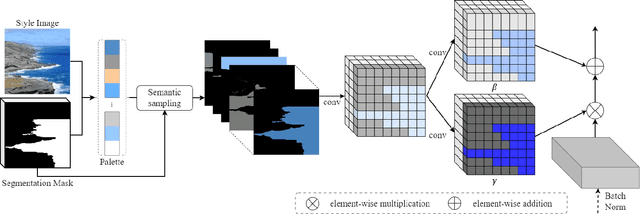


Despite recent progress in semantic image synthesis, complete control over image style remains a challenging problem. Existing methods require reference images to feed style information into semantic layouts, which indicates that the style is constrained by the given image. In this paper, we propose a model named RUCGAN for user controllable semantic image synthesis, which utilizes a singular color to represent the style of a specific semantic region. The proposed network achieves reference-free semantic image synthesis by injecting color as user-desired styles into each semantic layout, and is able to synthesize semantic images with unusual colors. Extensive experimental results on various challenging datasets show that the proposed method outperforms existing methods, and we further provide an interactive UI to demonstrate the advantage of our approach for style controllability.
Hybrid model for Single-Stage Multi-Person Pose Estimation
May 02, 2023



In general, human pose estimation methods are categorized into two approaches according to their architectures: regression (i.e., heatmap-free) and heatmap-based methods. The former one directly estimates precise coordinates of each keypoint using convolutional and fully-connected layers. Although this approach is able to detect overlapped and dense keypoints, unexpected results can be obtained by non-existent keypoints in a scene. On the other hand, the latter one is able to filter the non-existent ones out by utilizing predicted heatmaps for each keypoint. Nevertheless, it suffers from quantization error when obtaining the keypoint coordinates from its heatmaps. In addition, unlike the regression one, it is difficult to distinguish densely placed keypoints in an image. To this end, we propose a hybrid model for single-stage multi-person pose estimation, named HybridPose, which mutually overcomes each drawback of both approaches by maximizing their strengths. Furthermore, we introduce self-correlation loss to inject spatial dependencies between keypoint coordinates and their visibility. Therefore, HybridPose is capable of not only detecting densely placed keypoints, but also filtering the non-existent keypoints in an image. Experimental results demonstrate that proposed HybridPose exhibits the keypoints visibility without performance degradation in terms of the pose estimation accuracy.
BigColor: Colorization using a Generative Color Prior for Natural Images
Jul 20, 2022
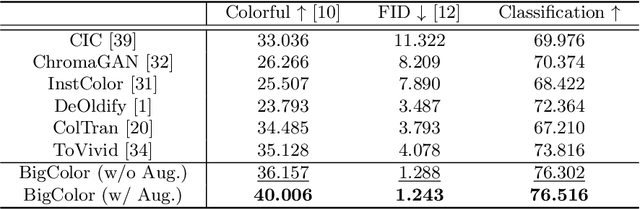
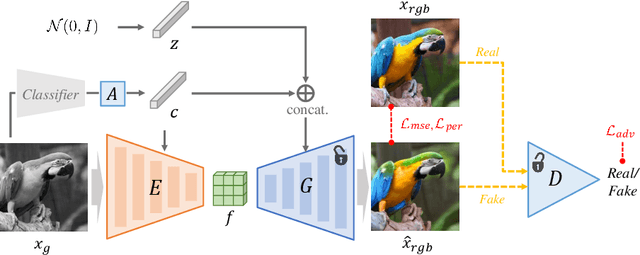
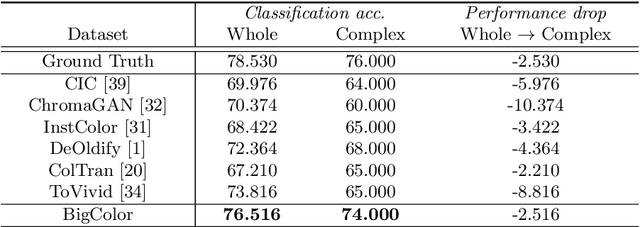
For realistic and vivid colorization, generative priors have recently been exploited. However, such generative priors often fail for in-the-wild complex images due to their limited representation space. In this paper, we propose BigColor, a novel colorization approach that provides vivid colorization for diverse in-the-wild images with complex structures. While previous generative priors are trained to synthesize both image structures and colors, we learn a generative color prior to focus on color synthesis given the spatial structure of an image. In this way, we reduce the burden of synthesizing image structures from the generative prior and expand its representation space to cover diverse images. To this end, we propose a BigGAN-inspired encoder-generator network that uses a spatial feature map instead of a spatially-flattened BigGAN latent code, resulting in an enlarged representation space. Our method enables robust colorization for diverse inputs in a single forward pass, supports arbitrary input resolutions, and provides multi-modal colorization results. We demonstrate that BigColor significantly outperforms existing methods especially on in-the-wild images with complex structures.
Time-multiplexed Neural Holography: A flexible framework for holographic near-eye displays with fast heavily-quantized spatial light modulators
May 05, 2022
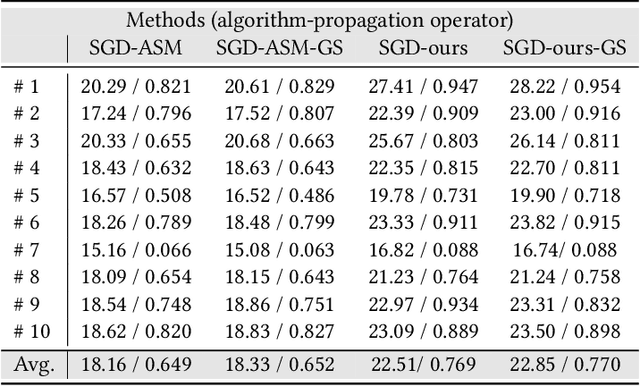

Holographic near-eye displays offer unprecedented capabilities for virtual and augmented reality systems, including perceptually important focus cues. Although artificial intelligence--driven algorithms for computer-generated holography (CGH) have recently made much progress in improving the image quality and synthesis efficiency of holograms, these algorithms are not directly applicable to emerging phase-only spatial light modulators (SLM) that are extremely fast but offer phase control with very limited precision. The speed of these SLMs offers time multiplexing capabilities, essentially enabling partially-coherent holographic display modes. Here we report advances in camera-calibrated wave propagation models for these types of holographic near-eye displays and we develop a CGH framework that robustly optimizes the heavily quantized phase patterns of fast SLMs. Our framework is flexible in supporting runtime supervision with different types of content, including 2D and 2.5D RGBD images, 3D focal stacks, and 4D light fields. Using our framework, we demonstrate state-of-the-art results for all of these scenarios in simulation and experiment.