 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePCEvE: Part Contribution Evaluation Based Model Explanation for Human Figure Drawing Assessment and Beyond
Sep 26, 2024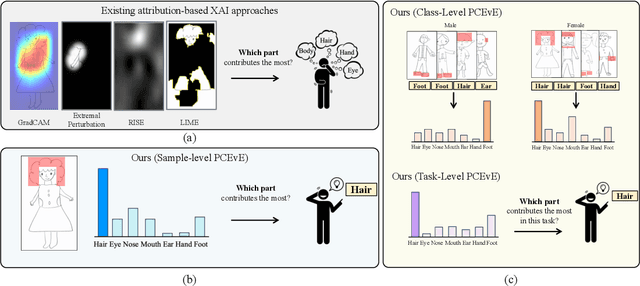
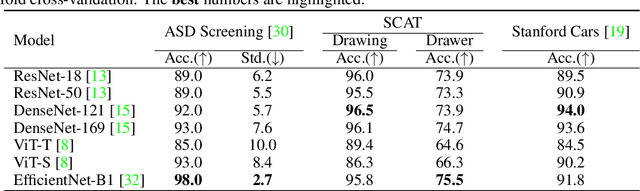
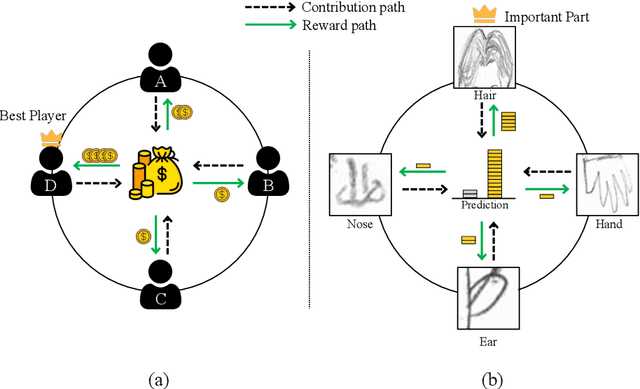
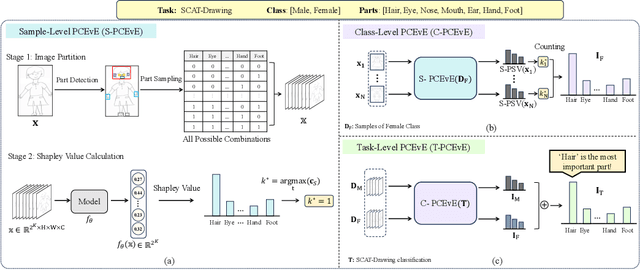
For automatic human figure drawing (HFD) assessment tasks, such as diagnosing autism spectrum disorder (ASD) using HFD images, the clarity and explainability of a model decision are crucial. Existing pixel-level attribution-based explainable AI (XAI) approaches demand considerable effort from users to interpret the semantic information of a region in an image, which can be often time-consuming and impractical. To overcome this challenge, we propose a part contribution evaluation based model explanation (PCEvE) framework. On top of the part detection, we measure the Shapley Value of each individual part to evaluate the contribution to a model decision. Unlike existing attribution-based XAI approaches, the PCEvE provides a straightforward explanation of a model decision, i.e., a part contribution histogram. Furthermore, the PCEvE expands the scope of explanations beyond the conventional sample-level to include class-level and task-level insights, offering a richer, more comprehensive understanding of model behavior. We rigorously validate the PCEvE via extensive experiments on multiple HFD assessment datasets. Also, we sanity-check the proposed method with a set of controlled experiments. Additionally, we demonstrate the versatility and applicability of our method to other domains by applying it to a photo-realistic dataset, the Stanford Cars.
Feature Reduction Method Comparison Towards Explainability and Efficiency in Cybersecurity Intrusion Detection Systems
Mar 22, 2023In the realm of cybersecurity, intrusion detection systems (IDS) detect and prevent attacks based on collected computer and network data. In recent research, IDS models have been constructed using machine learning (ML) and deep learning (DL) methods such as Random Forest (RF) and deep neural networks (DNN). Feature selection (FS) can be used to construct faster, more interpretable, and more accurate models. We look at three different FS techniques; RF information gain (RF-IG), correlation feature selection using the Bat Algorithm (CFS-BA), and CFS using the Aquila Optimizer (CFS-AO). Our results show CFS-BA to be the most efficient of the FS methods, building in 55% of the time of the best RF-IG model while achieving 99.99% of its accuracy. This reinforces prior contributions attesting to CFS-BA's accuracy while building upon the relationship between subset size, CFS score, and RF-IG score in final results.
* Published in 2022 21st IEEE International Conference on Machine Learning and Applications. 8 pages. 5 figures
DynaGAN: Dynamic Few-shot Adaptation of GANs to Multiple Domains
Nov 26, 2022Few-shot domain adaptation to multiple domains aims to learn a complex image distribution across multiple domains from a few training images. A na\"ive solution here is to train a separate model for each domain using few-shot domain adaptation methods. Unfortunately, this approach mandates linearly-scaled computational resources both in memory and computation time and, more importantly, such separate models cannot exploit the shared knowledge between target domains. In this paper, we propose DynaGAN, a novel few-shot domain-adaptation method for multiple target domains. DynaGAN has an adaptation module, which is a hyper-network that dynamically adapts a pretrained GAN model into the multiple target domains. Hence, we can fully exploit the shared knowledge across target domains and avoid the linearly-scaled computational requirements. As it is still computationally challenging to adapt a large-size GAN model, we design our adaptation module light-weight using the rank-1 tensor decomposition. Lastly, we propose a contrastive-adaptation loss suitable for multi-domain few-shot adaptation. We validate the effectiveness of our method through extensive qualitative and quantitative evaluations.
BigColor: Colorization using a Generative Color Prior for Natural Images
Jul 20, 2022
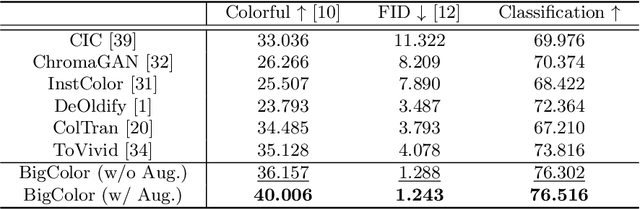
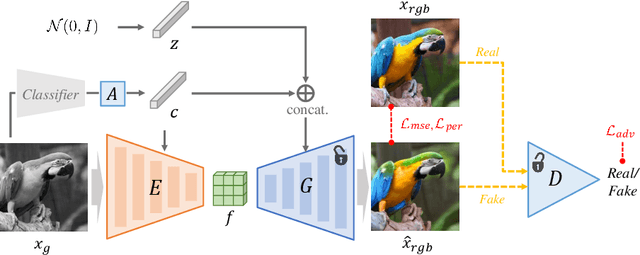
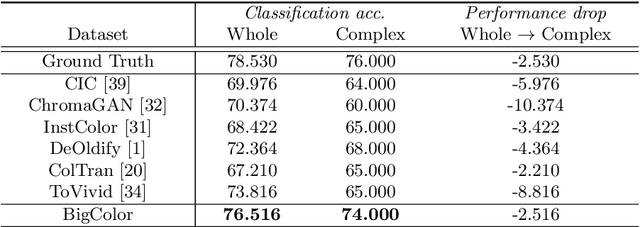
For realistic and vivid colorization, generative priors have recently been exploited. However, such generative priors often fail for in-the-wild complex images due to their limited representation space. In this paper, we propose BigColor, a novel colorization approach that provides vivid colorization for diverse in-the-wild images with complex structures. While previous generative priors are trained to synthesize both image structures and colors, we learn a generative color prior to focus on color synthesis given the spatial structure of an image. In this way, we reduce the burden of synthesizing image structures from the generative prior and expand its representation space to cover diverse images. To this end, we propose a BigGAN-inspired encoder-generator network that uses a spatial feature map instead of a spatially-flattened BigGAN latent code, resulting in an enlarged representation space. Our method enables robust colorization for diverse inputs in a single forward pass, supports arbitrary input resolutions, and provides multi-modal colorization results. We demonstrate that BigColor significantly outperforms existing methods especially on in-the-wild images with complex structures.
GAN Inversion for Out-of-Range Images with Geometric Transformations
Aug 20, 2021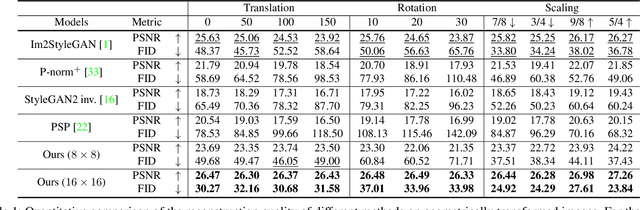
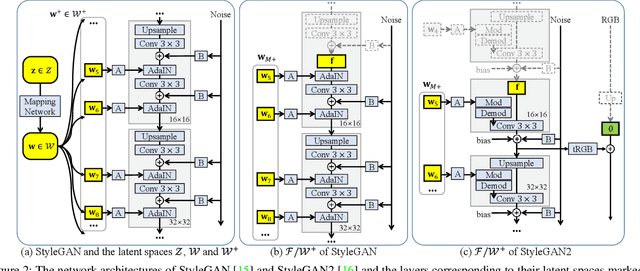
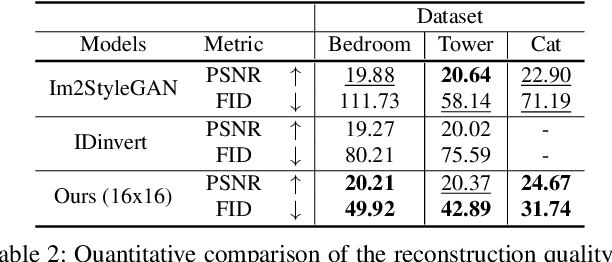

For successful semantic editing of real images, it is critical for a GAN inversion method to find an in-domain latent code that aligns with the domain of a pre-trained GAN model. Unfortunately, such in-domain latent codes can be found only for in-range images that align with the training images of a GAN model. In this paper, we propose BDInvert, a novel GAN inversion approach to semantic editing of out-of-range images that are geometrically unaligned with the training images of a GAN model. To find a latent code that is semantically editable, BDInvert inverts an input out-of-range image into an alternative latent space than the original latent space. We also propose a regularized inversion method to find a solution that supports semantic editing in the alternative space. Our experiments show that BDInvert effectively supports semantic editing of out-of-range images with geometric transformations.