 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayeringDiff: Layered Image Synthesis via Generation, then Disassembly with Generative Knowledge
Jan 02, 2025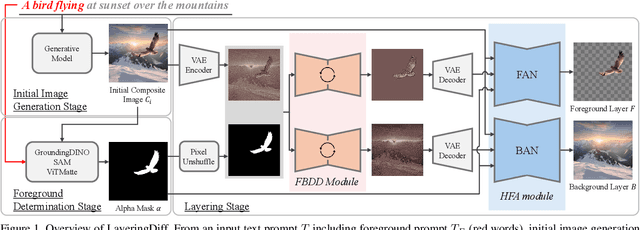

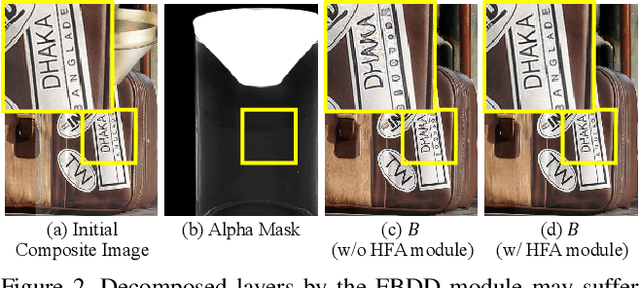

Layers have become indispensable tools for professional artists, allowing them to build a hierarchical structure that enables independent control over individual visual elements. In this paper, we propose LayeringDiff, a novel pipeline for the synthesis of layered images, which begins by generating a composite image using an off-the-shelf image generative model, followed by disassembling the image into its constituent foreground and background layers. By extracting layers from a composite image, rather than generating them from scratch, LayeringDiff bypasses the need for large-scale training to develop generative capabilities for individual layers. Furthermore, by utilizing a pretrained off-the-shelf generative model, our method can produce diverse contents and object scales in synthesized layers. For effective layer decomposition, we adapt a large-scale pretrained generative prior to estimate foreground and background layers. We also propose high-frequency alignment modules to refine the fine-details of the estimated layers. Our comprehensive experiments demonstrate that our approach effectively synthesizes layered images and supports various practical applications.
CLIPtone: Unsupervised Learning for Text-based Image Tone Adjustment
Apr 01, 2024Recent image tone adjustment (or enhancement) approaches have predominantly adopted supervised learning for learning human-centric perceptual assessment. However, these approaches are constrained by intrinsic challenges of supervised learning. Primarily, the requirement for expertly-curated or retouched images escalates the data acquisition expenses. Moreover, their coverage of target style is confined to stylistic variants inferred from the training data. To surmount the above challenges, we propose an unsupervised learning-based approach for text-based image tone adjustment method, CLIPtone, that extends an existing image enhancement method to accommodate natural language descriptions. Specifically, we design a hyper-network to adaptively modulate the pretrained parameters of the backbone model based on text description. To assess whether the adjusted image aligns with the text description without ground truth image, we utilize CLIP, which is trained on a vast set of language-image pairs and thus encompasses knowledge of human perception. The major advantages of our approach are three fold: (i) minimal data collection expenses, (ii) support for a range of adjustments, and (iii) the ability to handle novel text descriptions unseen in training. Our approach's efficacy is demonstrated through comprehensive experiments, including a user study.
UGPNet: Universal Generative Prior for Image Restoration
Dec 31, 2023



Recent image restoration methods can be broadly categorized into two classes: (1) regression methods that recover the rough structure of the original image without synthesizing high-frequency details and (2) generative methods that synthesize perceptually-realistic high-frequency details even though the resulting image deviates from the original structure of the input. While both directions have been extensively studied in isolation, merging their benefits with a single framework has been rarely studied. In this paper, we propose UGPNet, a universal image restoration framework that can effectively achieve the benefits of both approaches by simply adopting a pair of an existing regression model and a generative model. UGPNet first restores the image structure of a degraded input using a regression model and synthesizes a perceptually-realistic image with a generative model on top of the regressed output. UGPNet then combines the regressed output and the synthesized output, resulting in a final result that faithfully reconstructs the structure of the original image in addition to perceptually-realistic textures. Our extensive experiments on deblurring, denoising, and super-resolution demonstrate that UGPNet can successfully exploit both regression and generative methods for high-fidelity image restoration.
DynaGAN: Dynamic Few-shot Adaptation of GANs to Multiple Domains
Nov 26, 2022Few-shot domain adaptation to multiple domains aims to learn a complex image distribution across multiple domains from a few training images. A na\"ive solution here is to train a separate model for each domain using few-shot domain adaptation methods. Unfortunately, this approach mandates linearly-scaled computational resources both in memory and computation time and, more importantly, such separate models cannot exploit the shared knowledge between target domains. In this paper, we propose DynaGAN, a novel few-shot domain-adaptation method for multiple target domains. DynaGAN has an adaptation module, which is a hyper-network that dynamically adapts a pretrained GAN model into the multiple target domains. Hence, we can fully exploit the shared knowledge across target domains and avoid the linearly-scaled computational requirements. As it is still computationally challenging to adapt a large-size GAN model, we design our adaptation module light-weight using the rank-1 tensor decomposition. Lastly, we propose a contrastive-adaptation loss suitable for multi-domain few-shot adaptation. We validate the effectiveness of our method through extensive qualitative and quantitative evaluations.
BigColor: Colorization using a Generative Color Prior for Natural Images
Jul 20, 2022
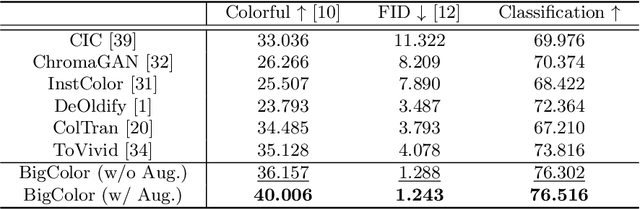
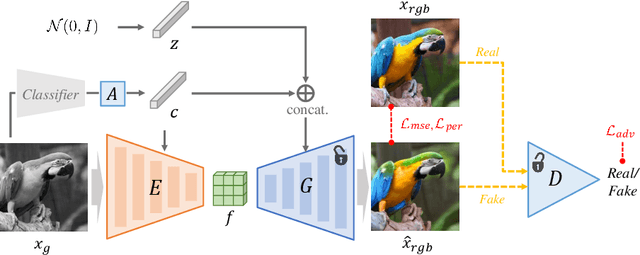
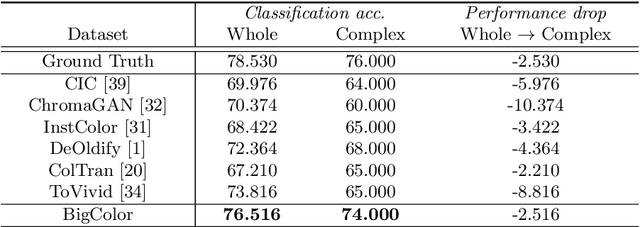
For realistic and vivid colorization, generative priors have recently been exploited. However, such generative priors often fail for in-the-wild complex images due to their limited representation space. In this paper, we propose BigColor, a novel colorization approach that provides vivid colorization for diverse in-the-wild images with complex structures. While previous generative priors are trained to synthesize both image structures and colors, we learn a generative color prior to focus on color synthesis given the spatial structure of an image. In this way, we reduce the burden of synthesizing image structures from the generative prior and expand its representation space to cover diverse images. To this end, we propose a BigGAN-inspired encoder-generator network that uses a spatial feature map instead of a spatially-flattened BigGAN latent code, resulting in an enlarged representation space. Our method enables robust colorization for diverse inputs in a single forward pass, supports arbitrary input resolutions, and provides multi-modal colorization results. We demonstrate that BigColor significantly outperforms existing methods especially on in-the-wild images with complex structures.
GAN Inversion for Out-of-Range Images with Geometric Transformations
Aug 20, 2021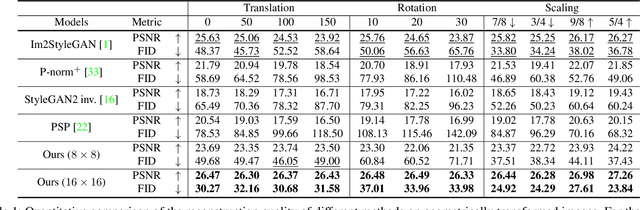
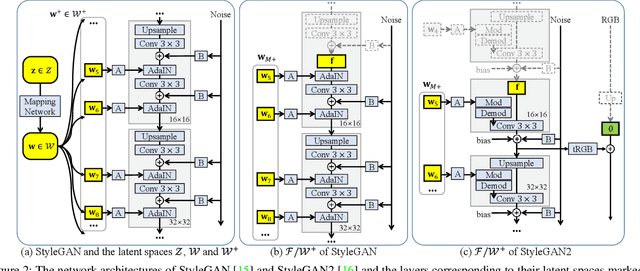
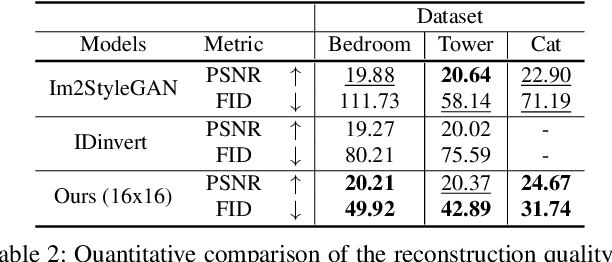

For successful semantic editing of real images, it is critical for a GAN inversion method to find an in-domain latent code that aligns with the domain of a pre-trained GAN model. Unfortunately, such in-domain latent codes can be found only for in-range images that align with the training images of a GAN model. In this paper, we propose BDInvert, a novel GAN inversion approach to semantic editing of out-of-range images that are geometrically unaligned with the training images of a GAN model. To find a latent code that is semantically editable, BDInvert inverts an input out-of-range image into an alternative latent space than the original latent space. We also propose a regularized inversion method to find a solution that supports semantic editing in the alternative space. Our experiments show that BDInvert effectively supports semantic editing of out-of-range images with geometric transformations.